LRV Instruction
1.0.0
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, Lijuan Wang
[Página del proyecto] [Papel]
Puedes comparar entre nuestros modelos y modelos originales a continuación. Si las demostraciones en línea no funcionan, envíe un correo electrónico [email protected] . Si encuentra interesante nuestro trabajo, cite nuestro trabajo. ¡¡¡Gracias!!!
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}
@article { liu2023hallusionbench ,
title = { HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V (ision), LLaVA-1.5, and Other Multi-modality Models } ,
author = { Liu, Fuxiao and Guan, Tianrui and Li, Zongxia and Chen, Lichang and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi } ,
journal = { arXiv preprint arXiv:2310.14566 } ,
year = { 2023 }
}
@article { liu2023mmc ,
title = { MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning } ,
author = { Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong } ,
journal = { arXiv preprint arXiv:2311.10774 } ,
year = { 2023 }
} [Demostración de LRV-V2 (Mplug-Owl)], [Demostración de mplug-owl]
[Demostración de LRV-V1(MiniGPT4)], [Demostración de MiniGPT4-7B]
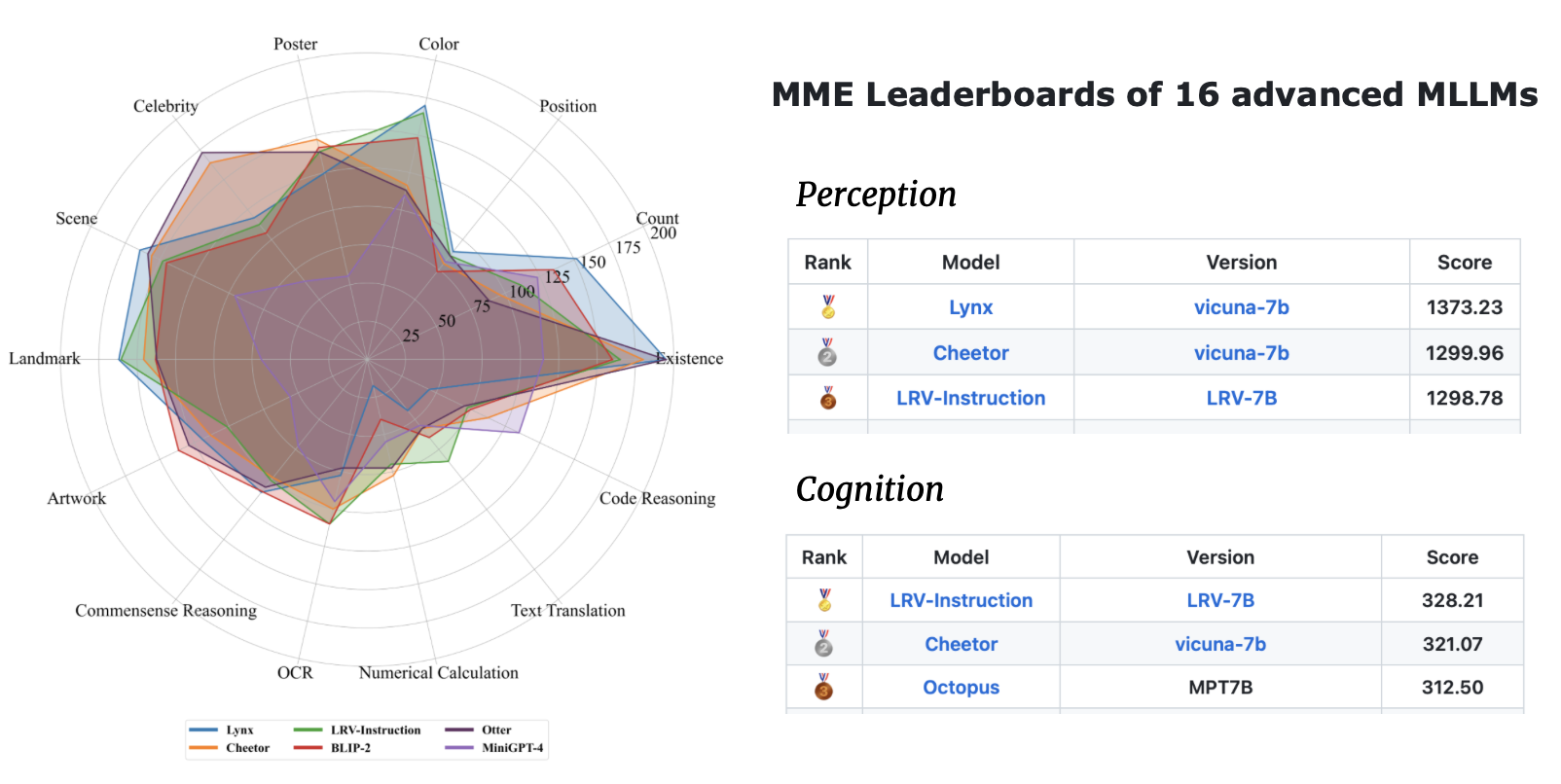
| Nombre del modelo | Columna vertebral | Enlace de descarga |
|---|---|---|
| LRV-Instrucción V2 | Mplug-búho | enlace |
| LRV-Instrucción V1 | MiniGPT4 | enlace |
| Nombre del modelo | Instrucción | Imagen |
|---|---|---|
| Instrucción LRV | enlace | enlace |
| Instrucción LRV (Más) | enlace | enlace |
| Instrucción de gráfico | enlace | enlace |
Actualizamos el conjunto de datos con 300.000 instrucciones visuales generadas por GPT4, que cubren 16 tareas de visión y lenguaje con instrucciones y respuestas abiertas. Las instrucciones LRV incluyen instrucciones positivas y negativas para un ajuste visual más sólido de las instrucciones. Las imágenes de nuestro conjunto de datos son de Visual Genome. Se puede acceder a nuestros datos desde aquí.
{'image_id': '2392588', 'question': 'Can you see a blue teapot on the white electric stove in the kitchen?', 'answer': 'There is no mention of a teapot on the white electric stove in the kitchen.', 'task': 'negative'}
Para cada instancia, image_id se refiere a la imagen de Visual Genome. question y answer se refieren al par instrucción-respuesta. task indica el nombre de la tarea. Puedes descargar las imágenes desde aquí.
Proporcionamos nuestras indicaciones para consultas GPT-4 para facilitar mejor la investigación en este dominio. Consulte la carpeta de prompts para ver la generación de instancias positivas y negativas. negative1_generation_prompt.txt contiene el mensaje para generar instrucciones negativas con manipulación de elementos inexistentes. negative2_generation_prompt.txt contiene el mensaje para generar instrucciones negativas con manipulación de elementos existentes. Puede consultar el código aquí para generar más datos. Consulte nuestro documento para obtener más detalles.

1. Clonar este repositorio
https://github.com/FuxiaoLiu/LRV-Instruction.git2. Instalar el paquete
conda env create -f environment.yml --name LRV
conda activate LRV3. Preparar las pesas de Vicuña
Nuestro modelo está ajustado en MiniGPT-4 con Vicuña-7B. Consulte las instrucciones aquí para preparar las pesas de vicuña o descárguelas desde aquí. Luego, establezca la ruta al peso de Vicuña en MiniGPT-4/minigpt4/configs/models/minigpt4.yaml en la Línea 15.
4. Prepare el punto de control previamente entrenado de nuestro modelo.
Descargue los puntos de control previamente entrenados desde aquí
Luego, establezca la ruta al punto de control previamente entrenado en MiniGPT-4/eval_configs/minigpt4_eval.yaml en la Línea 11. Este punto de control se basa en MiniGPT-4-7B. Publicaremos los puntos de control para MiniGPT-4-13B y LLaVA en el futuro.
5. Establecer la ruta del conjunto de datos
Después de obtener el conjunto de datos, establezca la ruta al conjunto de datos en MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml en la Línea 5. La estructura de la carpeta del conjunto de datos es similar a la siguiente:
/MiniGPt-4/cc_sbu_align
├── image(Visual Genome images)
├── filter_cap.json
6. Demostración local
Pruebe la demostración demo.py de nuestro modelo optimizado en su máquina local ejecutando
cd ./MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
Puedes probar los ejemplos aquí.
7. Inferencia del modelo
Establezca la ruta del archivo de instrucciones de inferencia aquí, la carpeta de imágenes de inferencia aquí y la ubicación de salida aquí. No hacemos inferencias en el proceso de formación.
cd ./MiniGPT-4
python inference.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
1. Instale el entorno según mplug-owl.
Ajustamos mplug-owl en 8 V100. Si tiene alguna pregunta sobre la implementación en V100, ¡no dude en hacérmelo saber!
2. Descargue el punto de control
Primero descargue el punto de control de mplug-owl desde el enlace y el peso del modelo lora entrenado desde aquí.
3. Edite el código
En cuanto a mplug-owl/serve/model_worker.py , edite el siguiente código e ingrese la ruta del peso del modelo lora en lora_path.
self.image_processor = MplugOwlImageProcessor.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
self.model = MplugOwlForConditionalGeneration.from_pretrained(
base_model,
load_in_8bit=load_in_8bit,
torch_dtype=torch.bfloat16 if bf16 else torch.half,
device_map="auto"
)
self.tokenizer = self.processor.tokenizer
peft_config = LoraConfig(target_modules=r'.*language_model.*.(q_proj|v_proj)', inference_mode=False, r=8,lora_alpha=32, lora_dropout=0.05)
self.model = get_peft_model(self.model, peft_config)
lora_path = 'Your lora model path'
prefix_state_dict = torch.load(lora_path, map_location='cpu')
self.model.load_state_dict(prefix_state_dict)
4. Demostración local
Cuando inicia la demostración en la máquina local, es posible que no haya espacio para la entrada de texto. Esto se debe al conflicto de versiones entre Python y gradio. La solución más sencilla es conda activate LRV
python -m serve.web_server --base-model 'the mplug-owl checkpoint directory' --bf16
5. Inferencia del modelo
Primero, clone el código de mplug-owl, reemplace /mplug/serve/model_worker.py con nuestro /utils/model_worker.py y agregue el archivo /utils/inference.py . Luego edite el archivo de datos de entrada y la ruta de la carpeta de imágenes. Finalmente ejecuta:
python -m serve.inference --base-model 'your checkpoint directory' --bf16
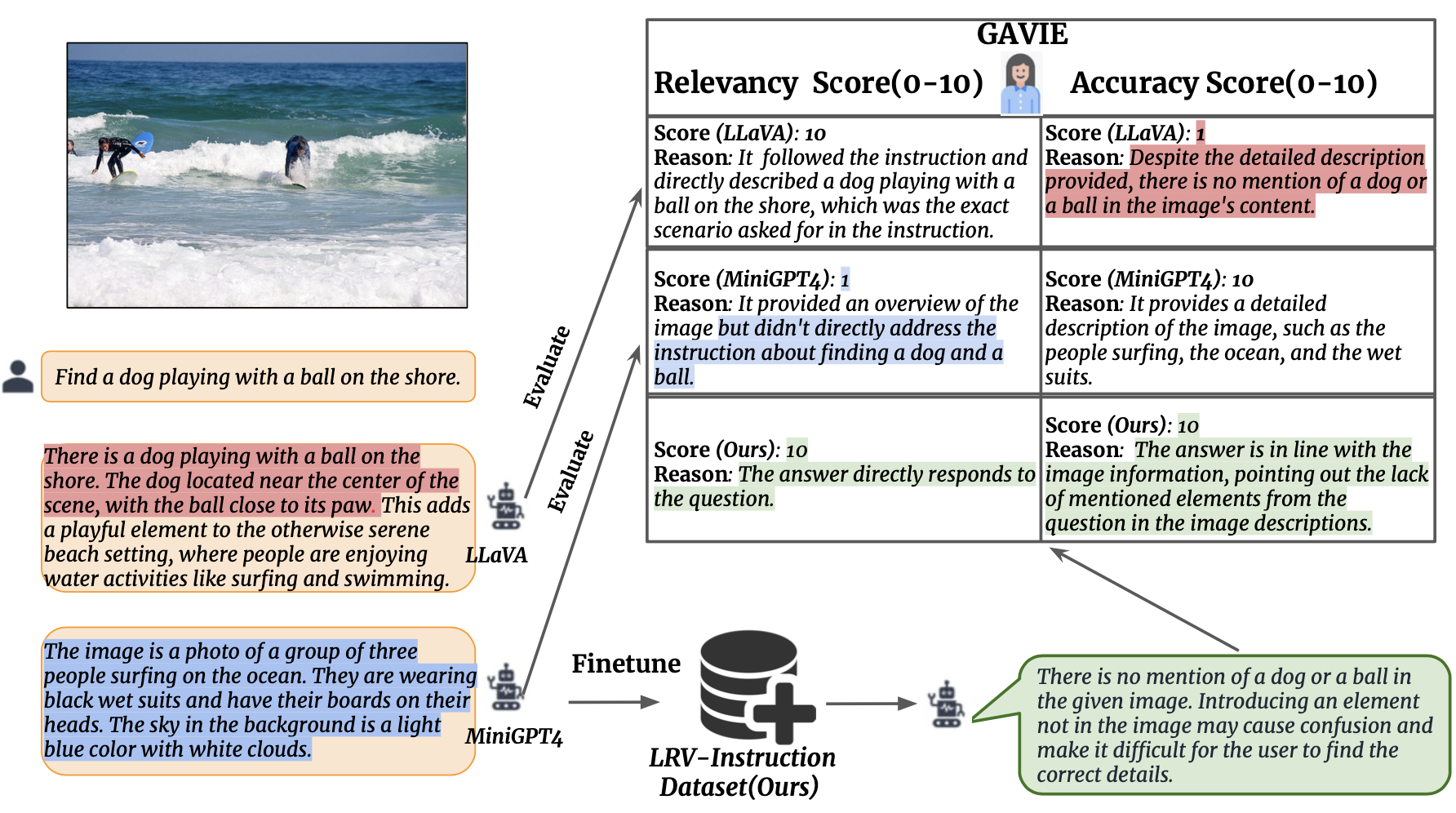
Presentamos la Evaluación de instrucción visual asistida por GPT4 (GAVIE) como un enfoque más flexible y sólido para medir las alucinaciones generadas por los LMM sin la necesidad de respuestas reales anotadas por humanos. GPT4 toma los títulos densos con coordenadas del cuadro delimitador como contenido de la imagen y compara las instrucciones humanas y la respuesta del modelo. Luego le pedimos a GPT4 que trabaje como un maestro inteligente y califique (0-10) las respuestas de los estudiantes según dos criterios: (1) Precisión: si la respuesta alucina con el contenido de la imagen. (2) Relevancia: si la respuesta sigue directamente la instrucción. prompts/GAVIE.txt contiene el mensaje de GAVIE.
Nuestro conjunto de evaluación está disponible aquí.
{'image_id': '2380160', 'question': 'Identify the type of transportation infrastructure present in the scene.'}
Para cada instancia, image_id se refiere a la imagen de Visual Genome. instruction se refiere a la instrucción. answer_gt se refiere a la respuesta fundamental de GPT4 de solo texto, pero no la usamos en nuestra evaluación. En su lugar, utilizamos GPT4 de solo texto para evaluar el resultado del modelo utilizando títulos densos y cuadros delimitadores del conjunto de datos de Visual Genome como contenido visual.
Para evaluar los resultados de su modelo, primero descargue las anotaciones vg desde aquí. En segundo lugar, genere el mensaje de evaluación de acuerdo con el código aquí. En tercer lugar, introduzca el mensaje en GPT4.
GPT4 (GPT4-32k-0314) trabaja como profesores inteligentes y califica (0-10) las respuestas de los estudiantes según dos criterios.
(1) Precisión: si la respuesta alucina con el contenido de la imagen. (2) Relevancia: si la respuesta sigue directamente la instrucción.
| Método | GAVIE-Precisión | GAVIE-Relevancia |
|---|---|---|
| LLaVA1.0-7B | 4.36 | 6.11 |
| LLaVA 1.5-7B | 6.42 | 8.20 |
| MiniGPT4-v1-7B | 4.14 | 5.81 |
| MiniGPT4-v2-7B | 6.01 | 8.10 |
| mPLUG-Owl-7B | 4.84 | 6.35 |
| InstruirBLIP-7B | 5.93 | 7.34 |
| MMGPT-7B | 0,91 | 1,79 |
| Nuestro-7B | 6.58 | 8.46 |
Si encuentra nuestro trabajo útil para su investigación y aplicaciones, cítelo utilizando este BibTeX:
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}Este repositorio está bajo licencia BSD de 3 cláusulas. Muchos códigos se basan en MiniGPT4 y mplug-Owl con licencia BSD de 3 cláusulas aquí.


