?️Herramienta GenAI de imagen a voz con LLM?♨️
Herramienta de inteligencia artificial que genera una historia corta en audio basada en el contexto de una imagen cargada al solicitar un modelo GenAI LLM, modelos de inteligencia artificial de Hugging Face junto con OpenAI y LangChain. Implementado en Streamlit y Hugging Space Cloud por separado.
Ejecutar aplicación con Streamlit Cloud
Inicie la aplicación en Streamlit
Ejecute la aplicación con HuggingFace Space Cloud
Inicie la aplicación en HuggingFace Space
Manifestación:
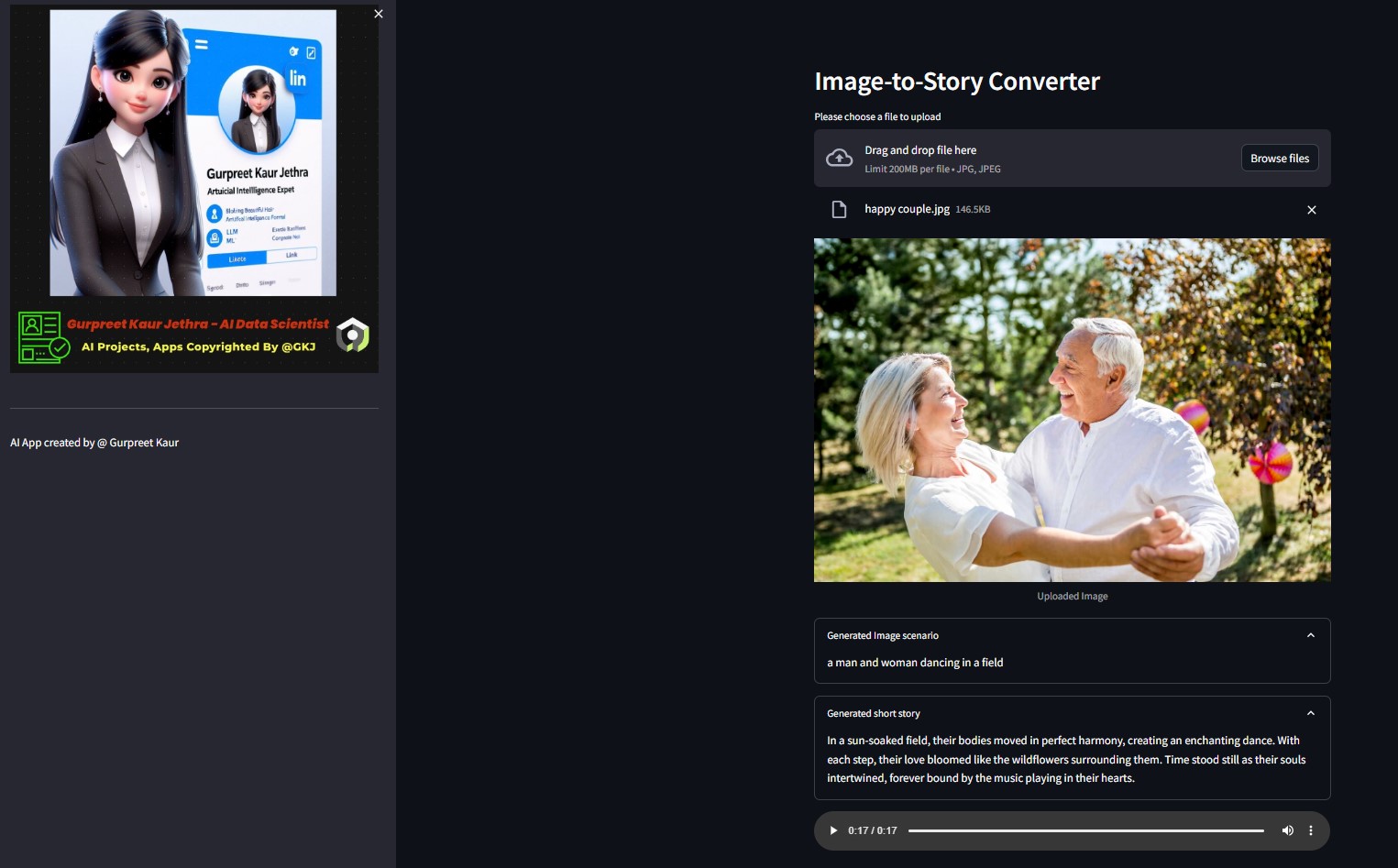
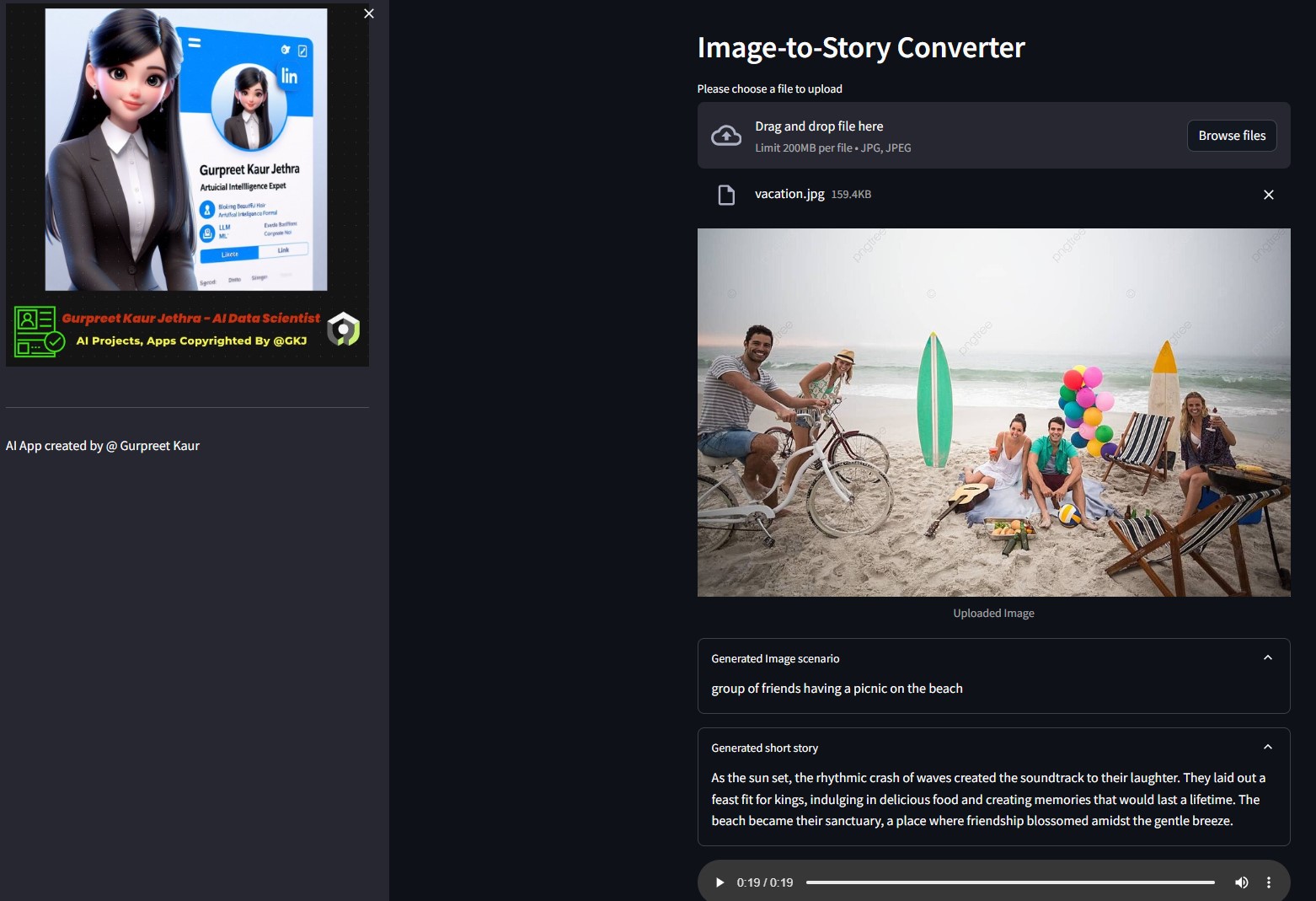
Puede escuchar el archivo de audio respectivo de las imágenes de demostración de esta prueba en la carpeta img-audio respectiva
?Diseño del sistema
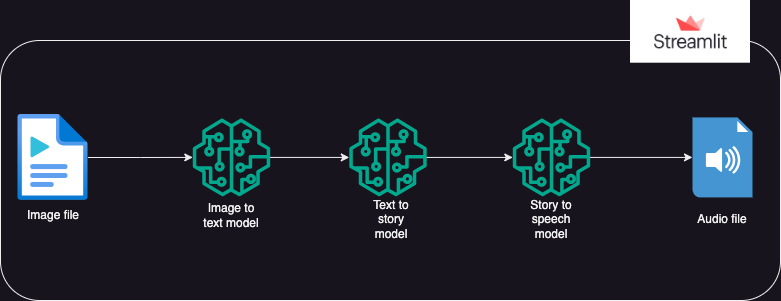
?Acercarse
Una aplicación que utiliza modelos de IA de Hugging Face para generar texto a partir de una imagen, que luego genera audio a partir del texto.
La ejecución se divide en 3 partes:
- Imagen a texto: se utiliza un modelo transformador de imagen a texto (Salesforce/blip-image-captioning-base) para generar un escenario de texto basado en la comprensión de la IA del contexto de la imagen.
- Texto a historia: se solicita al modelo OpenAI LLM que cree una historia corta (50 palabras: se puede ajustar según sea necesario) en función del escenario generado. gpt-3.5-turbo
- Historia a voz: se utiliza un modelo transformador de texto a voz (espnet/kan-bayashi_ljspeech_vits) para convertir la historia corta generada en un archivo de audio narrado por voz.
- Se crea una interfaz de usuario utilizando Streamlit para permitir cargar la imagen y reproducir el archivo de audio.
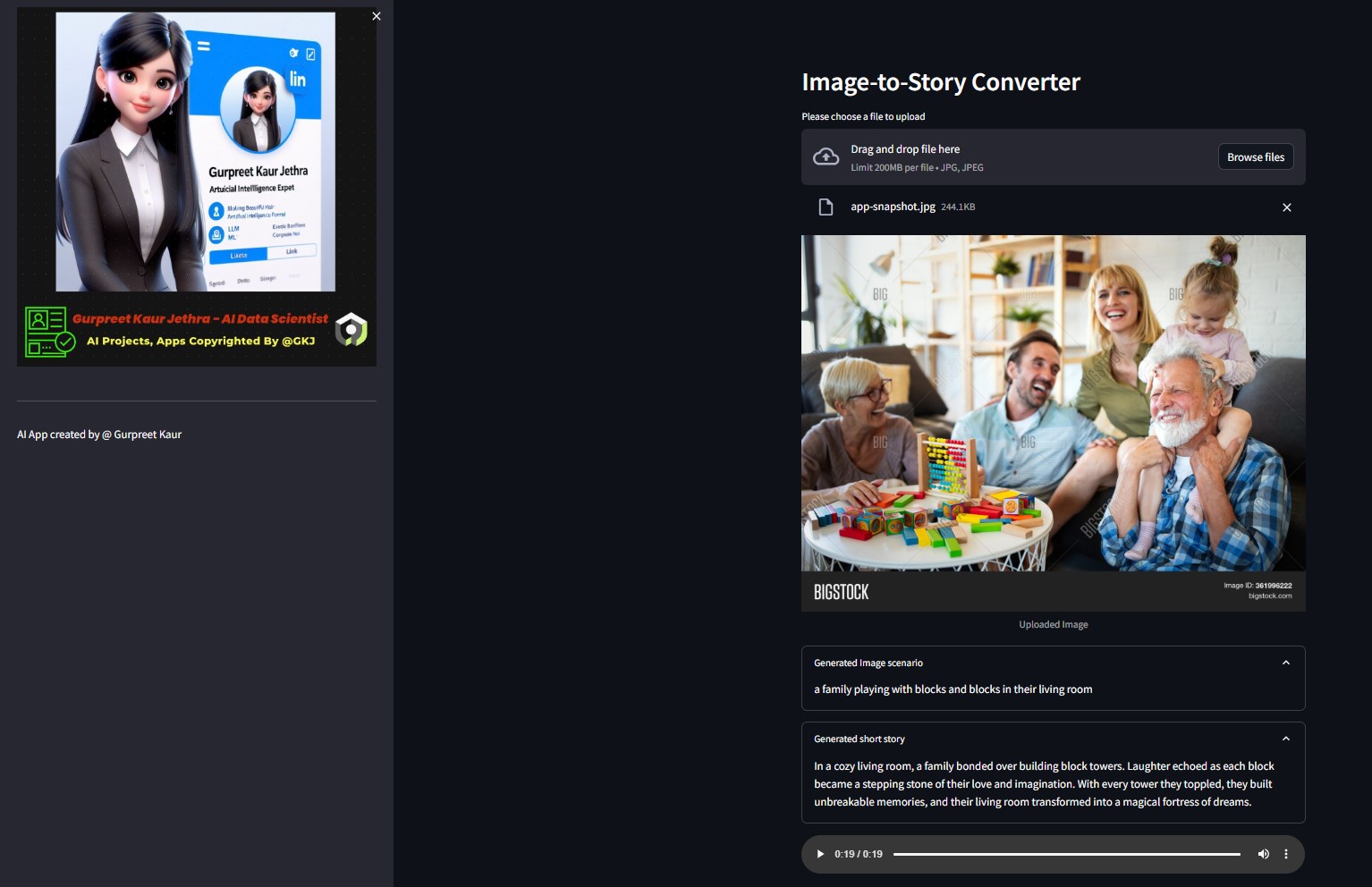 Puede escuchar el archivo de audio respectivo de esta imagen de prueba en la carpeta
Puede escuchar el archivo de audio respectivo de esta imagen de prueba en la carpeta img-audio respectiva
?Requisitos
- sistema operativo
- python-dotenv
- transformadores
- antorcha
- cadena larga
- abierto
- solicitudes
- iluminado
Uso
- Antes de usar la aplicación, el usuario debe tener tokens personales para Hugging Face y Open AI.
- El usuario debe configurar el entorno venv e instalar la biblioteca ipykernel para ejecutar la aplicación en el sistema local.
- El usuario debe guardar los tokens personales en un archivo ".env" dentro del paquete como objetos de cadena bajo los nombres de objeto: HUGGINGFACE_TOKEN y OPENAI_TOKEN.
- Luego, el usuario puede ejecutar la aplicación usando el comando: streamlit run app.py
- Una vez que la aplicación se ejecuta en Streamlit, el usuario puede cargar la imagen de destino.
- La ejecución comenzará automáticamente y puede tardar unos minutos en completarse.
- Una vez completado, la aplicación mostrará:
- El texto del escenario generado por el modelo HuggingFace del transformador de imagen a texto
- La historia corta generada al impulsar OpenAI LLM
- El archivo de audio que narra el cuento generado por el modelo transformador de texto a voz.
- Implementación de la aplicación Gen AI en una nube optimizada y Hugging Space
▶️ Instalación
Clonar el repositorio:
git clone https://github.com/GURPREETKAURJETHRA/Image-to-Speech-GenAI-Tool-Using-LLM.git
Instale los paquetes de Python necesarios:
pip install -r requirements.txt
Configure su clave API OpenAI y su token Hugging Face creando un archivo .env en el directorio raíz del proyecto con el siguiente contenido:
OPENAI_API_KEY=<your-api-key-here> HUGGINGFACE_API_TOKEN=<<your-access-token-here>
Ejecute la aplicación Streamlit:
streamlit run app.py
©️ Licencia
Distribuido bajo la licencia MIT. Consulte LICENSE para obtener más información.
Si le gusta este proyecto LLM, visite este repositorio y ¡las contribuciones son bienvenidas! Si tiene alguna sugerencia para mejorar este AI Img-Speech Converter, envíe una solicitud de extracción.
Sígueme en


