open_llama
1.0.0
TL;DR : estamos lanzando nuestra vista previa pública de OpenLLaMA, una reproducción de código abierto con licencia permisiva de LLaMA de Meta AI. Estamos lanzando una serie de modelos 3B, 7B y 13B entrenados en diferentes combinaciones de datos. Nuestros pesos de modelo pueden servir como reemplazo directo de LLaMA en implementaciones existentes.
En este repositorio, presentamos una reproducción de código abierto con licencia permisiva del modelo de lenguaje grande LLaMA de Meta AI. Estamos lanzando una serie de modelos 3B, 7B y 13B entrenados en tokens 1T. Proporcionamos pesos PyTorch y JAX de modelos OpenLLaMA previamente entrenados, así como resultados de evaluación y comparación con los modelos LLaMA originales. El modelo v2 es mejor que el antiguo modelo v1 entrenado con una combinación de datos diferente.
Estamos lanzando el modelo OpenLLaMA 3Bv3, que es un modelo 3B entrenado para tokens 1T en la misma combinación de conjuntos de datos que el modelo 7Bv2.
Estamos felices de lanzar un modelo OpenLLaMA 7Bv2, que está entrenado en una combinación del conjunto de datos web refinado de Falcon, combinado con el conjunto de datos starcoder y wikipedia, arxiv y libros y stackexchange de RedPajama.
Estamos felices de lanzar nuestra versión final del token 1T de OpenLLaMA 13B. Hemos actualizado los resultados de la evaluación. Para la versión actual de los modelos OpenLLaMA, nuestro tokenizador está capacitado para fusionar múltiples espacios vacíos en uno antes de la tokenización, similar al tokenizador T5. Debido a esto, nuestro tokenizador no funcionará con tareas de generación de código (por ejemplo, HumanEval), ya que el código implica muchos espacios vacíos. Para tareas relacionadas con el código, utilice los modelos v2.
Estamos felices de lanzar nuestra versión final del token 1T de OpenLLaMA 3B y 7B. Hemos actualizado los resultados de la evaluación. También nos complace lanzar una vista previa del token 600B del modelo 13B, entrenado en colaboración con Stability AI.
Estamos felices de lanzar nuestro punto de control de token 700B para el modelo OpenLLaMA 7B y nuestro punto de control de token 600B para el modelo 3B. También hemos actualizado los resultados de la evaluación. Esperamos que el entrenamiento completo del token 1T finalice a finales de esta semana.
Después de recibir comentarios de la comunidad, descubrimos que el tokenizador de nuestra versión anterior del punto de control estaba configurado incorrectamente para que no se conservaran las nuevas líneas. Para solucionar este problema, volvimos a entrenar nuestro tokenizador y reiniciamos el entrenamiento del modelo. También observamos una menor pérdida de entrenamiento con este nuevo tokenizador.
Lanzamos los pesos en dos formatos: un formato EasyLM para usar con nuestro marco EasyLM y un formato PyTorch para usar con la biblioteca de transformadores Hugging Face. Tanto nuestro marco de entrenamiento EasyLM como los pesos de los puntos de control tienen licencia permisiva bajo la licencia Apache 2.0.
Los puntos de control de vista previa se pueden cargar directamente desde Hugging Face Hub. Tenga en cuenta que se recomienda evitar el uso del tokenizador rápido Hugging Face por ahora, ya que hemos observado que el tokenizador rápido convertido automáticamente a veces proporciona tokenizaciones incorrectas . Esto se puede lograr usando directamente la clase LlamaTokenizer o pasando la opción use_fast=False para la clase AutoTokenizer . Consulte el siguiente ejemplo de uso.
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))Para un uso más avanzado, siga la documentación de Transformers LLaMA.
El modelo se puede evaluar con lm-eval-harness. Sin embargo, debido al problema del tokenizador antes mencionado, debemos evitar el uso del tokenizador rápido para obtener los resultados correctos. Esto se puede lograr pasando use_fast=False a esta parte de lm-eval-harness, como se muestra en el siguiente ejemplo:
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)Para utilizar los pesos en nuestro marco EasyLM, consulte la documentación LLaMA de EasyLM. Tenga en cuenta que, a diferencia del modelo LLaMA original, nuestro tokenizador y pesos OpenLLaMA se entrenan completamente desde cero, por lo que ya no es necesario obtener el tokenizador y los pesos LLaMA originales.
Los modelos v1 se entrenan en el conjunto de datos de RedPajama. Los modelos v2 se entrenan en una combinación del conjunto de datos web refinado Falcon, el conjunto de datos StarCoder y la parte wikipedia, arxiv, book y stackexchange del conjunto de datos RedPajama. Seguimos exactamente los mismos pasos de preprocesamiento e hiperparámetros de entrenamiento que el artículo original de LLaMA, incluida la arquitectura del modelo, la duración del contexto, los pasos de entrenamiento, el cronograma de tasa de aprendizaje y el optimizador. La única diferencia entre nuestra configuración y la original es el conjunto de datos utilizado: OpenLLaMA emplea conjuntos de datos abiertos en lugar del utilizado por el LLaMA original.
Entrenamos los modelos en TPU-v4 en la nube utilizando EasyLM, un canal de capacitación basado en JAX que desarrollamos para entrenar y ajustar modelos de lenguaje grandes. Empleamos una combinación de paralelismo de datos normal y paralelismo de datos completamente fragmentados (también conocido como etapa 3 de ZeRO) para equilibrar el rendimiento del entrenamiento y el uso de la memoria. En general, alcanzamos un rendimiento de más de 2200 tokens/segundo/chip TPU-v4 para nuestro modelo 7B. La pérdida de entrenamiento se puede ver en la siguiente figura.
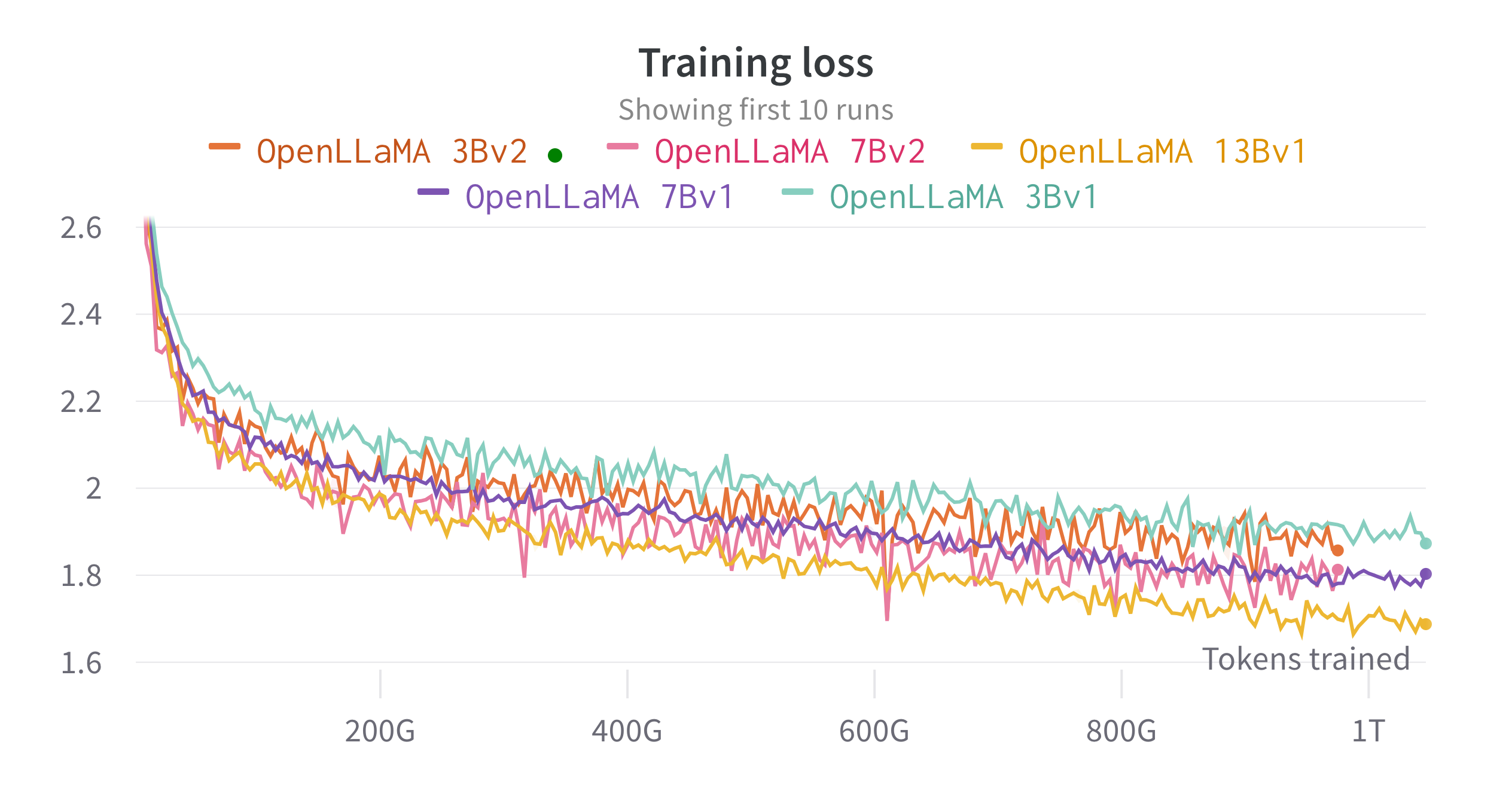
Evaluamos OpenLLaMA en una amplia gama de tareas utilizando lm-evaluación-arnés. Los resultados de LLaMA se generan ejecutando el modelo LLaMA original con las mismas métricas de evaluación. Observamos que nuestros resultados para el modelo LLaMA difieren ligeramente del artículo original de LLaMA, lo que creemos que es el resultado de diferentes protocolos de evaluación. Se han informado diferencias similares en esta edición de lm-evaluación-arnés. Además, presentamos los resultados de GPT-J, un modelo de parámetros 6B entrenado en el conjunto de datos Pile por EleutherAI.
El modelo LLaMA original fue entrenado para 1 billón de tokens y GPT-J fue entrenado para 500 mil millones de tokens. Presentamos los resultados en la siguiente tabla. OpenLLaMA exhibe un rendimiento comparable al LLaMA y GPT-J originales en la mayoría de las tareas y los supera en algunas tareas.
| Tarea/Métrica | GPT-J 6B | LLAMA 7B | LLAMA 13B | OpenLLaMA 3Bv2 | OpenLLaMA 7Bv2 | AbrirLLaMA 3B | OpenLLaMA 7B | OpenLLaMA 13B |
|---|---|---|---|---|---|---|---|---|
| anli_r1/acc | 0,32 | 0,35 | 0,35 | 0,33 | 0,34 | 0,33 | 0,33 | 0,33 |
| anli_r2/acc | 0,34 | 0,34 | 0,36 | 0,36 | 0,35 | 0,32 | 0,36 | 0,33 |
| anli_r3/acc | 0,35 | 0,37 | 0,39 | 0,38 | 0,39 | 0,35 | 0,38 | 0,40 |
| arc_challenge/acc | 0,34 | 0,39 | 0,44 | 0,34 | 0,39 | 0,34 | 0,37 | 0,41 |
| arc_challenge/acc_norm | 0,37 | 0,41 | 0,44 | 0,36 | 0,41 | 0,37 | 0,38 | 0,44 |
| arc_easy/acc | 0,67 | 0,68 | 0,75 | 0,68 | 0,73 | 0,69 | 0,72 | 0,75 |
| arc_easy/acc_norm | 0,62 | 0,52 | 0,59 | 0,63 | 0,70 | 0,65 | 0,68 | 0,70 |
| boolq/acc | 0,66 | 0,75 | 0,71 | 0,66 | 0,72 | 0,68 | 0,71 | 0,75 |
| hellaswag/acc | 0,50 | 0,56 | 0,59 | 0,52 | 0,56 | 0,49 | 0,53 | 0,56 |
| hellaswag/acc_norm | 0,66 | 0,73 | 0,76 | 0,70 | 0,75 | 0,67 | 0,72 | 0,76 |
| openbookqa/acc | 0,29 | 0,29 | 0,31 | 0,26 | 0,30 | 0,27 | 0,30 | 0,31 |
| openbookqa/acc_norm | 0,38 | 0,41 | 0,42 | 0,38 | 0,41 | 0,40 | 0,40 | 0,43 |
| piqa/acc | 0,75 | 0,78 | 0,79 | 0,77 | 0,79 | 0,75 | 0,76 | 0,77 |
| piqa/acc_norm | 0,76 | 0,78 | 0,79 | 0,78 | 0,80 | 0,76 | 0,77 | 0,79 |
| grabar/em | 0,88 | 0,91 | 0,92 | 0,87 | 0,89 | 0,88 | 0,89 | 0,91 |
| grabar/f1 | 0,89 | 0,91 | 0,92 | 0,88 | 0,89 | 0,89 | 0,90 | 0,91 |
| rte/acc | 0,54 | 0,56 | 0,69 | 0,55 | 0,57 | 0,58 | 0,60 | 0,64 |
| verazqa_mc/mc1 | 0,20 | 0,21 | 0,25 | 0,22 | 0,23 | 0,22 | 0,23 | 0,25 |
| verazqa_mc/mc2 | 0,36 | 0,34 | 0,40 | 0,35 | 0,35 | 0,35 | 0,35 | 0,38 |
| wic/acc | 0,50 | 0,50 | 0,50 | 0,50 | 0,50 | 0,48 | 0,51 | 0,47 |
| winogrande/acc | 0,64 | 0,68 | 0,70 | 0,63 | 0,66 | 0,62 | 0,67 | 0,70 |
| Promedio | 0,52 | 0,55 | 0,57 | 0,53 | 0,56 | 0,53 | 0,55 | 0,57 |
Eliminamos las tareas CB y WSC de nuestro punto de referencia, ya que nuestro modelo tiene un rendimiento sospechosamente alto en estas dos tareas. Nuestra hipótesis es que podría haber una contaminación de los datos de referencia en el conjunto de entrenamiento.
Nos encantaría recibir comentarios de la comunidad. Si tiene alguna pregunta, abra un problema o contáctenos.
OpenLLaMA es desarrollado por: Xinyang Geng* y Hao Liu* de Berkeley AI Research. *Igual contribución
Agradecemos al programa Google TPU Research Cloud por proporcionar parte de los recursos de cómputo. Nos gustaría agradecer especialmente a Jonathan Caton de TPU Research Cloud por ayudarnos a organizar los recursos informáticos, a Rafi Witten del equipo de Google Cloud y a James Bradbury del equipo de Google JAX por ayudarnos a optimizar nuestro rendimiento de capacitación. También queremos agradecer a Charlie Snell, Gautier Izacard, Eric Wallace, Lianmin Zheng y a nuestra comunidad de usuarios por las discusiones y comentarios.
El modelo OpenLLaMA 13B v1 se entrena en colaboración con Stability AI y agradecemos a Stability AI por proporcionar los recursos computacionales. Nos gustaría agradecer especialmente a David Ha y Shivanshu Purohit por coordinar la logística y brindar apoyo de ingeniería.
Si encontró útil OpenLLaMA en su investigación o aplicaciones, cítelo utilizando el siguiente BibTeX:
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


