VideoX
1.0.0
Esta es una colección de nuestro trabajo de comprensión en video.
SeqTrack (
@CVPR'23): SeqTrack: aprendizaje de secuencia a secuencia para el seguimiento de objetos visuales
X-CLIP (
@ECCV'22 Oral): ampliación de modelos preentrenados de lenguaje e imagen para el reconocimiento general de vídeo
MS-2D-TAN (
@TPAMI'21): Redes adyacentes temporales 2D de múltiples escalas para localización de momentos con lenguaje natural
2D-TAN (
@AAAI'20): Aprendizaje de redes adyacentes temporales 2D para la localización de momentos con lenguaje natural
Contratación de pasantes de investigación con sólidas habilidades de codificación: [email protected] | [email protected]
Abril de 2023: ya se ha publicado el código para SeqTrack .
Febrero de 2023: SeqTrack fue aceptado en CVPR'23
Septiembre de 2022: X-CLIP ahora está integrado en
Agosto de 2022: ya se publica el código para X-CLIP .
Julio de 2022: X-CLIP fue aceptado en ECCV'22 como Oral
Octubre de 2021: ya se publica el código para MS-2D-TAN .
Septiembre de 2021: MS-2D-TAN fue aceptado en TPAMI'21
Diciembre de 2019: ya se ha publicado el código para 2D-TAN .
Noviembre de 2019: 2D-TAN fue aceptado en AAAI'20
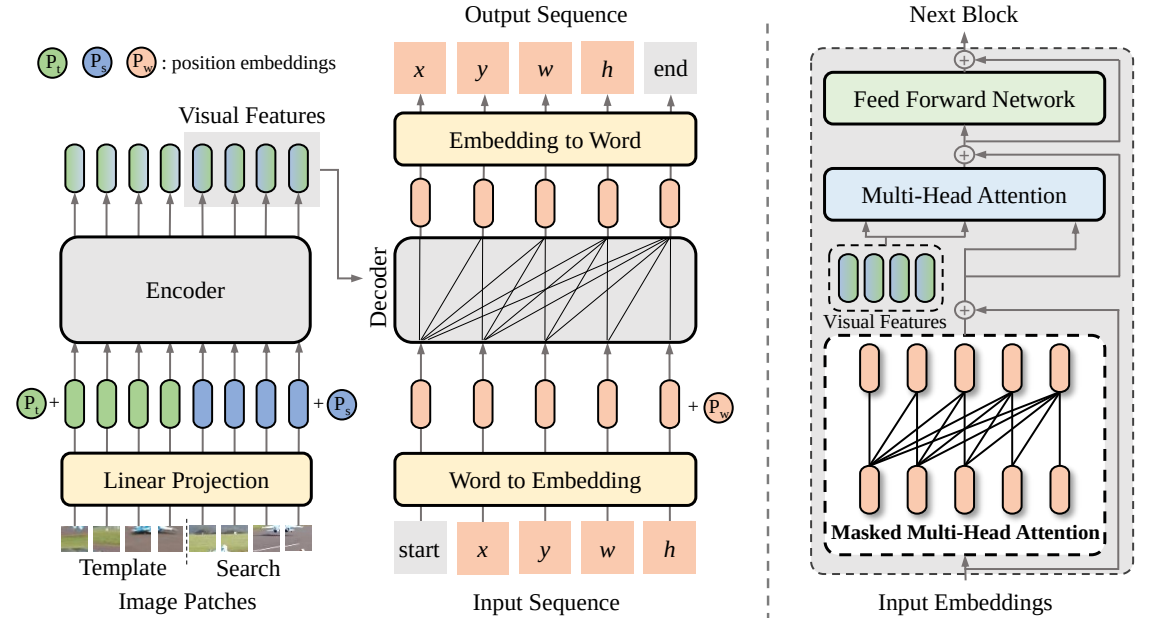
En este artículo, proponemos un nuevo marco de aprendizaje secuencia a secuencia para el seguimiento visual, denominado SeqTrack. Presenta el seguimiento visual como un problema de generación de secuencias, que predice cuadros delimitadores de objetos de forma autorregresiva. SeqTrack solo adopta una arquitectura de transformador codificador-decodificador simple. El codificador extrae características visuales con un transformador bidireccional, mientras que el decodificador genera una secuencia de valores de cuadro delimitador de forma autorregresiva con un decodificador causal. La función de pérdida es una simple entropía cruzada. Este paradigma de aprendizaje secuencial no sólo simplifica el marco de seguimiento, sino que también logra un rendimiento competitivo en muchos puntos de referencia.
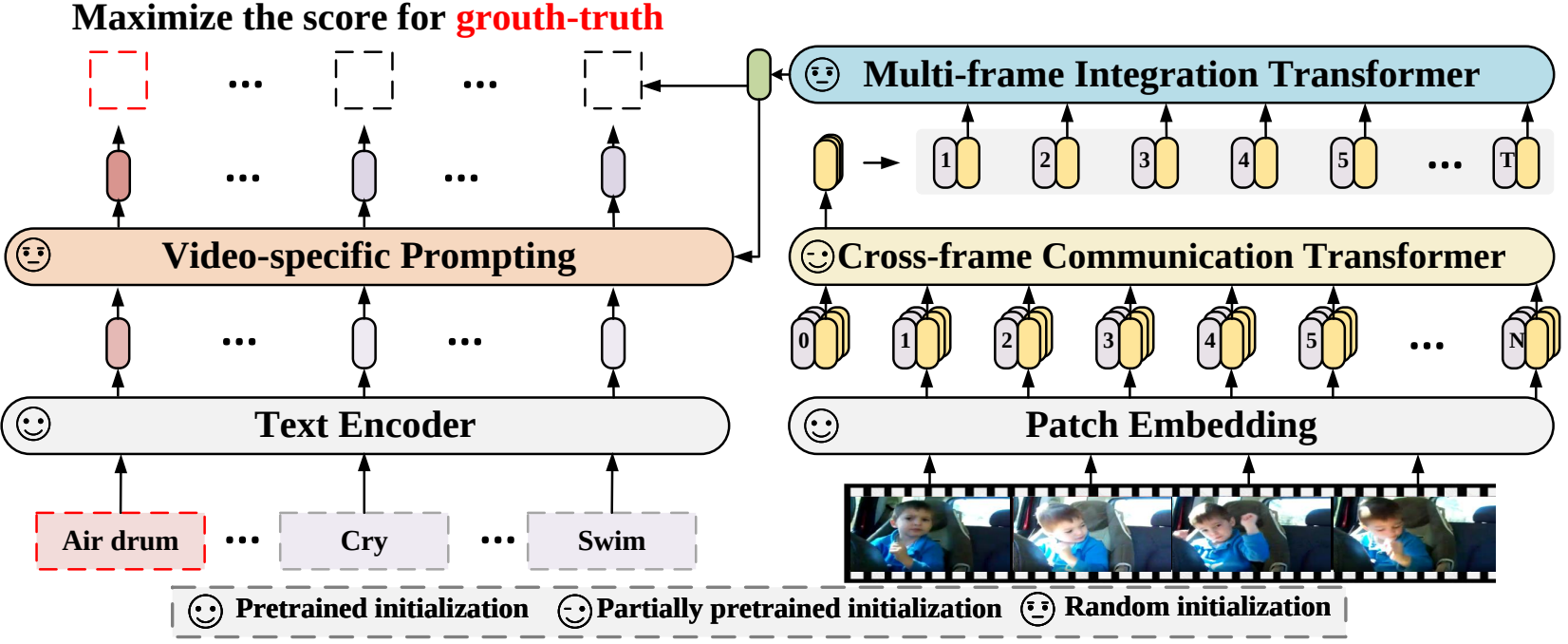
En este artículo, proponemos un nuevo marco de reconocimiento de video que adapta los modelos de lenguaje-imagen previamente entrenados al reconocimiento de video. Específicamente, para capturar la información temporal, proponemos un mecanismo de atención entre cuadros que intercambia información explícitamente entre cuadros. Para utilizar la información de texto en categorías de video, diseñamos una técnica de indicaciones específica de video que puede generar una representación textual discriminativa a nivel de instancia. Amplios experimentos demuestran que nuestro enfoque es eficaz y se puede generalizar a diferentes escenarios de reconocimiento de vídeo, incluidos los totalmente supervisados, los de pocos disparos y los de cero disparos.
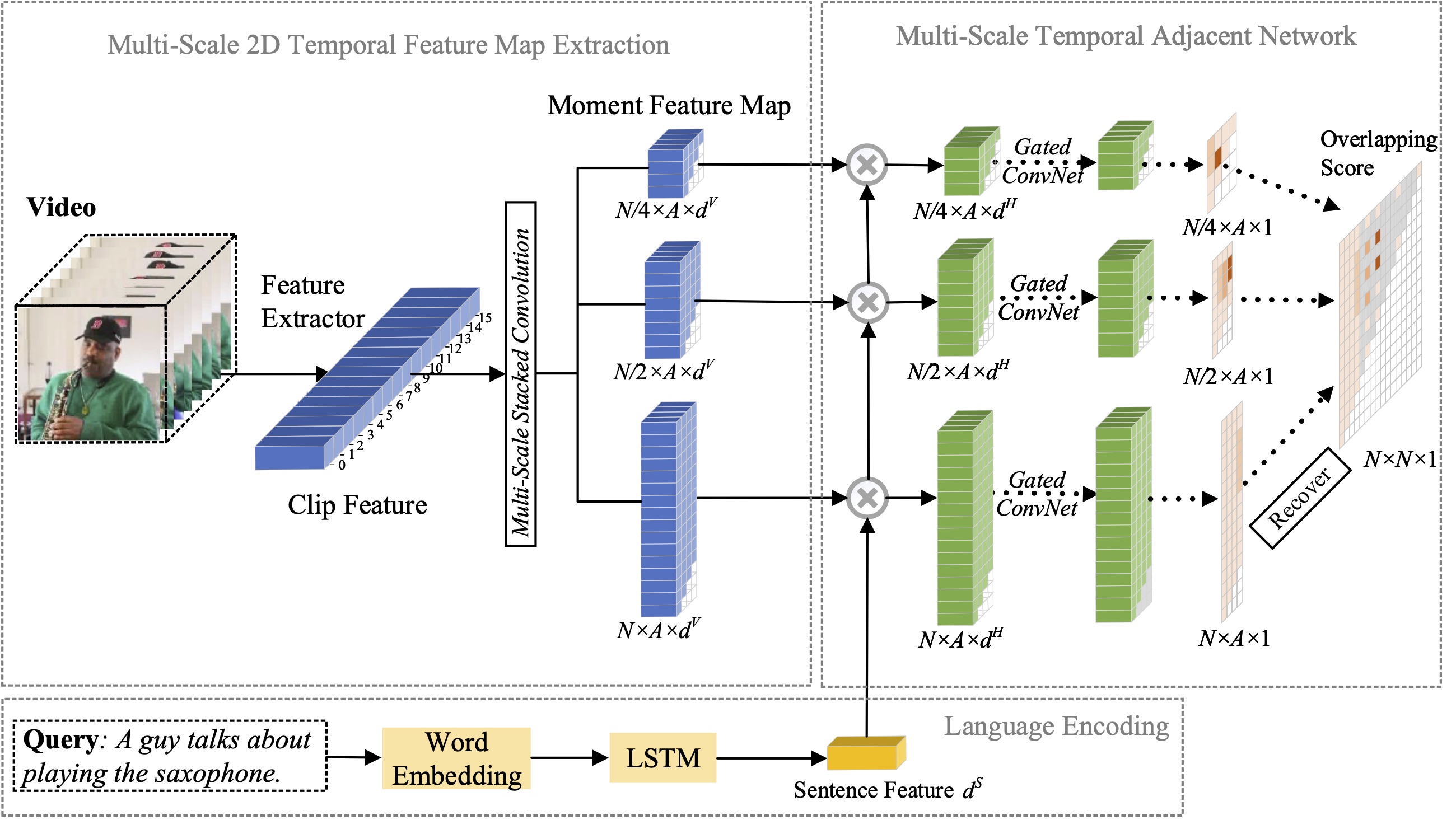
En este artículo, estudiamos el problema de la localización de momentos con lenguaje natural y proponemos extender nuestro método 2D-TAN propuesto anteriormente a una versión multiescala. La idea central es recuperar un momento a partir de mapas temporales bidimensionales en diferentes escalas temporales, que consideran candidatos a momentos adyacentes como contexto temporal. La versión extendida es capaz de codificar relaciones temporales adyacentes en diferentes escalas, mientras aprende características discriminativas para hacer coincidir momentos de video con expresiones de referencia. Nuestro modelo tiene un diseño simple y logra un rendimiento competitivo en comparación con los métodos más modernos en tres conjuntos de datos de referencia.
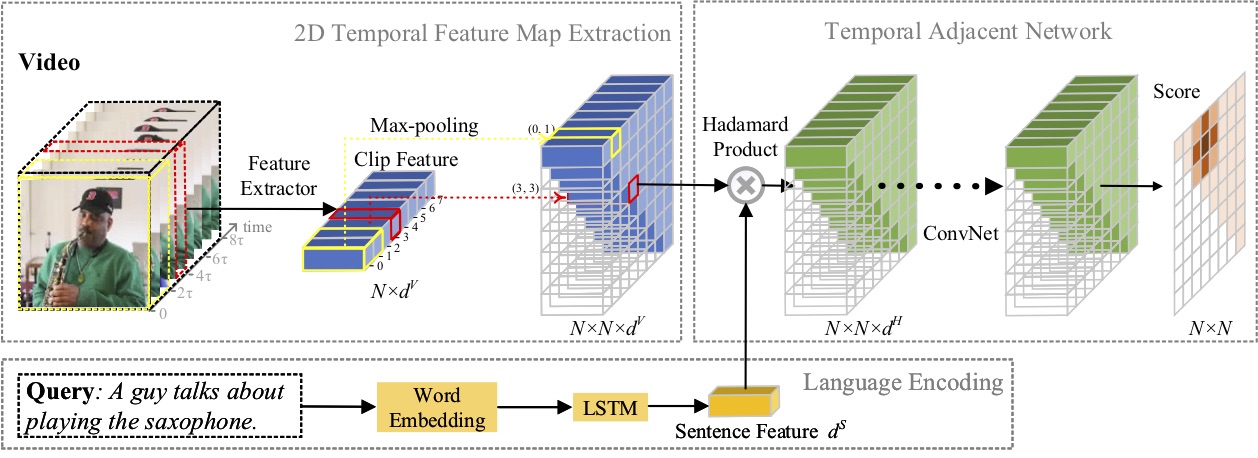
En este artículo, estudiamos el problema de la localización de momentos con lenguaje natural y proponemos un método novedoso de redes temporales adyacentes 2D (2D-TAN). La idea central es recuperar un momento en un mapa temporal bidimensional, que considera candidatos a momentos adyacentes como contexto temporal. 2D-TAN es capaz de codificar relaciones temporales adyacentes, mientras aprende funciones discriminativas para hacer coincidir momentos de video con expresiones de referencia. Nuestro modelo tiene un diseño simple y logra un rendimiento competitivo en comparación con los métodos más modernos en tres conjuntos de datos de referencia.
@InProceedings{SeqTrack, title={SeqTrack: aprendizaje de secuencia a secuencia para el seguimiento de objetos visuales}, autor={Chen, Xin y Peng, Houwen y Wang, Dong y Lu, Huchuan y Hu, Han}, título del libro={CVPR}, año={2023}}@InProceedings{XCLIP, title={Modelos preentrenados de imagen-lenguaje en expansión para el reconocimiento general de vídeo}, autor = {Ni, Bolin y Peng, Houwen y Chen, Minghao y Zhang, Songyang y Meng, Gaofeng y Fu, Jianlong y Xiang, Shiming y Ling, Haibin}, título del libro = {Conferencia europea sobre visión por computadora (ECCV)}, año ={2022}}@EnProceedings{Zhang2021MS2DTAN,
autor = {Zhang, Songyang y Peng, Houwen y Fu, Jianlong y Lu, Yijuan y Luo, Jiebo},
title = {Redes adyacentes temporales 2D multiescala para localización de momentos con lenguaje natural},
título del libro = {TPAMI},
año = {2021}}@InProceedings{2DTAN_2020_AAAI,
autor = {Zhang, Songyang y Peng, Houwen y Fu, Jianlong y Luo, Jiebo},
title = {Aprendizaje de redes adyacentes temporales 2D para la localización de momentos con lenguaje natural},
título del libro = {AAAI},
año = {2020}}Licencia bajo licencia MIT.


