LLM4Decompile
1.0.0
![]()
Resultados | ? Modelos | Inicio rápido | HumanEval-Descompilar | ? Citación | Papel | Colaboración |
Ingeniería inversa: descompilación de código binario con modelos de lenguaje grandes
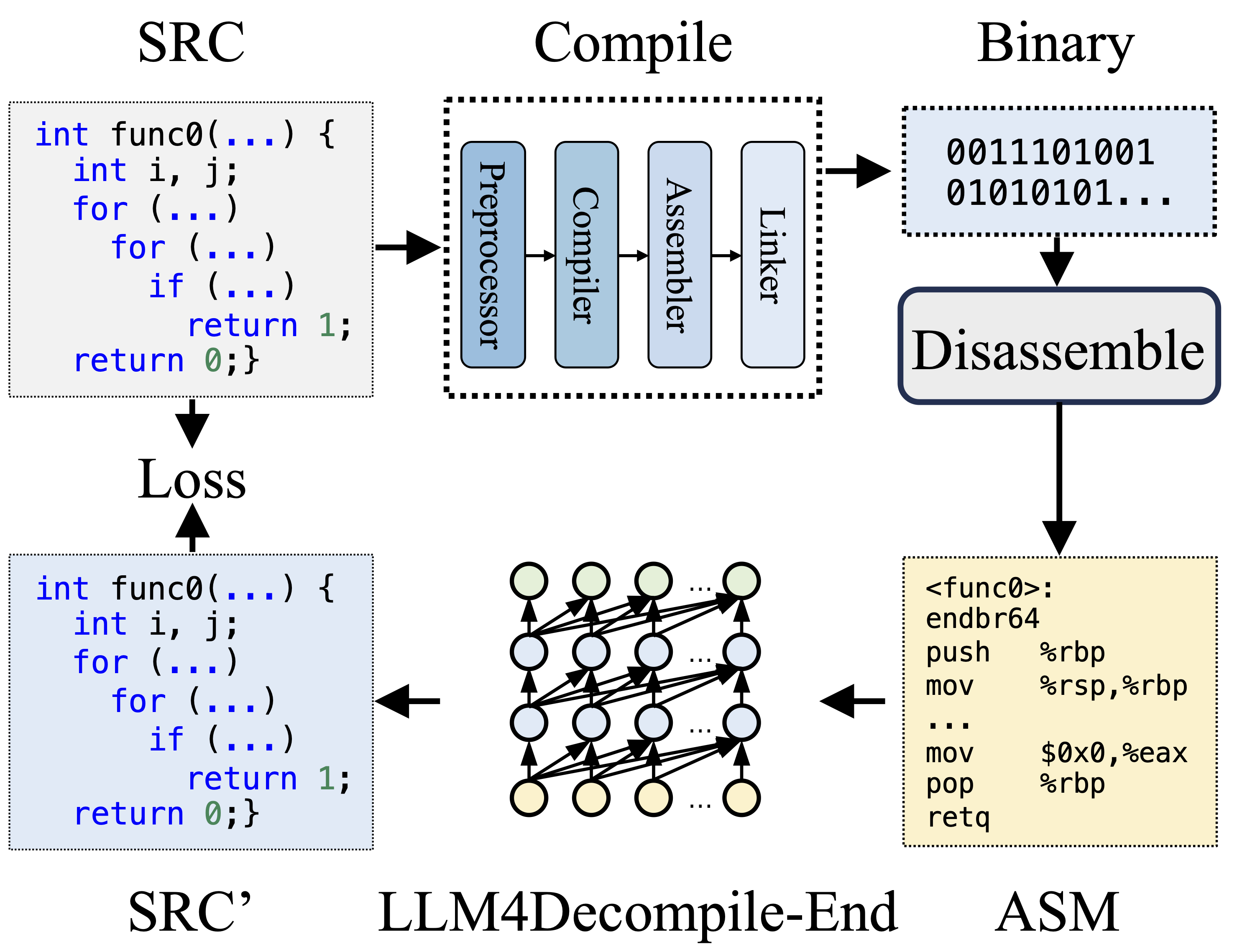
Durante la compilación, el preprocesador procesa el código fuente (SRC) para eliminar comentarios y expandir macros o inclusiones. Luego, el código limpio se envía al compilador, que lo convierte en código ensamblador (ASM). Este ASM es transformado en código binario (0s y 1s) por el Ensamblador. El vinculador finaliza el proceso vinculando llamadas a funciones para crear un archivo ejecutable. La descompilación, por otro lado, implica convertir el código binario nuevamente en un archivo fuente. Los LLM, al estar capacitados en texto, carecen de la capacidad de procesar datos binarios directamente. Por lo tanto, Objdump debe desensamblar primero los archivos binarios en lenguaje ensamblador (ASM). Cabe señalar que el ASM binario y desensamblado son equivalentes, se pueden interconvertir y, por lo tanto, nos referimos a ellos indistintamente. Finalmente, se calcula la pérdida entre el código descompilado y el código fuente para guiar el entrenamiento. Para evaluar la calidad del código descompilado (SRC'), se prueba su funcionalidad mediante afirmaciones de prueba (reejecutabilidad).
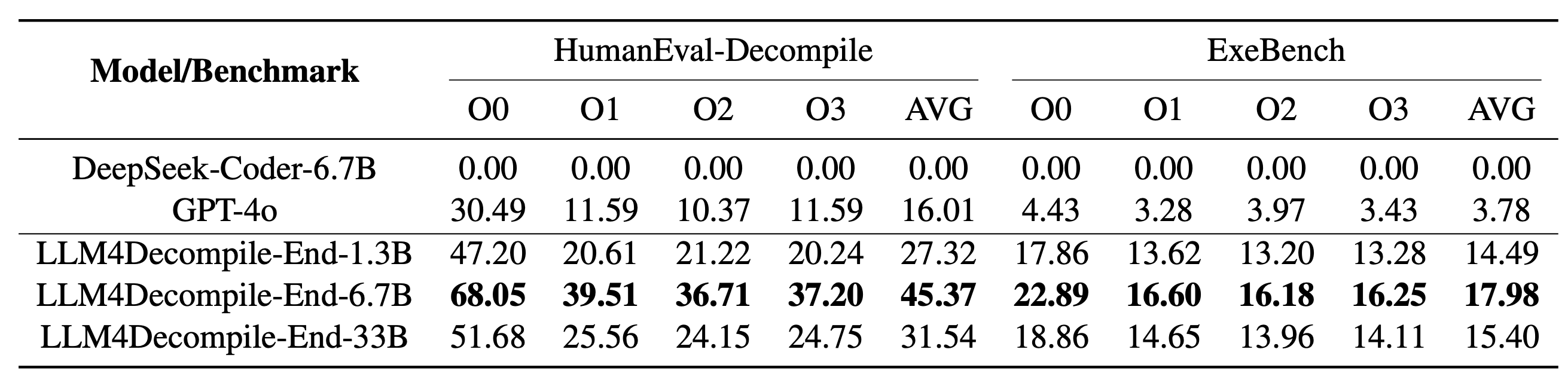
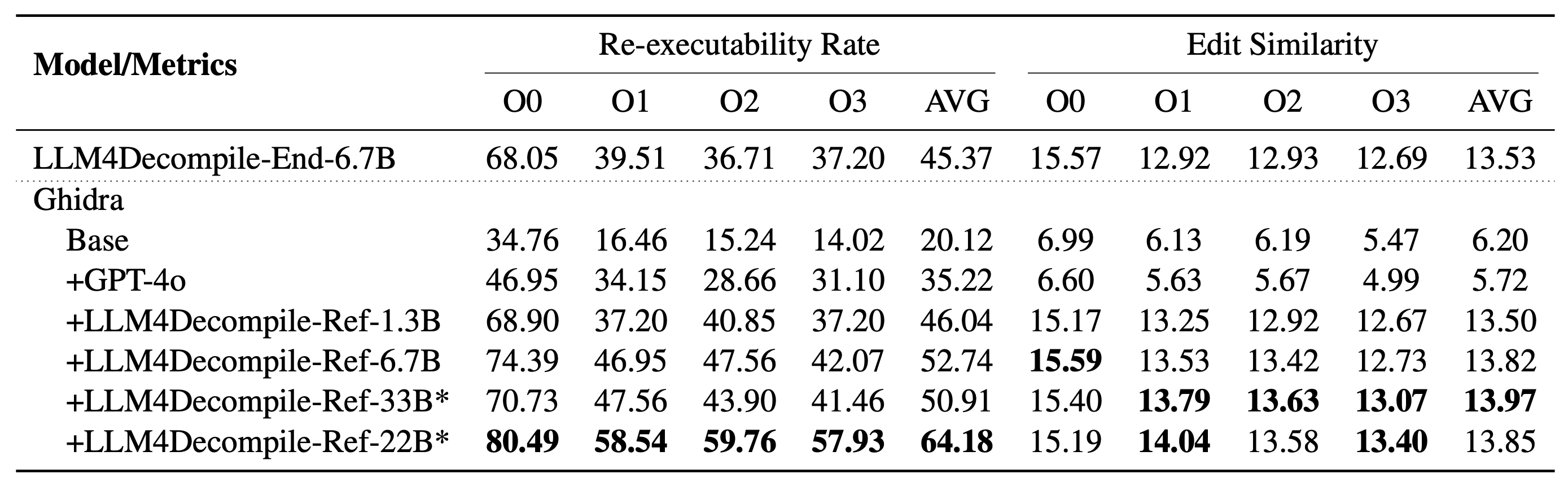
Nuestro LLM4Decompile incluye modelos con tamaños entre 1,3 mil millones y 33 mil millones de parámetros, y hemos puesto estos modelos a disposición en Hugging Face.
| Modelo | Control | Tamaño | Reejecutabilidad | Nota |
|---|---|---|---|---|
| llm4decompile-1.3b-v1.5 | ? Enlace HF | 1.3B | 27,3% | Nota 3 |
| llm4decompile-6.7b-v1.5 | ? Enlace HF | 6,7 mil millones | 45,4% | Nota 3 |
| llm4decompile-1.3b-v2 | ? Enlace HF | 1.3B | 46,0% | Nota 4 |
| llm4decompile-6.7b-v2 | ? Enlace HF | 6,7 mil millones | 52,7% | Nota 4 |
| llm4decompile-9b-v2 | ? Enlace HF | 9B | 64,9% | Nota 4 |
| llm4decompile-22b-v2 | ? Enlace HF | 22B | 63,6% | Nota 4 |
Nota 3: La serie V1.5 está entrenada con un conjunto de datos más grande (15 mil millones de tokens) y un tamaño máximo de token de 4096, con un rendimiento notable (más del 100 % de mejora) en comparación con el modelo anterior.
Nota 4: La serie V2 se basa en Ghidra y se entrena con 2 mil millones de tokens para refinar el pseudocódigo descompilado de Ghidra. Consulte la carpeta de ghidra para obtener más detalles.
Configuración: utilice el siguiente script para instalar el entorno necesario.
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
Aquí hay un ejemplo de cómo usar nuestro modelo (Revisado para V1.5. Para modelos anteriores, consulte la página del modelo correspondiente en HF). Nota: Reemplace "func0" con el nombre de la función que desea descompilar .
Preprocesamiento: compile el código C en binario y desmonte el binario en instrucciones de ensamblaje.
import subprocess
import os
func_name = 'func0'
OPT = [ "O0" , "O1" , "O2" , "O3" ]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT :
output_file = fileName + '_' + opt_state
input_file = fileName + '.c'
compile_command = f'gcc -o { output_file } .o { input_file } - { opt_state } -lm' #compile the code with GCC on Linux
subprocess . run ( compile_command , shell = True , check = True )
compile_command = f'objdump -d { output_file } .o > { output_file } .s' #disassemble the binary file into assembly instructions
subprocess . run ( compile_command , shell = True , check = True )
input_asm = ''
with open ( output_file + '.s' ) as f : #asm file
asm = f . read ()
if '<' + func_name + '>:' not in asm : #IMPORTANT replace func0 with the function name
raise ValueError ( "compile fails" )
asm = '<' + func_name + '>:' + asm . split ( '<' + func_name + '>:' )[ - 1 ]. split ( ' n n ' )[ 0 ] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm . split ( " n " )
for tmp in asm_sp :
if len ( tmp . split ( " t " )) < 3 and '00' in tmp :
continue
idx = min (
len ( tmp . split ( " t " )) - 1 , 2
)
tmp_asm = " t " . join ( tmp . split ( " t " )[ idx :]) # remove the binary code
tmp_asm = tmp_asm . split ( "#" )[ 0 ]. strip () # remove the comments
asm_clean += tmp_asm + " n "
input_asm = asm_clean . strip ()
before = f"# This is the assembly code: n " #prompt
after = " n # What is the source code? n " #prompt
input_asm_prompt = before + input_asm . strip () + after
with open ( fileName + '_' + opt_state + '.asm' , 'w' , encoding = 'utf-8' ) as f :
f . write ( input_asm_prompt )Las instrucciones de montaje deben tener el formato:
<NOMBRE_FUNCCIÓN>:nOPERACIONESnOPERACIONESn
Las instrucciones de montaje típicas pueden verse así:
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
Descompilación: utilice LLM4Decompile para traducir las instrucciones de ensamblaje a C:
from transformers import AutoTokenizer , AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer . from_pretrained ( model_path )
model = AutoModelForCausalLM . from_pretrained ( model_path , torch_dtype = torch . bfloat16 ). cuda ()
with open ( fileName + '_' + OPT [ 0 ] + '.asm' , 'r' ) as f : #optimization level O0
asm_func = f . read ()
inputs = tokenizer ( asm_func , return_tensors = "pt" ). to ( model . device )
with torch . no_grad ():
outputs = model . generate ( ** inputs , max_new_tokens = 2048 ) ### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer . decode ( outputs [ 0 ][ len ( inputs [ 0 ]): - 1 ])
with open ( fileName + '.c' , 'r' ) as f : #original file
func = f . read ()
print ( f'original function: n { func } ' ) # Note we only decompile one function, where the original file may contain multiple functions
print ( f'decompiled function: n { c_func_decompile } ' ) Los datos se almacenan en llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json , utilizando el formato de lista JSON. Hay 164*4 (O0, O1, O2, O3) muestras, cada una con cinco claves:
task_id : indica el ID del problema.type : la etapa de optimización es una de [O0, O1, O2, O3].c_func : solución C para el problema HumanEval.c_test : afirmaciones de prueba C.input_asm_prompt : instrucciones de ensamblaje con indicaciones, se pueden derivar como en nuestro ejemplo de preprocesamiento.Por favor consulte los guiones de evaluación.
Este repositorio de código tiene la licencia MIT y DeepSeek.
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


