Lovelace
velace's first appearance in these alleys.
Vaya a leer la documentación de Lovelace.
Lovelace es una aplicación web que permite la interacción gratuita con ChatGPT utilizando la biblioteca GPT4FREE de Python. El software está escrito en JavaScript, utilizando NodeJS + Express + SocketIO en el lado del servidor y Vite + ReactJS en el Frontend.
El backend permite que diferentes clientes se comuniquen con ChatGPT. Si tu propósito con Lovelace es usarlo para tus propios fines o propósitos, sólo puedes montar el servidor Backend en tu red e ignorar el otro lado de la aplicación, es decir, el cliente; el backend permite su interacción a través de la API, o puedes usar la conexión por WebSocket usando algún cliente SocketIO.
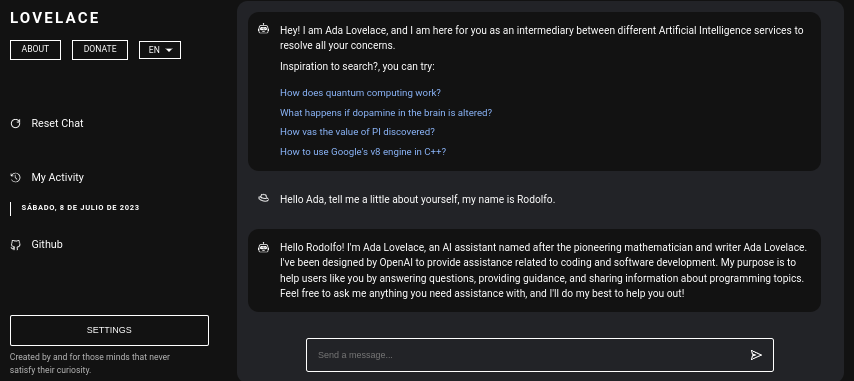
Tabla de contenido:
Instalar Lovelace en tu computadora o servidor es relativamente sencillo, no deberías tener mayores complicaciones en el proceso; sin embargo, antes de comenzar a clonar el repositorio, asegúrese de tener al menos NodeJS v18.0.0 y Python v3.10 .
Considere que, en caso de que no tenga instalada la versión requerida de NodeJS en su sistema, puede utilizar el administrador de versiones NVM (Node Version Manager) .
# Installing NVM on your system...
export NVM_DIR= " $HOME /.nvm " && (
git clone https://github.com/nvm-sh/nvm.git " $NVM_DIR "
cd " $NVM_DIR "
git checkout ` git describe --abbrev=0 --tags --match " v[0-9]* " $( git rev-list --tags --max-count=1 ) `
) && . " $NVM_DIR /nvm.sh "
# Once NVM has been installed, we proceed to install the specified NodeJS version (> 18.0.0)
nvm install 18.0.0 Si no tiene Python v3.10 en su sistema, podría considerar lo siguiente:
# (DEBIAN)
sudo add-apt-repository ppa:deadsnakes/ppa && sudo apt update && sudo apt install python3.10
# (MacOS)
brew install [email protected]De igual forma considera tener instalado pip en tu sistema, ya que será utilizado al momento de instalar los módulos necesarios para poder montar el servidor backend dentro de la red.
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3 get-pip.pyAhora, asumiendo que tienes las dependencias antes mencionadas instaladas en tu sistema, podemos continuar con el siguiente paso...
Antes de comenzar a instalar y configurar el servidor backend como frontend de Lovelace, necesitamos clonar el repositorio de Github donde se encuentra el código fuente de la aplicación.
Considera que, a estas alturas de la lectura, asumo que ya tienes la versión 3.10 o superior de Python y la versión 18.0.0 de NodeJS; En la lectura anterior, antes de proceder con la instalación, se explicaron los pasos para instalar cada uno de ellos.
# Cloning the Github repository that contains the source code (I stole it from a cyber).
git clone https://github.com/CodeWithRodi/Lovelace/ && cd Lovelace
# Accessing the "Client" folder, which stores the source code of the
# Vite + ReactjS (Frontend) application, and then installing its required modules from NPM.
cd Server && npm install --force && pip install -r Requirements.txt
# Like the previous line, we access the "Server" folder that houses the source code
# for the Lovelace Backend, then we install the NPM packages required to mount on the network.
cd ../Client && npm install --force Quizás prefieras ejecutar todo en una sola línea...
git clone https://github.com/CodeWithRodi/Lovelace/ && cd Lovelace && cd Server && npm install --force && pip install -r Requirements.txt && cd ../Client && npm install --force && cd .. Tenga en cuenta que, cuando instala los módulos necesarios para ejecutar el servidor, se ejecuta el comando pip install -r Requirements.txt para poder instalar los paquetes necesarios para poder utilizar la biblioteca GPT4FREE . de Pitón. Si no tienes pip instalado o no instalas los paquetes de Python, aunque tengas el servidor backend y el cliente montados en la red, no podrás hacer nada, porque cuando se hace una solicitud a ya sea a través de WebSocket's o vía API usando la biblioteca python-shell de NodeJS desde el backend, se realiza la comunicación al archivo Python correspondiente que se encarga de devolver la respuesta y si no tiene sus requisitos necesarios arrojará un error.
Una vez que haya clonado el repositorio de Github, podemos continuar con la configuración y el montaje en red de las aplicaciones frontend y backend; sin embargo, profundicemos un poco más en lo que almacena cada subcarpeta que contiene la carpeta generada al clonar el repositorio.
| Carpeta | Descripción |
|---|---|
| Cliente | La carpeta "Cliente" almacena el código fuente de la aplicación Vite + React, es decir, el frontend de Lovelace, donde puedes montar el sitio web en tu red para poder comunicarte con el backend y establecer conversaciones de calidad con la IA. |
| Documentación | La carpeta "Documentación" alberga el código fuente de los documentos del software: https://lovelace-docs.codewithrodi.com/. |
| Servidor | La carpeta "Servidor" alberga el código fuente del backend de Lovelace, donde se construye bajo NodeJS usando Express para proporcionar la API y SocketIO para la transmisión de respuestas bajo WebSocket. |
Además, además de las carpetas, te encontrarás con algunos archivos, que de igual forma se presentarán junto con una descripción a continuación.
| Archivo | Descripción |
|---|---|
| .clocignore | Es utilizado por el software "cloc", el cual permite contar las líneas de código del software, separándolas por tecnología y los comentarios que pueda tener el lenguaje de programación utilizado. Dentro del archivo "clocignore", están las rutas de aquellos archivos y directorios que el software debe ignorar al contar. |
| LICENCIA | Contiene la licencia Lovelace a la que están sujetos el código fuente del Cliente y del Servidor. Este software tiene la licencia MIT. |
Una vez que se haya clonado el repositorio y posteriormente haya instalado los módulos NPM de Servidor y Cliente necesarios, es hora de configurar el backend para comenzar a utilizar el software.
Comencemos con el servidor, aquí es donde sucederá la magia, podrás comunicarte con la IA a través de solicitudes API o usando WebSocket's; A continuación, se te presentará la serie de comandos para poder montar el servidor dentro de la red.
# Accessing the <Server> folder that houses the repository you cloned earlier
cd Server/
# Running the server...
npm run start Si ha hecho todo correctamente, el servidor ya debería estar ejecutándose en su sistema. ¡Puedes comprobarlo si accedes a http://0.0.0.0:8000/api/v1/ !
Secuencia de comandos ( npm run <script_name> ) | Descripción |
|---|---|
| comenzar | Comienza la ejecución normal del servidor, puedes considerar esta opción en caso de querer montarlo en producción. |
| desarrollador | Inicie la ejecución del servidor en modo de desarrollo con la ayuda del paquete "nodemon". |
Debes saber que las variables de entorno son valores de caracteres dinámicos, que te permiten almacenar información relacionada con credenciales, configuraciones, etc…, luego se te presentará el archivo ".env" ubicado dentro del código fuente del servidor, donde a su vez tendrás una descripción sobre el funcionamiento de las variables disponibles.
# Specifies the execution mode of the server, considers the value of <NODE_ENV>
# can be <development> and <production>.
NODE_ENV = production
# Address of the server where the client application is running.
CLIENT_HOST = https://lovelace.codewithrodi.com/
# Port where the server will
# start executing over the network.
SERVER_PORT = 8000
# Hostname where the server will be launched in
# complement with the previously established
# port on the network.
SERVER_HOST = 0.0.0.0
# If you have an SSL certificate, you must
# specify the certificate and then the key.
SSL_CERT =
SSL_KEY =
# Others...
CORS_ORIGIN = *
BODY_MAX_SIZE = 100kbSuponiendo que en este punto de la lectura ya tienes configurado el servidor backend en la red, podemos continuar configurando el servidor del cliente, donde, de esta manera, podrás comenzar a interactuar con la IA a través del sitio web que configurará a continuación...
La aplicación cliente está construida con ReactJS utilizando Vite como herramienta de desarrollo. ¡Con solo unos pocos comandos de terminal, puede configurar e implementar rápidamente la aplicación en su red en poco tiempo! Si sigue nuestras instrucciones y utiliza el poder de ReactJS y Vite, experimentará un proceso de configuración eficiente y sin inconvenientes.
Asegúrese de que, para poder utilizar correctamente la aplicación web, es necesario que el servidor ya esté ejecutándose en la red.
# Accessing the existing <Client> folder within the cloned repository
cd Client/
# Assuming you have already installed the necessary npm packages <npm install --force>
# we will proceed to start the server in development mode
npm run dev ¡Feliz pirateo!... Su servidor debería estar ejecutándose en http://0.0.0.0:5173/ .
De la misma forma que se hizo en la lectura anterior, a continuación se presentará la lista de variables de entorno que tiene la aplicación cliente en su archivo ".env", junto con una descripción de la misma.
# Address where the backend server was mounted, you must
# be sure to specify in the address if you have ridden
# the server under HTTPS, changing <http> to <https> ;)
VITE_SERVER = http://0.0.0.0:8000
# The server has a suffix to be able to access its respective API
# in this case we use v1
VITE_API_SUFFIX = /api/v1
# Others...
VITE_DONATE_LINK = https://ko-fi.com/codewithrodi
VITE_GPT4FREE_LINK = https://github.com/xtekky/gpt4free
VITE_SOFTWARE_REPOSITORY_LINK = https://github.com/codewithrodi/Lovelace En caso de que desee modificar la dirección de red o el puerto que se utiliza al iniciar el servidor Vite en la red, puede considerar modificar el archivo vite.config.js . Este archivo contiene los ajustes de configuración para el servidor Vite. A continuación se muestran los contenidos del archivo vite.config.js :
export default defineConfig ( {
plugins : [ react ( ) ] ,
server : {
// If you want to change the network address where the server will be mounted
// you must change <0.0.0.0> to the desired one.
host : '0.0.0.0' ,
// Following the same line above, you must modify the port <5173>
// for which you want to ride on the network.
port : 5173
} ,
define : {
global : { }
}
} ) ;Tenga en cuenta que la modificación de esta configuración debe realizarse con precaución, ya que puede afectar la accesibilidad del servidor. Asegúrese de elegir una dirección de red adecuada y un puerto que aún no esté en uso.
Vite es una opción popular para desarrollar aplicaciones web escritas en JavaScript debido a su entorno altamente eficiente. Ofrece importantes ventajas como reducir drásticamente el tiempo de inicio al cargar nuevos módulos o compilar el código fuente durante el proceso de desarrollo. Al aprovechar Vite, los desarrolladores pueden experimentar una productividad mejorada y ciclos de desarrollo más rápidos. Sus optimizaciones de velocidad y rendimiento lo convierten en una herramienta valiosa para proyectos de desarrollo web.
La aplicación web tiene la capacidad de detectar el idioma del navegador web desde el que se accede a la plataforma, para posteriormente poder detectar si existe una traducción del contenido disponible en el idioma solicitado, en caso de no existir, una La traducción será devuelta. por defecto, que corresponde al inglés.
Considere que, para agregar nuevas traducciones, puede acceder a Client/src/Locale/ , donde esta última carpeta Locale/ alberga una serie de JSON los cuales están en el siguiente formato {LANGUAGE_IN_ISO_369}.json ; En caso de querer agregar una nueva traducción, solo debes seguir el formato y copiar las claves respectivas cuyo valor se actualiza al idioma deseado que estás creando.
Actualmente, existen las siguientes traducciones dentro de la aplicación web: French - Arabic - Chinese - German - English - Spanish - Italian - Portuguese - Russian - Turkish .
Si su intención es utilizar Lovelace para sus necesidades y objetivos individuales, puede ignorar la aplicación Cliente implementada en ReactJS. En lugar de ello, desvía tu atención hacia el Servidor, ya que es donde realmente tiene lugar el encantamiento.
Tenga en cuenta que al comunicarse con el backend mediante API o WebSocket's, los datos enviados como Model or Role no distinguen entre mayúsculas y minúsculas, es decir, si el valor de Model es gPT-3.5-TUrbO no importará, ya que será formateado desde el backend, el Prompt obviamente tampoco es importante, pero sí el valor asignado a Provider , en lecturas posteriores aprenderás cómo obtener los proveedores disponibles para poder utilizar al momento de establecer una interacción con la IA, de la misma manera eso podrás saber cuáles son sus respectivos modelos, o ahora puedes acceder a la misma ruta /api/v1/chat/providers/ de la instancia pública del backend de lovelace y ver la información.
Aquí hay un ejemplo que utiliza la API a través de la función Fetch nativa:
const Data = {
// Select the model you want to use for the request.
// <GPT-3.5-Turbo> | <GPT-4>
Model : 'GPT-3.5-Turbo' , // Recommended Model
// Use a provider according to the model you used, consider
// that you can see the list of providers next to the models
// that have available in:
// [GET REQUEST]: http://lovelace-backend.codewithrodi.com/api/v1/chat/providers/
Provider : 'GetGpt' , // Recommended Provider, you can also use 'DeepAi'
// GPT Role
Role : 'User' ,
// Prompt that you will send to the model
Prompt : 'Hi Ada, Who are you?'
} ;
// Note that if you want to use your own instance replace
// <https://lovelace-backend.codewithrodi.com> for the address
// from your server, or <http://0.0.0.0:8000> in case it is
// is running locally.
const Endpoint = 'https://lovelace-backend.codewithrodi.com/api/v1/chat/completions' ;
// We will make the request with the Fetch API provided in a way
// native by JavaScript, specified in the first instance
// the endpoint where our request will be made, while as a second
// parameter we specify by means of an object the method, the header and the
// body that will have the request.
fetch ( Endpoint , {
// /api/v1/chat/completions/
method : 'POST' ,
// We are sending a JSON, we specify the format
// in the request header
headers : { 'Content-Type' : 'application/json' } ,
body : JSON . stringify ( Data )
} )
// We transform the response into JSON
. then ( ( Response ) => Response . json ( ) )
// Once the response has been transformed to the desired format, we proceed
// to display the response from the AI in the console.
. then ( ( Response ) => console . log ( Response . Data . Answer ) )
// Consider that <Response> has the following structure
// Response -> { Data: { Answer: String }, Status: String(Success | ClientError) }
. catch ( ( RequestError ) => console . error ( RequestError ) ) ;En caso de que quieras utilizar Axios al realizar la comunicación, puedes considerar:
const Axios = require ( 'axios' ) ;
const Data = {
Model : 'GPT-3.5-Turbo' , // Recommended Model
Provider : 'GetGpt' , // Recommended Provider, you can also use 'DeepAi'
// GPT Role
Role : 'User' ,
Prompt : 'Hi Ada, Who are you?'
} ;
const Endpoint = 'https://lovelace-backend.codewithrodi.com/api/v1/chat/completions' ;
( async function ( ) {
const Response = ( await Axios . post ( Endpoint , Data , { headers : { 'Content-Type' : 'application/json' } } ) ) . data ;
console . log ( Response . Data . Answer ) ;
} ) ( ) ; Puede ver cómo el cliente se comunica con el backend a través de la API mirando los archivos Client/src/Services/Chat/Context.jsx y Client/src/Services/Chat/Service.js , donde ocurre la magia.
Desde el servidor backend se proporciona un servidor WebSocket con ayuda de SocketIO, por lo que se recomienda utilizar un cliente proporcionado por la misma biblioteca, como npm i socket.io-client en el caso de NodeJS. Se recomienda utilizar este tipo de comunicación si se desea una respuesta "instantánea", ya que la respuesta de la IA, a diferencia de utilizar la comunicación vía API, no se debe esperar a que la IA termine de procesar la respuesta para poder ser mostrada. . . Utilizando WebSocket's la respuesta de la IA se transmite por partes, generando una interacción con el cliente al instante.
const { io } = require ( 'socket.io-client' ) ;
// Using the NodeJS 'readline' module, like this
// allow <Prompts> to be created by the user
// to our console application.
const ReadLine = require ( 'readline' ) . createInterface ( {
input : process . stdin ,
output : process . stdout
} ) ;
// We store the address where the Lovelace backend is mounted.
// In case your instance is running locally
// you can change the value of <Endpoint> to something like <http://0.0.0.0:8000>.
const Endpoint = 'http://lovelace-backend.codewithrodi.com/' ;
( async function ( ) {
const Socket = io ( Endpoint ) . connect ( ) ;
console . log ( `Connecting to the server... [ ${ Endpoint } ]` ) ;
Socket . on ( 'connect' , ( ) => {
console . log ( 'Connected, happy hacking!' ) ;
RunApplicationLoop ( ) ;
} ) ;
Socket . on ( 'disconnect' , ( ) => {
console . log ( 'nDisconnected, bye bye...!' ) ;
process . exit ( 0 ) ;
} ) ;
// We use <process.stdout.write(...)> instead of <console.log(...)> because
// in this way we print directly to the console without each time
// that a part of the response is received, a new line (n) is executed.
Socket . on ( 'Response' , ( StreamedAnswer ) => process . stdout . write ( StreamedAnswer ) ) ;
const BaseQuery = {
// We indicate the model that we want to use to communicate with the AI
// 'GPT-3.5-Turbo' - 'GPT-4'
Model : 'GPT-3.5-Turbo' ,
// Provider to use in the communication, keep in mind that not all
// providers offer ChatGPT 3.5 or ChatGPT 4. You can make a request
// [GET] to <https://lovelace-backend.codewithrodi.com/api/v1/chat/providers/>
Provider : 'GetGpt' ,
Role : 'User' ,
} ;
const HandleClientPrompt = ( ) => new Promise ( ( Resolve , Reject ) => {
const HandleStreamedResponseEnd = ( MaybeError ) => {
if ( MaybeError ) {
return Reject ( MaybeError ) ;
}
Resolve ( ) ;
} ;
ReadLine . question ( 'Prompt > ' , ( Prompt ) => {
// We issue <Prompt> to the server, where as the second parameter
// send the Query to it, specifying the Model, Provider, Role and Prompt.
// The last parameter corresponds to the Callback that will be called
// once the transmission of the response is finished, consider that this
// callback receives a parameter, which corresponds to whether there is an error
// or not during transmission, its content is therefore the error.
Socket . emit ( 'Prompt' , { Prompt , ... BaseQuery } , HandleStreamedResponseEnd ) ;
} ) ;
} ) ;
const RunApplicationLoop = async ( ) => {
while ( true ) {
await HandleClientPrompt ( ) ;
console . log ( 'n' ) ;
}
} ;
} ) ( ) ; Si deseas establecer comunicación con el Backend de Lovelace a través de WebSocket's en otro idioma distinto al presentado, puedes considerar:
Tenga en cuenta que, a pesar de que dentro del backend se utiliza la biblioteca Python GPT4FREE , los proveedores de esta última son diferentes a los que ofrece Lovelace. Podrás obtener el listado de proveedores disponibles utilizando la API, donde obtendrás información como los modelos que permite utilizar, la dirección web donde se aloja el servicio y el nombre que se debe especificar al interactuar con la IA como has visto en los ejemplos. anterior (API, WS).
La respuesta que deberías recibir de https://lovelace-backend.codewithrodi.com/api/v1/chat/providers/ debería ser:
{
"Status" : " Success " ,
"Data" :{
"Providers" :{
// List of providers available to use on WebSocket's
"WS" :[
{
// Name to specify when making the query
"Name" : " DeepAi " ,
// Web address where the service is hosted
"Website" : " https://deepai.org " ,
// Available models
"Models" :[ " gpt-3.5-turbo " ]
},
// ! Others WebSocket's providers...
{ "Name" : " Theb " , "Website" : " https://theb.ai " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " Yqcloud " , "Website" : " https://chat9.yqcloud.top/ " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " You " , "Website" : " https://you.com " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " GetGpt " , "Website" : " https://chat.getgpt.world/ " , "Models" :[ " gpt-3.5-turbo " ] }
],
// List of Providers available to be able to use through the API
"API" :[
{
// Name to specify when making the query
"Name" : " Aichat " ,
// Web address where the service is hosted
"Website" : " https://chat-gpt.org/chat " ,
// Available models
"Models" :[ " gpt-3.5-turbo " ]
},
// ! Others API providers...
{ "Name" : " ChatgptLogin " , "Website" : " https://chatgptlogin.ac " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " DeepAi " , "Website" : " https://deepai.org " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " Yqcloud " , "Website" : " https://chat9.yqcloud.top/ " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " You " , "Website" : " https://you.com " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " GetGpt " , "Website" : " https://chat.getgpt.world/ " , "Models" :[ " gpt-3.5-turbo " ] }
]
}
}
}Como has visto, la lista de proveedores se divide en 2 partes, una para aquellas consultas realizadas a través de la API y otra para las que utilizan WebSocket's.
A diferencia de otros ejemplos donde están involucradas solicitudes al servidor backend de Lovelace, obtener la lista de proveedores y sus respectivos modelos disponibles es una tarea bastante sencilla, ya que sólo debemos enviar una solicitud [GET] a /api/v1 /chat/providers/ , donde la respuesta será el JSON que se te mostró anteriormente.
Para el siguiente ejemplo, usaremos Axios dentro de NodeJS, que puede instalar usando el administrador de paquetes NPM usando el comando npm i axios .
const Axios = require ( 'axios' ) ;
( async function ( ) {
// Consider that, you can replace <https://lovelace-backend.codewithrodi.com> with
// the address where your backend server is mounted. If t

