BinaryVectorDB
1.0.0
Este repositorio contiene una base de datos de vectores binarios para una búsqueda eficiente en grandes conjuntos de datos, con fines educativos.
La mayoría de los modelos de incrustación representan sus vectores como float32: consumen mucha memoria y la búsqueda en ellos es muy lenta. En Cohere, presentamos el primer modelo de integración con soporte nativo int8 y binario, que le brinda una excelente calidad de búsqueda por una fracción del costo:
| Modelo | Calidad de búsqueda MIRACL | Es hora de buscar 1 millón de documentos | Memoria necesaria 250 millones de incrustaciones de Wikipedia | Precio en AWS (instancia x2gb) |
|---|---|---|---|---|
| Incrustación de texto OpenAI-3-pequeño | 44,9 | 680 ms | 1431GB | $65,231 / año |
| Incrustación de texto OpenAI-3-grande | 54,9 | 1240 ms | 2861GB | $130,463 / año |
| Cohere Embed v3 (multilingüe) | ||||
| Incrustar v3 - float32 | 66,3 | 460 ms | 954GB | $43,488 / año |
| Incrustar v3 - binario | 62,8 | 24 ms | 30 GB | $1,359 / año |
| Incrustar v3 - rescore binario + int8 | 66,3 | 28 ms | Memoria de 30 GB + disco de 240 GB | $1,589 / año |
Creamos una demostración que le permite buscar en 100 millones de incrustaciones de Wikipedia una máquina virtual que cuesta solo $15 al mes: Demostración: busque en 100 millones de incrustaciones de Wikipedia por solo $15 al mes
Puede utilizar BinaryVectorDB fácilmente con sus propios datos.
La configuración es fácil:
pip install BinaryVectorDB
Para utilizar algunos de los ejemplos siguientes, necesita una clave API de Cohere (gratuita o de pago) de cohere.com. Debe configurar esta clave API como una variable de entorno: export COHERE_API_KEY=your_api_key
Más adelante mostraremos cómo construir una base de datos vectorial con sus propios datos. Para empezar, usemos una base de datos de vectores binarios preconstruida . Alojamos varias bases de datos prediseñadas en https://huggingface.co/datasets/Cohere/BinaryVectorDB. Puede descargarlos y utilizarlos localmente.
Para comenzar, usemos la versión simple en inglés de Wikipedia:
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
Y luego descomprime este archivo:
unzip wikipedia-2023-11-simple.zip
Puede cargar la base de datos fácilmente apuntándola a la carpeta descomprimida del paso anterior:
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )La base de datos tiene 646.424 incrustaciones y un tamaño total de 962 MB. Sin embargo, sólo se cargan en la memoria 80 MB para las incrustaciones binarias. Los documentos y sus incrustaciones int8 se guardan en el disco y solo se cargan cuando es necesario.
Esta división de incrustaciones binarias en memoria e incrustaciones y documentos int8 en disco nos permite escalar a conjuntos de datos muy grandes sin necesidad de toneladas de memoria.
Es bastante fácil crear su propia base de datos de vectores binarios.
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ]) El documento puede ser cualquier objeto serializable de Python. Debe proporcionar una función para docs2text que asigne su documento a una cadena. En el ejemplo anterior, concatenamos el título y el campo de texto. Esta cadena se envía al modelo de incrustación para producir las incrustaciones de texto necesarias.
Agregar, eliminar o actualizar documentos es fácil. Consulte ejemplos/add_update_delete.py para ver un script de ejemplo sobre cómo agregar/actualizar/eliminar documentos en la base de datos.
Anunciamos nuestras incorporaciones Cohere int8 y binario Embeddings, que ofrecen una reducción de 4x y 32x en la memoria necesaria. Además, ofrece una aceleración de hasta 40 veces en la búsqueda de vectores.
Ambas técnicas se combinan en BinaryVectorDB. Por ejemplo, supongamos que la Wikipedia en inglés tiene 42 millones de incrustaciones. Las incrustaciones normales de float32 necesitarían 42*10^6*1024*4 = 160 GB de memoria para alojar las incrustaciones. Como la búsqueda en float32 es bastante lenta (aproximadamente 45 segundos en incrustaciones de 42 M), necesitamos agregar un índice como HNSW, que agrega otros 20 GB de memoria, por lo que necesita un total de 180 GB.
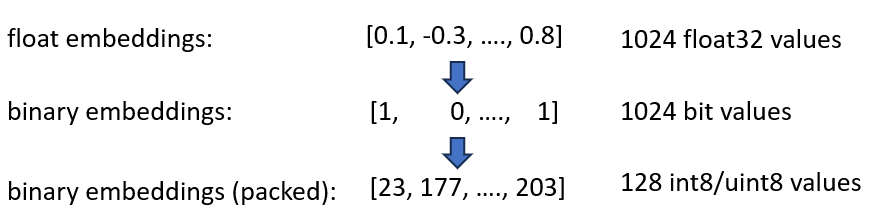
Las incrustaciones binarias representan cada dimensión como 1 bit. Esto reduce la necesidad de memoria a 160 GB / 32 = 5GB . Además, como la búsqueda en el espacio binario es 40 veces más rápida, en muchos casos ya no es necesario el índice HNSW. Redujiste tu necesidad de memoria de 180 GB a 5 GB, un buen ahorro de 36 veces.
Cuando consultamos este índice, codificamos la consulta también en binario y usamos la distancia de Hamming. La distancia de Hamming mide las diferencias de 1 bit entre 2 vectores. Esta es una operación extremadamente rápida: para comparar dos vectores binarios, solo necesita 2 ciclos de CPU: popcount(xor(vector1, vector2)) . XOR es la operación más fundamental en las CPU, por lo que se ejecuta extremadamente rápido. popcount cuenta el número de 1 en el registro, que también necesita solo 1 ciclo de CPU.
En general, esto nos brinda una solución que mantiene aproximadamente el 90 % de la calidad de la búsqueda.
Podemos aumentar la calidad de la búsqueda del paso anterior del 90% al 95% volviendo a puntuar <float, binary> .
Tomamos, por ejemplo, los 100 resultados principales del paso 1 y calculamos dot_product(query_float_embedding, 2*binary_doc_embedding-1) .
Supongamos que la incrustación de nuestra consulta es [0.1, -0.3, 0.4] y la incrustación de nuestro documento binario es [1, 0, 1] . Este paso luego calcula:
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

Usamos estos puntajes y volvemos a calificar nuestros resultados. Esto eleva la calidad de la búsqueda del 90% al 95%. Esta operación se puede realizar extremadamente rápido: obtenemos la incrustación flotante de consulta del modelo de incrustación, las incrustaciones binarias están en la memoria, por lo que solo necesitamos realizar 100 operaciones de suma.
Para mejorar aún más la calidad de la búsqueda, del 95% al 99,99%, utilizamos la recuperación int8 desde el disco.
Guardamos todas las incrustaciones de documentos int8 en el disco. Luego tomamos el top 30 del paso anterior, cargamos las int8-embeddings desde el disco y calculamos cossim(query_float_embedding, int8_doc_embedding_from_disk)
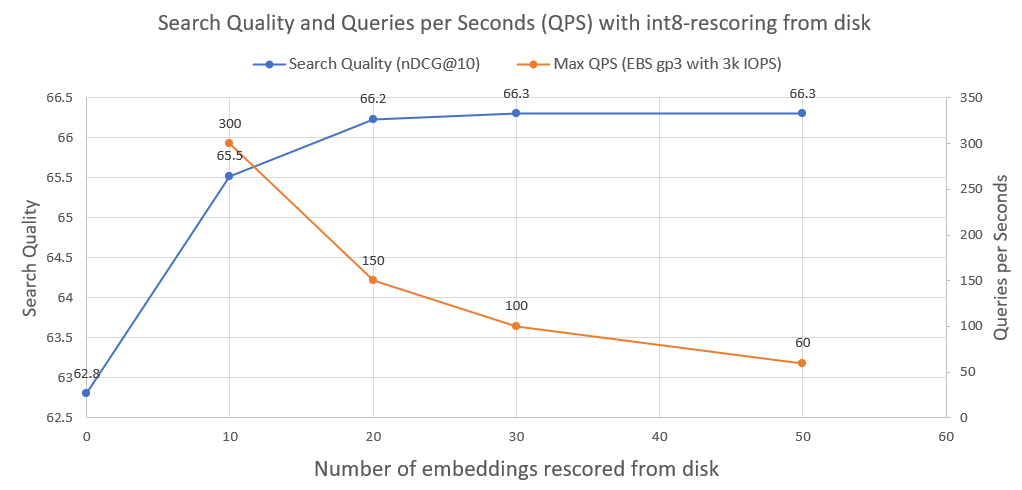
En la siguiente imagen puedes ver cuánto recupera int8 y mejora el rendimiento de la búsqueda:
También trazamos las consultas por segundo que un sistema de este tipo puede lograr cuando se ejecuta en una unidad de red AWS EBS normal con 3000 IOPS. Como vemos, cuantas más incrustaciones int8 necesitemos cargar desde el disco, menos QPS.
Para realizar la búsqueda binaria utilizamos el índice IndexBinaryFlat de faiss. Simplemente almacena las incrustaciones binarias, permite una indexación y una búsqueda súper rápidas.
Para almacenar los documentos y las incrustaciones int8, utilizamos RocksDict, un almacenamiento clave-valor en disco para Python basado en RocksDB.
Consulte BinaryVectorDB para conocer la implementación completa de la clase.
No precisamente. El repositorio está destinado principalmente a fines educativos para mostrar técnicas sobre cómo escalar a grandes conjuntos de datos. La atención se centró más en la facilidad de uso y faltan algunos aspectos críticos en la implementación, como la seguridad de múltiples procesos, reversiones, etc.
Si realmente desea pasar a producción, utilice una base de datos vectorial adecuada como Vespa.ai, que le permitirá lograr resultados similares.
En Cohere ayudamos a los clientes a ejecutar búsqueda semántica en decenas de miles de millones de incorporaciones, a una fracción del costo. No dude en comunicarse con Nils Reimers si necesita una solución escalable.


