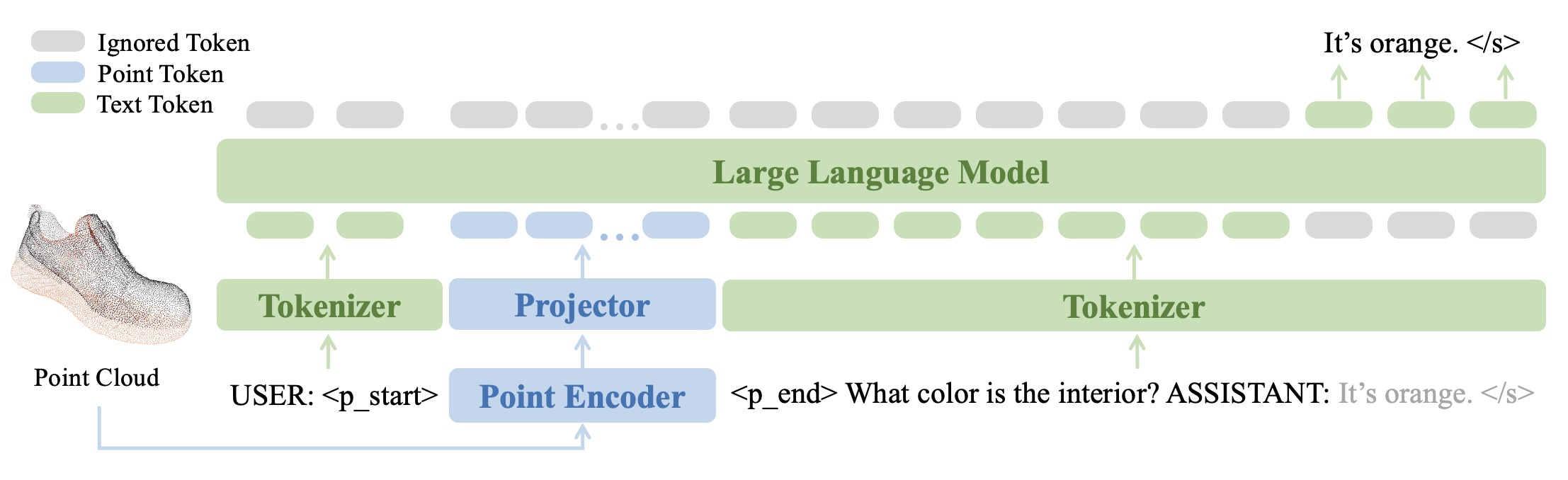
PointLLM
1.0.0
 PointLLM: potenciar modelos de lenguaje grandes para comprender las nubes de puntos
PointLLM: potenciar modelos de lenguaje grandes para comprender las nubes de puntos Runsen Xu Xiaolong Wang Tai Wang Yilun Chen Jiangmiao Pang* Dahua Lin
Universidad China de Hong Kong Laboratorio de IA de Shanghai Universidad de Zhejiang

¡PointLLM está en línea! Pruébelo en http://101.230.144.196 o en OpenXLab/PointLLM.
¡Puedes chatear con PointLLM sobre los modelos del conjunto de datos Objaverse o sobre tus propias nubes de puntos!
¡No dude en contarnos si tiene algún comentario! ?
| Diálogo 1 | Diálogo 2 | Diálogo 3 | Diálogo 4 |
|---|---|---|---|
 |  |  |  |
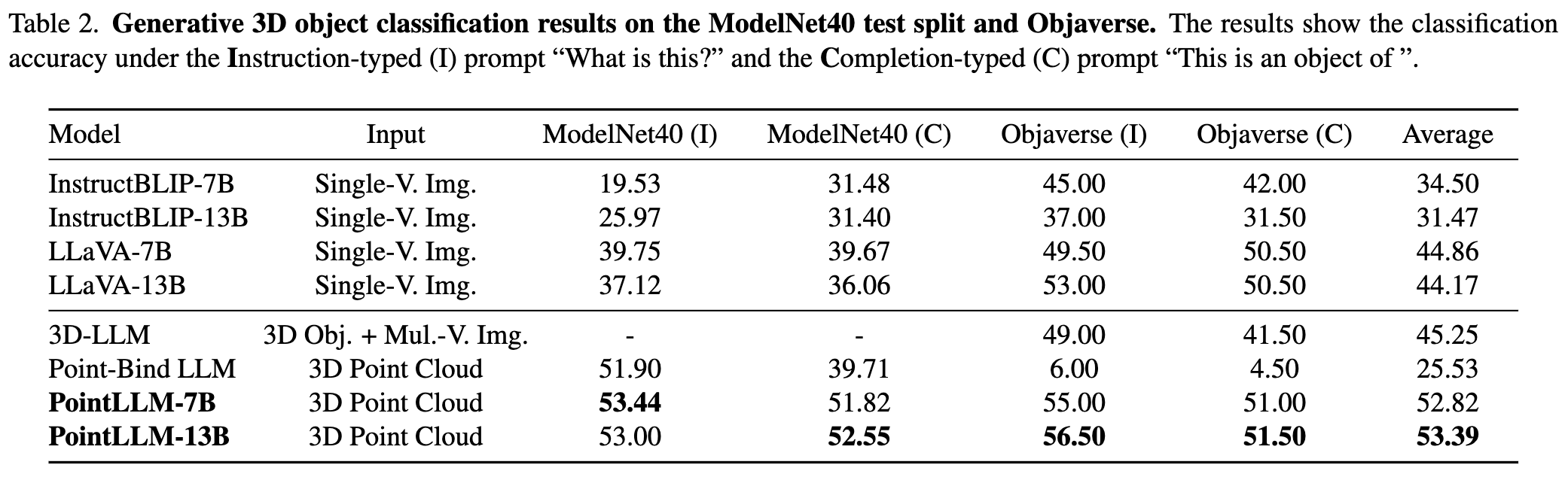
Consulte nuestro artículo para obtener más resultados.
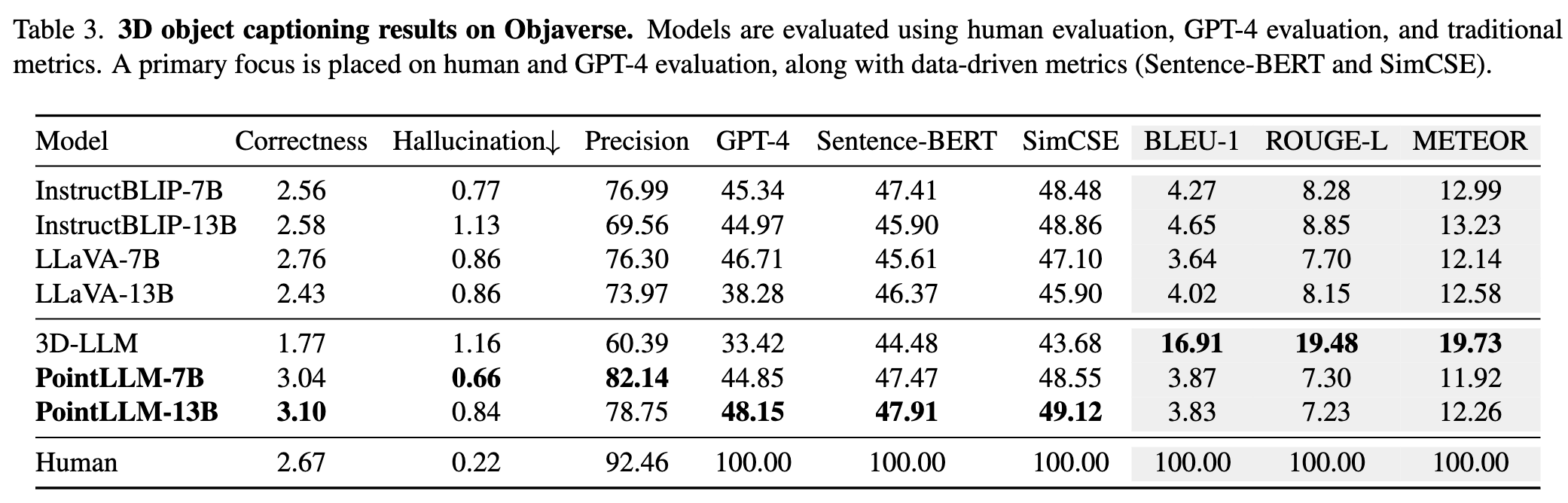
Consulte nuestro artículo para obtener más resultados.

Probamos nuestros códigos en el siguiente entorno:
Para empezar:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn8192_npy que contiene archivos de nube de puntos de 660K llamados {Objaverse_ID}_8192.npy . Cada archivo es una matriz numerosa con dimensiones (8192, 6), donde las primeras tres dimensiones son xyz y las últimas tres dimensiones son rgb en el rango [0, 1]. cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM , cree una carpeta data y cree un enlace suave al archivo sin comprimir en el directorio. cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data , cree un directorio llamado anno_data .anno_data . El directorio debería verse así: PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json se filtra de PointLLM_brief_description_660K.json eliminando los 3000 objetos que reservamos como conjunto de validación. Si desea reproducir los resultados de nuestro artículo, debe utilizar PointLLM_brief_description_660K_filtered.json para la capacitación. PointLLM_complex_instruction_70K.json contiene objetos del conjunto de entrenamiento.pointllm/data/data_generation/system_prompt_gpt4_0613.txt . PointLLM_brief_description_val_200_GT.json que usamos para los puntos de referencia en el conjunto de datos Objaverse y colóquelo en PointLLM/data/anno_data . También proporcionamos aquí los 3000 identificadores de objetos que filtramos durante el entrenamiento y su correspondiente GT de referencia aquí, que se puede utilizar para evaluar los 3000 objetos.modelnet40_data en PointLLM/data . Descargue la división de prueba de las nubes de puntos ModelNet40 modelnet40_test_8192pts_fps.dat aquí y colóquela en PointLLM/data/modelnet40_data .PointLLM , cree un directorio llamado checkpoints .checkpoints . cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.shPor lo general, no es necesario que se preocupe por los siguientes contenidos. Son solo para reproducir los resultados en nuestro artículo v1 (PointLLM-v1.1). Si desea comparar con nuestros modelos o utilizar nuestros modelos para tareas posteriores, utilice PointLLM-v1.2 (consulte nuestro documento v2), que tiene un mejor rendimiento.
PointLLM v1.1 y v1.2 utilizan proyectores y codificadores de puntos previamente entrenados ligeramente diferentes. Si desea reproducir PointLLM v1.1, edite el archivo config.json en el directorio de LLM inicial y pesos del codificador de puntos, por ejemplo, vim checkpoints/PointLLM_7B_v1.1_init/config.json .
Cambie la clave "point_backbone_config_name" para especificar otra configuración del codificador de puntos:
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1 Edite la ruta del punto de control del codificador de puntos en scripts/train_stage1.sh :
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32 para conversar sobre modelos 3D de Objaverse. Los puntos de control del modelo se descargarán automáticamente. También puede descargar manualmente los puntos de control del modelo y especificar sus rutas. Aquí hay un ejemplo: cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32 También puede modificar fácilmente los códigos para usar nubes de puntos distintas a las de Objaverse, siempre que las nubes de puntos ingresadas al modelo tengan dimensiones (N, 6), donde las primeras tres dimensiones sean xyz y las últimas tres dimensiones sean rgb ( en el rango [0, 1]). Puede tomar muestras de las nubes de puntos para obtener 8192 puntos, ya que nuestro modelo está entrenado en dichas nubes de puntos.
La siguiente tabla muestra los requisitos de GPU para diferentes modelos y tipos de datos. Recomendamos utilizar torch.bfloat16 si corresponde, que se utiliza en los experimentos de nuestro artículo.
| Modelo | Tipo de datos | Memoria GPU |
|---|---|---|
| PuntoLLM-7B | antorcha.float16 | 14GB |
| PuntoLLM-7B | antorcha.float32 | 28GB |
| PuntoLLM-13B | antorcha.float16 | 26GB |
| PuntoLLM-13B | antorcha.float32 | 52GB |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation como un dictado con el siguiente formato: {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C . Esto guardará los resultados temporales. Si ocurre un error durante la evaluación, el script también guardará el estado actual. Puede reanudar la evaluación desde donde la dejó ejecutando el mismo comando nuevamente.{model_name}/evaluation como otro dictado. Algunas de las métricas se explican a continuación: " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_eval y especificando --gpt_type . Por ejemplo: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_output¿¡Las contribuciones de la comunidad son bienvenidas!? Si necesita ayuda, no dude en abrir un problema o contactarnos.
Si encuentra útil nuestro trabajo y este código base, considere destacar este repositorio. y citar:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
Este trabajo se encuentra bajo la Licencia Internacional Creative Commons Atribución-No Comercial-CompartirIgual 4.0.
¡Juntos, hagamos que el LLM para 3D sea grandioso!


