serverless rag ynetnews bedrock demo
1.0.0
La respuesta a preguntas (QA) es una tarea importante que implica extraer respuestas a consultas fácticas planteadas en lenguaje natural. Normalmente, un sistema de control de calidad procesa una consulta en una base de conocimiento que contiene datos estructurados o no estructurados y genera una respuesta con información precisa. Garantizar una alta precisión es clave para desarrollar un sistema de respuesta a preguntas útil, fiable y digno de confianza, especialmente para casos de uso empresarial.
Los modelos de IA generativa como Amazon Titan, Anthropic Claude y AI21 Jurassic 2 utilizan distribuciones de probabilidad para generar respuestas a preguntas. Estos modelos se entrenan con grandes cantidades de datos de texto, lo que les permite predecir lo que sigue en una secuencia o qué palabra podría seguir a una palabra en particular. Sin embargo, estos modelos no pueden proporcionar respuestas precisas o deterministas a todas las preguntas porque siempre hay cierto grado de incertidumbre en los datos.
Las empresas necesitan consultar datos propietarios y específicos del dominio y utilizar la información para responder preguntas y, en general, datos sobre los cuales el modelo no ha sido entrenado.
En este repositorio exploraremos el siguiente patrón de control de calidad:
Usamos recuperación de generación aumentada, que mejora la primera, donde concatenamos nuestras preguntas con el mayor contexto relevante posible, que probablemente contenga las respuestas o la información que estamos buscando. El desafío aquí es que hay un límite en la cantidad de información contextual que se puede utilizar y está determinado por el límite simbólico del modelo. 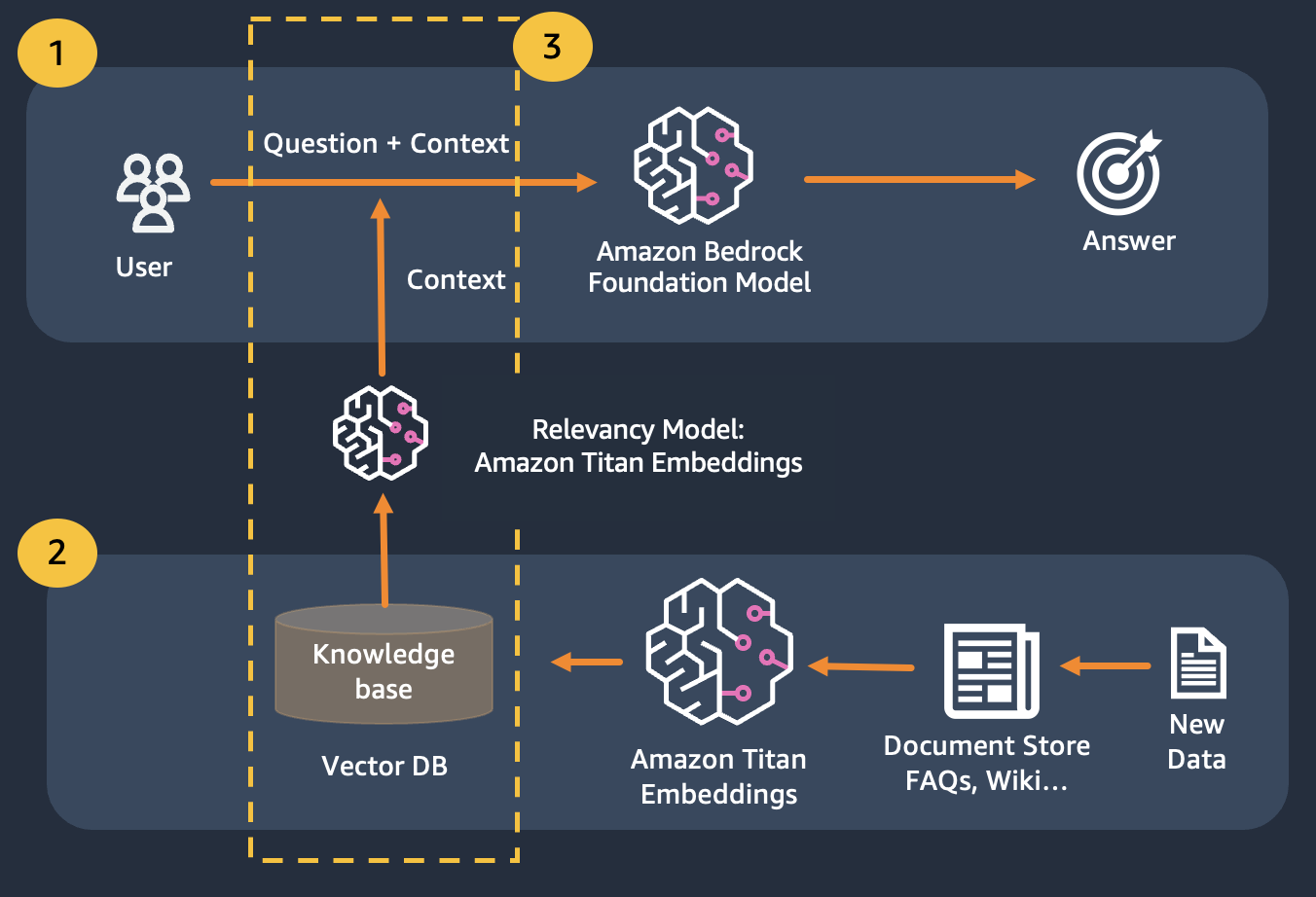
Esto se puede superar mediante el uso de generación aumentada de recuperación (RAG)
RAG combina el uso de incrustaciones para indexar el corpus de documentos para construir una base de conocimientos y el uso de un LLM para extraer la información de un subconjunto de documentos en la base de conocimientos.
Como paso de preparación para RAG, los documentos que constituyen la base de conocimientos se dividen en fragmentos de un tamaño fijo (que coinciden con el tamaño de entrada máximo del modelo de incrustación seleccionado) y luego se pasan al modelo para obtener el vector de incrustación. La incrustación junto con la parte original del documento y los metadatos adicionales se almacenan en una base de datos vectorial. La base de datos de vectores está optimizada para realizar de manera eficiente una búsqueda de similitud entre vectores.
Clientes con almacenes de datos que pueden ser privados o cambiar con frecuencia. El enfoque RAG resuelve 2 problemas; los clientes que tengan los siguientes desafíos pueden beneficiarse de este laboratorio.
Después de este módulo, debería tener una buena comprensión de:
En este módulo, le explicaremos cómo implementar el patrón de control de calidad con Bedrock. Además, hemos preparado para usted las incrustaciones que se cargarán en la base de datos de vectores.
Tenga en cuenta que puede usar Titan Embeddings para obtener las incrustaciones de la pregunta del usuario, luego usar esas incrustaciones para recuperar los documentos más relevantes de la base de datos vectorial, crear un mensaje que concatene los 3 documentos principales e invocar el modelo LLM a través de Bedrock.


