SWE bench
1.0.0

| 日本語 | Inglés | 中文简体 | 中文繁體 |
Código y datos para nuestro artículo ICLR 2024 SWE-bench: ¿Pueden los modelos de lenguaje resolver problemas de GitHub del mundo real?
Consulte nuestro sitio web para ver la tabla de clasificación pública y el registro de cambios para obtener información sobre las últimas actualizaciones del punto de referencia SWE-bench.
SWE-bench es un punto de referencia para evaluar modelos de lenguaje grandes sobre problemas de software del mundo real recopilados de GitHub. Dada una base de código y un problema , un modelo de lenguaje tiene la tarea de generar un parche que resuelva el problema descrito.
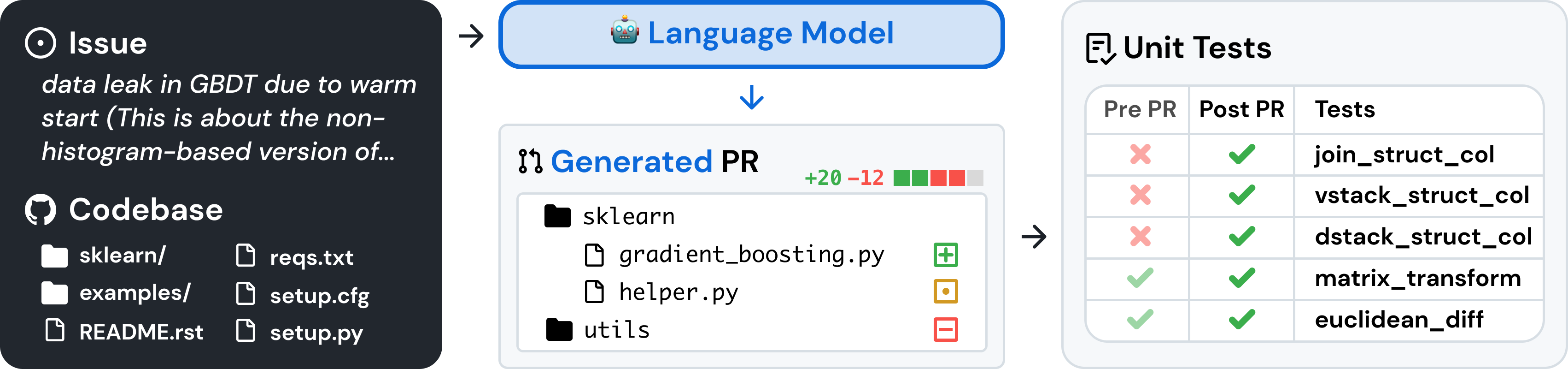
Para acceder a SWE-bench, copie y ejecute el siguiente código:
from datasets import load_dataset
swebench = load_dataset ( 'princeton-nlp/SWE-bench' , split = 'test' )SWE-bench utiliza Docker para evaluaciones reproducibles. Siga las instrucciones de la guía de configuración de Docker para instalar Docker en su máquina. Si está configurando en Linux, le recomendamos que consulte también los pasos posteriores a la instalación.
Finalmente, para construir SWE-bench desde el código fuente, siga estos pasos:
git clone [email protected]:princeton-nlp/SWE-bench.git
cd SWE-bench
pip install -e .Pruebe su instalación ejecutando:
python -m swebench.harness.run_evaluation
--predictions_path gold
--max_workers 1
--instance_ids sympy__sympy-20590
--run_id validate-goldAdvertencia
La ejecución de evaluaciones rápidas en SWE-bench puede consumir muchos recursos. Recomendamos ejecutar el arnés de evaluación en una máquina x86_64 con al menos 120 GB de almacenamiento libre, 16 GB de RAM y 8 núcleos de CPU. Es posible que deba experimentar con el argumento --max_workers para encontrar la cantidad óptima de trabajadores para su máquina, pero recomendamos usar menos de min(0.75 * os.cpu_count(), 24) .
Si lo ejecuta con Docker Desktop, asegúrese de aumentar el espacio de su disco virtual para tener ~120 GB libres disponibles y configure max_workers para que sea coherente con lo anterior para las CPU disponibles para Docker.
El soporte para máquinas arm64 es experimental.
Evalúe las predicciones del modelo en SWE-bench Lite utilizando el arnés de evaluación con el siguiente comando:
python -m swebench.harness.run_evaluation
--dataset_name princeton-nlp/SWE-bench_Lite
--predictions_path < path_to_predictions >
--max_workers < num_workers >
--run_id < run_id >
# use --predictions_path 'gold' to verify the gold patches
# use --run_id to name the evaluation run Este comando generará registros de compilación de Docker ( logs/build_images ) y registros de evaluación ( logs/run_evaluation ) en el directorio actual.
Los resultados de la evaluación final se almacenarán en el directorio evaluation_results .
Para ver la lista completa de argumentos para el arnés de evaluación, ejecute:
python -m swebench.harness.run_evaluation --helpAdemás, el repositorio SWE-Bench puede ayudarle a:
| Conjuntos de datos | Modelos |
|---|---|
| ? banco SWE | ? SWE-Llama 13b |
| ? Recuperación del "Oráculo" | ? SWE-Llama 13b (PEFT) |
| ? Recuperación BM25 13K | ? SWE-Llama 7b |
| ? Recuperación BM25 27K | ? SWE-Llama 7b (PEFT) |
| ? Recuperación BM25 40K | |
| ? BM25 Recuperación 50K (tokens Llama) |
También escribimos las siguientes publicaciones de blog sobre cómo utilizar diferentes partes de SWE-bench. Si desea ver una publicación sobre un tema en particular, háganoslo saber a través de un problema.
Nos encantaría escuchar a las comunidades de investigación más amplias de PNL, aprendizaje automático e ingeniería de software, y agradecemos cualquier contribución, solicitud de extracción o problema. Para hacerlo, presente una nueva solicitud de extracción o problema y complete las plantillas correspondientes en consecuencia. ¡Nos aseguraremos de hacer un seguimiento en breve!
Persona de contacto: Carlos E. Jiménez y John Yang (correo electrónico: [email protected], [email protected]).
Si encuentra útil nuestro trabajo, utilice las siguientes citas.
@inproceedings{
jimenez2024swebench,
title={{SWE}-bench: Can Language Models Resolve Real-world Github Issues?},
author={Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=VTF8yNQM66}
}
MIT. Consulte LICENSE.md .


