LLM Alignment Project
1.0.0
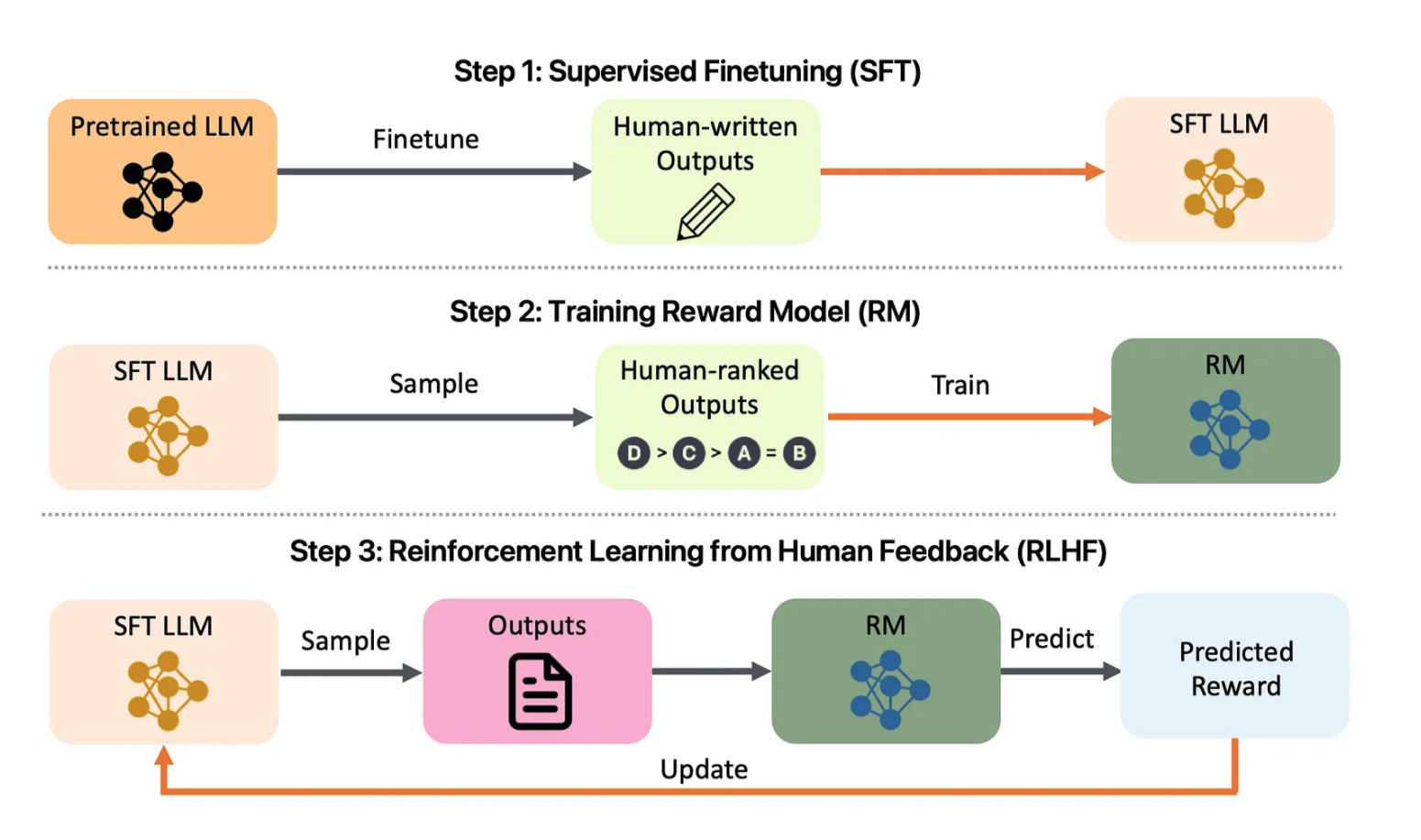
Figura 1: Descripción general del proyecto de alineación de LLM. Eche un vistazo a: arXiv:2308.05374
La plantilla de alineación de LLM no es solo una herramienta integral para alinear modelos de lenguajes grandes (LLM), sino que también sirve como una plantilla poderosa para crear su propia aplicación de alineación de LLM. Inspirado en plantillas de proyectos como PyTorch Project Template , este repositorio está diseñado para proporcionar una pila completa de funcionalidades, actuando como punto de partida para personalizar y ampliar sus propias necesidades de alineación de LLM. Ya sea investigador, desarrollador o científico de datos, esta plantilla proporciona una base sólida para crear e implementar de manera eficiente LLM diseñados para alinearse con los valores y objetivos humanos.
La plantilla de alineación de LLM proporciona una pila completa de funciones, que incluyen capacitación, ajuste, implementación y monitoreo de LLM mediante el aprendizaje reforzado a partir de la retroalimentación humana (RLHF). Este proyecto también integra métricas de evaluación para garantizar el uso ético y eficaz de los modelos lingüísticos. La interfaz ofrece una experiencia fácil de usar para gestionar la alineación, visualizar métricas de capacitación e implementar a escala.
app/ : Contiene código API y UI.
auth.py , feedback.py , ui.py : puntos finales API para la interacción del usuario, recopilación de comentarios y gestión general de la interfaz.app.js , chart.js ), CSS ( styles.css ) y documentación de la API de Swagger ( swagger.json ).chat.html , feedback.html , index.html ) para la representación de la interfaz de usuario. src/ : Lógica central y utilidades para preprocesamiento y entrenamiento.
preprocessing/ ):preprocess_data.py : combina conjuntos de datos originales y aumentados y aplica limpieza de texto.tokenization.py : maneja la tokenización.training/ ):fine_tuning.py , transfer_learning.py , retrain_model.py : scripts para entrenar y reentrenar modelos.rlhf.py , reward_model.py : secuencias de comandos para el entrenamiento del modelo de recompensa utilizando RLHF.utils/ ): Utilidades comunes ( config.py , logging.py , validation.py ). dashboards/ : Paneles de rendimiento y explicabilidad para monitoreo e información del modelo.
performance_dashboard.py : muestra métricas de entrenamiento, pérdida de validación y precisión.explainability_dashboard.py : visualiza los valores SHAP para proporcionar información sobre las decisiones del modelo. tests/ : Pruebas unitarias, de integración y de un extremo a otro.
test_api.py , test_preprocessing.py , test_training.py : varias pruebas unitarias y de integración.e2e/ ): pruebas de interfaz de usuario basadas en Cypress ( ui_tests.spec.js ).load_testing/ ): utiliza Locust ( locustfile.py ) para las pruebas de carga. deployment/ : Archivos de configuración para implementación y monitoreo.
kubernetes/ ): configuraciones de implementación e ingreso para versiones escalables y canarias.monitoring/ ): Prometheus ( prometheus.yml ) y Grafana ( grafana_dashboard.json ) para monitorear el rendimiento y el estado del sistema. Clonar el repositorio :
git clone https://github.com/yourusername/LLM-Alignment-Template.git
cd LLM-Alignment-TemplateInstalar dependencias :
pip install -r requirements.txt cd app/static
npm installConstruir imágenes de Docker :
docker-compose up --buildAccede a la Aplicación :
http://localhost:5000 . kubectl apply -f deployment/kubernetes/deployment.yml
kubectl apply -f deployment/kubernetes/service.ymlkubectl apply -f deployment/kubernetes/hpa.ymldeployment/kubernetes/canary_deployment.yml para implementar nuevas versiones de forma segura.deployment/monitoring/ para habilitar paneles de monitoreo.docker-compose.logging.yml para registros centralizados. El módulo de capacitación ( src/training/transfer_learning.py ) utiliza modelos previamente entrenados como BERT para adaptarse a tareas personalizadas, lo que proporciona un aumento significativo del rendimiento.
El script data_augmentation.py ( src/data/ ) aplica técnicas de aumento como retrotraducción y paráfrasis para mejorar la calidad de los datos.
rlhf.py y reward_model.py para ajustar los modelos basándose en los comentarios humanos.feedback.html ) y el modelo se vuelve a entrenar con retrain_model.py . El script explainability_dashboard.py utiliza valores SHAP para ayudar a los usuarios a comprender por qué un modelo realizó predicciones específicas.
tests/ , que cubren funcionalidades de API, preprocesamiento y capacitación.tests/load_testing/locustfile.py ) para garantizar la estabilidad bajo carga. ¡Las contribuciones son bienvenidas! Envíe solicitudes de extracción o problemas para obtener mejoras o nuevas funciones.
Este proyecto está bajo la licencia MIT. Consulte el archivo de LICENCIA para obtener más información.
Desarrollado con ❤️ por Amirsina Torfi


