CoPilot
v0.9.0
21/08/2024: CoPilot ya está disponible en la versión 0.9 (v0.9.0). Consulte las Notas de la versión para obtener más detalles. Nota: En TigerGraph Cloud solo está disponible CoPilot v0.5.
30/04/2024: CoPilot ya está disponible en Beta (v0.5.0). Se agrega una función completamente nueva a CoPilot: ahora puede crear chatbots con IA aumentada con gráficos en sus propios documentos. CoPilot crea un gráfico de conocimiento a partir del material fuente y aplica el gráfico de conocimiento RAG (Generación Aumentada de Recuperación) para mejorar la relevancia contextual y la precisión de las respuestas a sus preguntas en lenguaje natural. Nos encantaría escuchar sus comentarios para seguir mejorándolos y que puedan aportarle más valor. Sería útil que pudieras completar esta breve encuesta después de haber jugado con CoPilot. ¡Gracias por su interés y apoyo!
18/03/2024: CoPilot ya está disponible en Alpha (v0.0.1). Utiliza un modelo de lenguaje grande (LLM) para convertir su pregunta en una llamada de función, que luego se ejecuta en el gráfico en TigerGraph. Nos encantaría escuchar sus comentarios para seguir mejorándolos y que puedan aportarle más valor. Si lo está probando, sería útil que pudiera completar este formulario de registro para que podamos realizar un seguimiento (sin spam, lo prometo). Y si simplemente desea enviarnos su opinión, no dude en completar esta breve encuesta. ¡Gracias por su interés y apoyo!
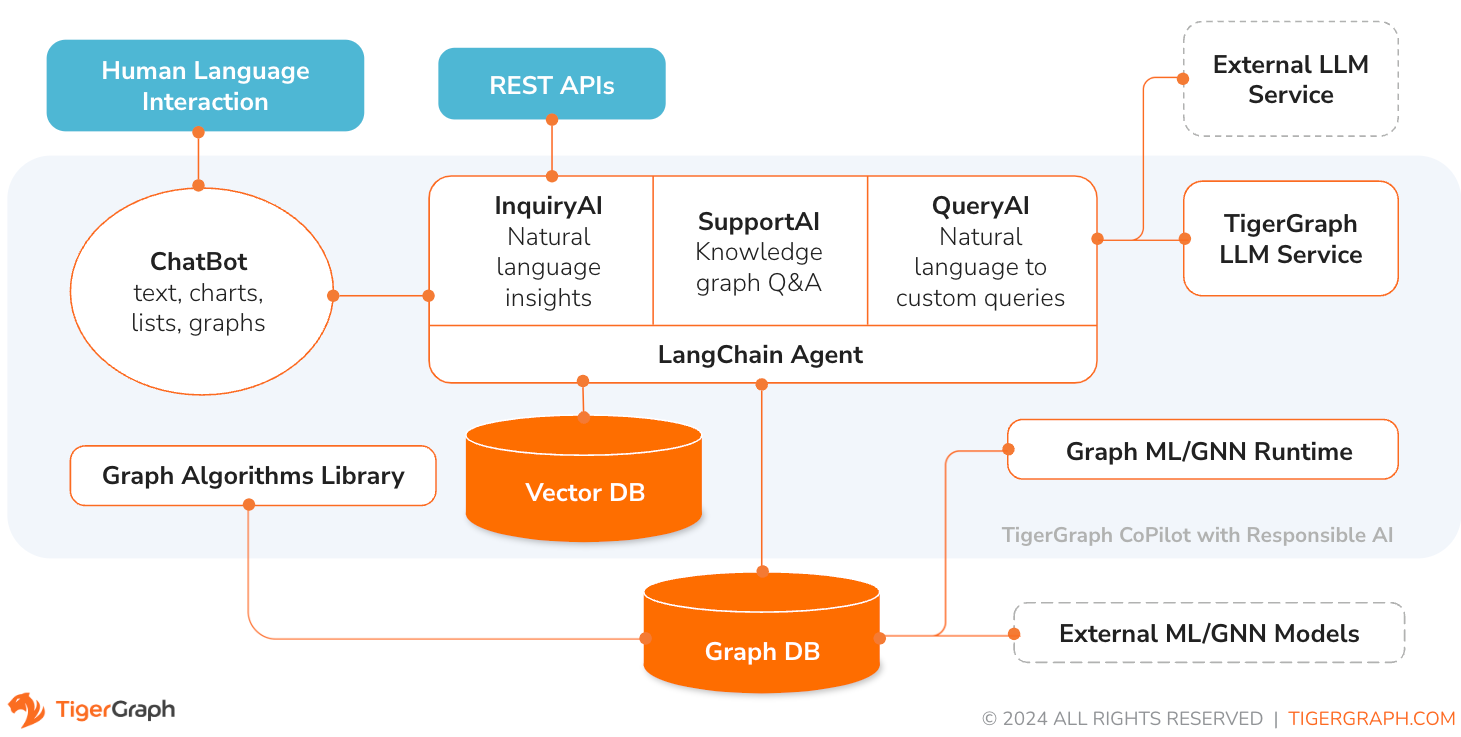
TigerGraph CoPilot es un asistente de IA meticulosamente diseñado para combinar los poderes de las bases de datos gráficas y la IA generativa para extraer el máximo valor de los datos y mejorar la productividad en diversas funciones comerciales, incluidas las tareas de análisis, desarrollo y administración. Es un asistente de IA con tres servicios de componentes principales:
Puede interactuar con CoPilot a través de una interfaz de chat en TigerGraph Cloud, una interfaz de chat integrada y API. Por ahora, se requieren sus propios servicios LLM (de OpenAI, Azure, GCP, AWS Bedrock, Ollama, Hugging Face y Groq.) para usar CoPilot, pero en versiones futuras podrá usar los LLM de TigerGraph.
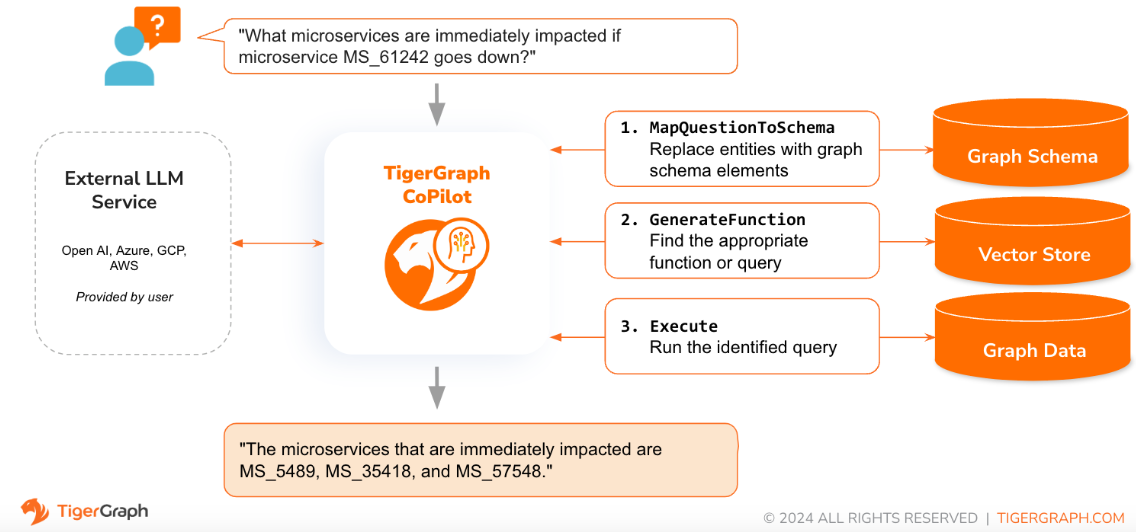
Cuando se plantea una pregunta en lenguaje natural, CoPilot (InquiryAI) emplea una novedosa interacción de tres fases tanto con la base de datos TigerGraph como con un LLM de elección del usuario, para obtener respuestas precisas y relevantes.
La primera fase alinea la pregunta con los datos particulares disponibles en la base de datos. CoPilot utiliza LLM para comparar la pregunta con el esquema del gráfico y reemplazar entidades en la pregunta por elementos del gráfico. Por ejemplo, si hay un tipo de vértice de "BareMetalNode" y el usuario pregunta "¿Cuántos servidores hay?", la pregunta se traducirá a "¿Cuántos vértices de BareMetalNode hay?". En la segunda fase, CoPilot utiliza el LLM para comparar la pregunta transformada con un conjunto de consultas y funciones de bases de datos seleccionadas para seleccionar la mejor coincidencia. En la tercera fase, CoPilot ejecuta la consulta identificada y devuelve el resultado en lenguaje natural junto con el razonamiento detrás de las acciones.
El uso de consultas preaprobadas proporciona múltiples beneficios. En primer lugar, reduce la probabilidad de sufrir alucinaciones, porque se ha validado el significado y el comportamiento de cada consulta. En segundo lugar, el sistema tiene el potencial de predecir los recursos de ejecución necesarios para responder la pregunta.
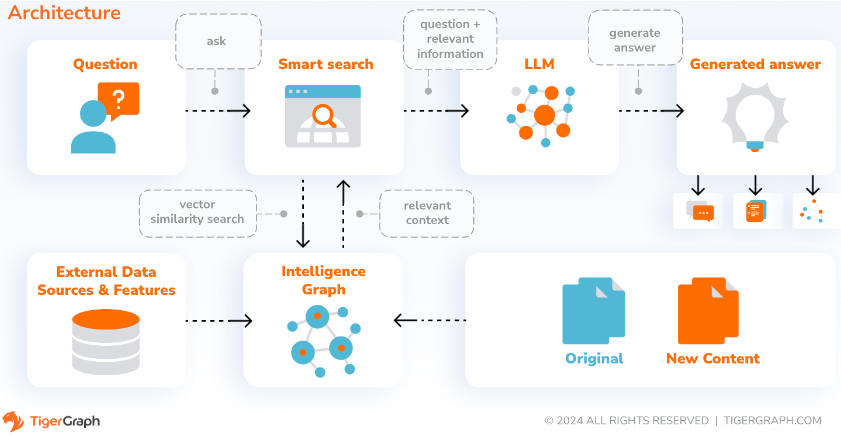
Con SupportAI, CoPilot crea chatbots con IA aumentada con gráficos en los propios documentos o datos de texto de un usuario. Crea un gráfico de conocimiento a partir del material fuente y aplica su variante única de RAG (Generación Aumentada de Recuperación) basada en gráficos de conocimiento para mejorar la relevancia contextual y la precisión de las respuestas a preguntas en lenguaje natural.
CoPilot también identificará conceptos y creará una ontología para agregar semántica y razonamiento al gráfico de conocimiento, o los usuarios pueden proporcionar su propia ontología de conceptos. Luego, con este gráfico de conocimiento integral, CoPilot realiza recuperaciones híbridas, combinando búsqueda de vectores tradicionales y recorridos de gráficos, para recopilar información más relevante y un contexto más rico para responder las preguntas de conocimiento de los usuarios.
Organizar los datos como un gráfico de conocimiento permite que un chatbot acceda a información precisa y basada en hechos de manera rápida y eficiente, reduciendo así la dependencia de generar respuestas a partir de patrones aprendidos durante la capacitación, que a veces pueden ser incorrectos o estar desactualizados.
QueryAI es el tercer componente de TigerGraph CoPilot. Está diseñado para usarse como herramienta de desarrollo para ayudar a generar consultas de gráficos en GSQL a partir de una descripción en idioma inglés. También se puede utilizar para generar esquemas, mapeo de datos e incluso paneles. Esto permitirá a los desarrolladores escribir consultas GSQL de forma más rápida y precisa, y será especialmente útil para quienes son nuevos en GSQL. Actualmente, la generación experimental de openCypher está disponible.
CoPilot está disponible como un servicio complementario para su espacio de trabajo en TigerGraph Cloud. Está deshabilitado de forma predeterminada. Comuníquese con [email protected] para habilitar TigerGraph CoPilot como una opción en Marketplace.
TigerGraph CoPilot es un proyecto de código abierto en GitHub que se puede implementar en su propia infraestructura.
Si no necesita ampliar el código fuente de CoPilot, la forma más rápida es implementar su imagen de la ventana acoplable con el archivo de composición de la ventana acoplable en el repositorio. Para tomar esta ruta, necesitará los siguientes requisitos previos.
Paso 1: obtener el archivo Docker-Compose
git clone https://github.com/tigergraph/CoPilot El archivo Docker Compose contiene todas las dependencias de CoPilot, incluida una base de datos Milvus. Si no necesita un servicio en particular, edite el archivo Compose para eliminarlo o establezca su escala en 0 cuando ejecute el archivo Compose (detalles más adelante). Además, CoPilot viene con una página de documentación de la API Swagger cuando se implementa. Si desea desactivarlo, puede configurar la variable de entorno PRODUCTION en verdadero para el servicio CoPilot en el archivo Compose.
Paso 2: establecer configuraciones
A continuación, en el mismo directorio donde se encuentra el archivo Docker Compose, cree y complete los siguientes archivos de configuración:
Paso 3 (opcional): configurar el registro
touch configs/log_config.json . Los detalles de la configuración están disponibles aquí.
Paso 4: inicie todos los servicios
Ahora, simplemente ejecute docker compose up -d y espere a que se inicien todos los servicios. Si no desea utilizar la base de datos Milvus incluida, puede establecer su escala en 0 para no iniciarla: docker compose up -d --scale milvus-standalone=0 --scale etcd=0 --scale minio=0 .
Paso 5: instalar las UDF
Este paso no es necesario para las bases de datos TigerGraph versión 4.x. Para TigerGraph 3.x, necesitamos instalar algunas funciones definidas por el usuario (UDF) para que CoPilot funcione.
sudo su - tigergraph . Si TigerGraph se ejecuta en un clúster, puede hacerlo en cualquiera de las máquinas. gadmin config set GSQL.UDF.EnablePutTgExpr true
gadmin config set GSQL.UDF.Policy.Enable false
gadmin config apply
gadmin restart GSQL
PUT tg_ExprFunctions FROM "./tg_ExprFunctions.hpp"
PUT tg_ExprUtil FROM "./tg_ExprUtil.hpp"
gadmin config set GSQL.UDF.EnablePutTgExpr false
gadmin config set GSQL.UDF.Policy.Enable true
gadmin config apply
gadmin restart GSQL
En el archivo configs/llm_config.json , copie la plantilla de configuración JSON que aparece a continuación para su proveedor de LLM y complete los campos correspondientes. Sólo se necesita un proveedor.
Abierto AI
Además de OPENAI_API_KEY , llm_model y model_name se pueden editar para que coincidan con sus detalles de configuración específicos.
{
"model_name" : " GPT-4 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " YOUR_OPENAI_API_KEY_HERE "
}
},
"completion_service" : {
"llm_service" : " openai " ,
"llm_model" : " gpt-4-0613 " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " YOUR_OPENAI_API_KEY_HERE "
},
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}PCG
Siga la información de autenticación de GCP que se encuentra aquí: https://cloud.google.com/docs/authentication/application-default-credentials#GAC y cree una cuenta de servicio con credenciales de VertexAI. Luego agregue lo siguiente al comando de ejecución de Docker:
-v $( pwd ) /configs/SERVICE_ACCOUNT_CREDS.json:/SERVICE_ACCOUNT_CREDS.json -e GOOGLE_APPLICATION_CREDENTIALS=/SERVICE_ACCOUNT_CREDS.jsonY su configuración JSON debería ser la siguiente:
{
"model_name" : " GCP-text-bison " ,
"embedding_service" : {
"embedding_model_service" : " vertexai " ,
"authentication_configuration" : {}
},
"completion_service" : {
"llm_service" : " vertexai " ,
"llm_model" : " text-bison " ,
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/gcp_vertexai_palm/ "
}
}Azur
Además de AZURE_OPENAI_ENDPOINT , AZURE_OPENAI_API_KEY y azure_deployment , llm_model y model_name se pueden editar para que coincidan con sus detalles de configuración específicos.
{
"model_name" : " GPT35Turbo " ,
"embedding_service" : {
"embedding_model_service" : " azure " ,
"azure_deployment" : " YOUR_EMBEDDING_DEPLOYMENT_HERE " ,
"authentication_configuration" : {
"OPENAI_API_TYPE" : " azure " ,
"OPENAI_API_VERSION" : " 2022-12-01 " ,
"AZURE_OPENAI_ENDPOINT" : " YOUR_AZURE_ENDPOINT_HERE " ,
"AZURE_OPENAI_API_KEY" : " YOUR_AZURE_API_KEY_HERE "
}
},
"completion_service" : {
"llm_service" : " azure " ,
"azure_deployment" : " YOUR_COMPLETION_DEPLOYMENT_HERE " ,
"openai_api_version" : " 2023-07-01-preview " ,
"llm_model" : " gpt-35-turbo-instruct " ,
"authentication_configuration" : {
"OPENAI_API_TYPE" : " azure " ,
"AZURE_OPENAI_ENDPOINT" : " YOUR_AZURE_ENDPOINT_HERE " ,
"AZURE_OPENAI_API_KEY" : " YOUR_AZURE_API_KEY_HERE "
},
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/azure_open_ai_gpt35_turbo_instruct/ "
}
}Base de AWS
{
"model_name" : " Claude-3-haiku " ,
"embedding_service" : {
"embedding_model_service" : " bedrock " ,
"embedding_model" : " amazon.titan-embed-text-v1 " ,
"authentication_configuration" : {
"AWS_ACCESS_KEY_ID" : " ACCESS_KEY " ,
"AWS_SECRET_ACCESS_KEY" : " SECRET "
}
},
"completion_service" : {
"llm_service" : " bedrock " ,
"llm_model" : " anthropic.claude-3-haiku-20240307-v1:0 " ,
"authentication_configuration" : {
"AWS_ACCESS_KEY_ID" : " ACCESS_KEY " ,
"AWS_SECRET_ACCESS_KEY" : " SECRET "
},
"model_kwargs" : {
"temperature" : 0 ,
},
"prompt_path" : " ./app/prompts/aws_bedrock_claude3haiku/ "
}
}Ollama
{
"model_name" : " GPT-4 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " ollama " ,
"llm_model" : " calebfahlgren/natural-functions " ,
"model_kwargs" : {
"temperature" : 0.0000001
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}abrazando la cara
A continuación se muestra un ejemplo de configuración para un modelo en Hugging Face con un punto final dedicado. Por favor especifique sus detalles de configuración:
{
"model_name" : " llama3-8b " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " huggingface " ,
"llm_model" : " hermes-2-pro-llama-3-8b-lpt " ,
"endpoint_url" : " https:endpoints.huggingface.cloud " ,
"authentication_configuration" : {
"HUGGINGFACEHUB_API_TOKEN" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}A continuación se muestra un ejemplo de configuración para un modelo en Hugging Face con un punto final sin servidor. Por favor especifique sus detalles de configuración:
{
"model_name" : " Llama3-70b " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " huggingface " ,
"llm_model" : " meta-llama/Meta-Llama-3-70B-Instruct " ,
"authentication_configuration" : {
"HUGGINGFACEHUB_API_TOKEN" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/llama_70b/ "
}
}Groq
{
"model_name" : " mixtral-8x7b-32768 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " groq " ,
"llm_model" : " mixtral-8x7b-32768 " ,
"authentication_configuration" : {
"GROQ_API_KEY" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
} Copie lo siguiente en configs/db_config.json y edite los campos hostname y getToken para que coincidan con la configuración de su base de datos. Si la autenticación de token está habilitada en TigerGraph, configure getToken en true . Configure los parámetros de tiempo de espera, umbral de memoria y límite de subprocesos como desee para controlar la cantidad de recursos de la base de datos que se consumen al responder una pregunta.
“ecc” y “chat_history_api” son las direcciones de los componentes internos de CoPilot. Si usa el archivo Docker Compose tal como está, no necesita cambiarlos.
{
"hostname" : " http://tigergraph " ,
"restppPort" : " 9000 " ,
"gsPort" : " 14240 " ,
"getToken" : false ,
"default_timeout" : 300 ,
"default_mem_threshold" : 5000 ,
"default_thread_limit" : 8 ,
"ecc" : " http://eventual-consistency-service:8001 " ,
"chat_history_api" : " http://chat-history:8002 "
} Copie lo siguiente en configs/milvus_config.json y edite los campos host y port para que coincidan con su configuración de Milvus (teniendo en cuenta la configuración de Docker). username y password también se pueden configurar a continuación si así lo requiere la configuración de Milvus. enabled siempre debe establecerse en "true" por ahora, ya que Milvus solo es compatible con el almacén integrado.
{
"host" : " milvus-standalone " ,
"port" : 19530 ,
"username" : " " ,
"password" : " " ,
"enabled" : " true " ,
"sync_interval_seconds" : 60
} Copie el siguiente código en configs/chat_config.json . No debería necesitar cambiar nada a menos que cambie el puerto del servicio de historial de chat en el archivo Docker Compose.
{
"apiPort" : " 8002 " ,
"dbPath" : " chats.db " ,
"dbLogPath" : " db.log " ,
"logPath" : " requestLogs.jsonl " ,
"conversationAccessRoles": ["superuser", "globaldesigner"]
} Si desea habilitar la generación de consultas openCypher en InquiryAI, puede configurar la variable de entorno USE_CYPHER en "true" en el servicio CoPilot en el archivo de composición de la ventana acoplable. De forma predeterminada, esto está configurado en "false" . Nota : la generación de consultas de openCypher aún está en versión beta y es posible que no funcione como se esperaba, además de aumentar el potencial de respuestas alucinadas debido a la generación de código incorrecto. Úselo con precaución y solo en entornos que no sean de producción.
CoPilot es amigable tanto para usuarios técnicos como no técnicos. Hay una interfaz gráfica de chat y acceso API a CoPilot. En cuanto a las funciones, CoPilot puede responder sus preguntas llamando a consultas existentes en la base de datos (InquiryAI), crear un gráfico de conocimiento a partir de sus documentos (SupportAI) y responder preguntas de conocimiento basadas en sus documentos (SupportAI).
Consulte nuestra documentación oficial sobre cómo utilizar CoPilot.
TigerGraph CoPilot está diseñado para ser fácilmente extensible. El servicio se puede configurar para utilizar diferentes proveedores de LLM, diferentes esquemas de gráficos y diferentes herramientas LangChain. El servicio también se puede ampliar para utilizar diferentes servicios de integración, diferentes servicios de generación de LLM y diferentes herramientas LangChain. Para obtener más información sobre cómo ampliar el servicio, consulte la Guía para desarrolladores.
Se incluye una familia de pruebas en el directorio tests . Si desea agregar más pruebas, consulte la guía aquí. También se incluye un script de shell run_tests.sh en la carpeta que es el controlador para ejecutar las pruebas. La forma más sencilla de utilizar este script es ejecutarlo en el contenedor Docker para realizar pruebas.
Puede ejecutar pruebas para cada servicio yendo al nivel superior del directorio del servicio y ejecutando python -m pytest
por ejemplo (desde el nivel superior)
cd copilot
python -m pytest
cd ..Primero, asegúrese de que todos los archivos de configuración de su proveedor de servicios LLM funcionen correctamente. Las configuraciones se montarán para que pueda acceder el contenedor. También asegúrese de que todas las dependencias, como la base de datos y Milvus, estén listas. De lo contrario, puede ejecutar el archivo de redacción acoplable incluido para crear esos servicios.
docker compose up -d --buildSi desea utilizar Weights And Biases para registrar los resultados de las pruebas, su clave API de WandB debe configurarse en una variable de entorno en la máquina host.
export WANDB_API_KEY=KEY HERE Luego, puede crear el contenedor acoplable a partir del archivo Dockerfile.tests y ejecutar el script de prueba en el contenedor.
docker build -f Dockerfile.tests -t copilot-tests:0.1 .
docker run -d -v $( pwd ) /configs/:/ -e GOOGLE_APPLICATION_CREDENTIALS=/GOOGLE_SERVICE_ACCOUNT_CREDS.json -e WANDB_API_KEY= $WANDB_API_KEY -it --name copilot-tests copilot-tests:0.1
docker exec copilot-tests bash -c " conda run --no-capture-output -n py39 ./run_tests.sh all all " Para editar qué pruebas se ejecutan, se pueden pasar argumentos al script ./run_tests.sh . Actualmente, se puede configurar qué servicio LLM usar (predeterminado en todos), con qué esquemas probar (predeterminado en todos) y si usar o no pesos y sesgos para el registro (predeterminado en verdadero). Las instrucciones de las opciones se encuentran a continuación:
El primer parámetro de run_tests.sh es con qué LLM probar. El valor predeterminado es all . Las opciones son:
all : ejecute pruebas en todos los LLMazure_gpt35 : ejecuta pruebas en GPT-3.5 alojado en Azureopenai_gpt35 : ejecuta pruebas contra GPT-3.5 alojado en OpenAIopenai_gpt4 : ejecuta pruebas en GPT-4 alojado en OpenAIgcp_textbison : ejecuta pruebas en text-bison alojado en GCP El segundo parámetro de run_tests.sh es con qué gráficos probar. El valor predeterminado es all . Las opciones son:
all : ejecuta pruebas con todos los gráficos disponiblesOGB_MAG : el conjunto de datos de artículos académicos proporcionado por: https://ogb.stanford.edu/docs/nodeprop/#ogbn-mag.DigtialInfra : conjunto de datos de gemelos digitales de infraestructura digitalSynthea - Conjunto de datos de salud sintéticos Si desea registrar los resultados de la prueba en Weights and Biases (y tener las credenciales correctas configuradas arriba), el parámetro final de run_tests.sh se establece automáticamente en verdadero. Si desea desactivar el registro de pesos y sesgos, utilice false .
Si desea contribuir a TigerGraph CoPilot, lea la documentación aquí.


