Guía integral de difusión estable: de novato a experto
Me interesé en utilizar SD para generar imágenes para aplicaciones militares. La mayoría de los recursos se toman de los foros NSFW de 4chan, ya que los anons usan SD para hacer hentai. Curiosamente, la SD WebUI canónica tiene una funcionalidad incorporada con tableros de imágenes de anime/hentai... Uno de los primeros casos de uso de SD justo después de que DALL-E generara chicas anime, por lo que el salto al hentai no es sorprendente.
De todos modos, las técnicas de estos bichos raros son aplicables a una variedad de aplicaciones, más específicamente a los LoRA, que son como afinadores de modelos. La idea es trabajar con LoRA específicos (por ejemplo, vehículos militares, aviones, armas, etc.) para generar datos de imágenes sintéticas para entrenar modelos de visión. También es de interés formar LoRA nuevos y útiles. Las cosas posteriores pueden incluir pintura para perturbar.
Descargo de responsabilidad y fuentes
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
¡Juega con él!
¿Qué puedes hacer realmente con SD? Huggingface y algunos otros tienen algunas aplicaciones en el navegador para ti. ¡Juega con ellos para ver el poder! Lo que haremos en esta guía es obtener la WebUI completa y extensible que nos permita hacer lo que queramos.
- Huggingface Texto a imagen SD Playground
- Aplicación Dreamstudio Texto a Imagen SD
- Aplicación Dezgo Texto a Imagen SD
- Huggingface Imagen a Imagen SD Playground
- Abrazando la cara en el patio de recreo
Tabla de contenido
- Conceptos básicos de la interfaz de usuario web
- Configurar el uso de GPU local
- Configuración de Linux
- Profundizando
- Incitación
- Modelo novedoso de IA
- lora
- Jugando con modelos
- VAEs
- Ponlo todo junto
- El proceso general de SD
- Mensajes de guardado
- Configuración de txt2img
- Regenerar una imagen generada previamente
- Solución de errores
- Ponerse cómodo
- Pruebas
- Interfaz de usuario web avanzada
- Edición rápida
- Xformers
- Img2Img
- en pintura
- Extras
- Redes de control
- Hacer cosas nuevas (WIP)
- Fusión de puntos de control
- Entrenamiento de LoRA
- Entrenando nuevos modelos
- Configuración de Google Colab (WIP)
- A mitad del viaje
- Parámetros de MJ
- Indicaciones avanzadas de MJ
- DreamStudio (WIP)
- Horda estable (WIP)
- Cabina de sueños (WIP)
- Difusión de vídeo (WIP)
Conceptos básicos de la interfaz de usuario web
Es algo desalentador entrar en esto... pero 4channers ha hecho un buen trabajo haciéndolo accesible. A continuación se detallan los pasos que tomé, en los términos más simples. Su intención es hacer que la WebUI de Stable Diffusion (creada con Gradio) se ejecute localmente para que pueda comenzar a solicitar y crear imágenes.
Configurar el uso de GPU local
Configuraremos Google Colab Pro más tarde, para que podamos ejecutar SD en cualquier dispositivo donde queramos; pero para comenzar, configuremos la WebUI en una PC. Necesita 16 GB de RAM, una GPU con 2 GB de VRAM, Windows 7+ y más de 20 GB de espacio en disco.
- Finalice la guía de configuración inicial
- Seguí esto hasta el paso 7, después del cual pasa al tema hentai.
- El paso 3 tarda entre 15 y 45 minutos con una velocidad promedio de Internet, ya que los modelos tienen más de 5 GB cada uno
- El paso 7 puede tardar más de media hora y puede parecer "atascado" en la CLI
- En el paso 3 descargué SD1.5, no las versiones 2.x, ya que la 1.5 produce resultados mucho mejores.
- CivitAI dispone de todos los modelos SD; Es como HuggingFace pero específicamente para SD.
- Verifique que la WebUI funcione
- Copie la URL que genera la CLI una vez hecho, por ejemplo,
127.0.0.1:7860 ( NO use Ctrl + C porque este comando puede cerrar la CLI) - Pega en el navegador y listo; prueba un mensaje y estarás listo para las carreras
- Las imágenes se guardarán automáticamente cuando se generen en
stable-diffusion-webuioutputstxt2img-images<date>
- Recuerde, para actualizar, simplemente abra una CLI en la carpeta stable-diffusion-webui e ingrese el comando
git pull
Configuración de Linux
Ignora esto por completo si tienes Windows. También logré ejecutarlo en Linux, aunque es un poco más complicado. Comencé siguiendo esta guía, pero está bastante mal escrita, por lo que a continuación se detallan los pasos que seguí para ejecutarla en Linux. Estaba usando Linux Mint 20, que es una distribución de Ubuntu 20.
- Comience clonando el repositorio webui:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - Obtenga un modelo SD (por ejemplo, SD 1.5, como en la sección anterior)
- Coloque el archivo ckpt del modelo en
stable-diffusion-webui/models/Stable-diffusion - Descarga Python (si aún no lo tienes):
sudo apt install python3 python3-pip python3-virtualenv wget git - Y la WebUI es muy particular, por lo que necesitamos instalar Conda, un administrador de entorno virtual, para trabajar dentro de:
wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
- Ahora crea el entorno:
conda create --name sdwebui python=3.10.6 - Activar el entorno:
conda activate sdwebui - Navegue a su carpeta WebUI y escriba
./webui.sh - Debería ejecutarse por un momento hasta que aparezca un error sobre no poder acceder a CUDA/tu GPU... esto está bien, porque es nuestro siguiente paso.
- Comience limpiando los controladores de Nvidia existentes:
sudo apt update
sudo apt purge *nvidia*
- Ahora, siguiendo algunos fragmentos de esta guía, descubra qué GPU tiene su máquina Linux (la forma más fácil de hacerlo es abrir la aplicación Driver Manager y su GPU aparecerá en la lista; pero hay una docena de formas, solo busque en Google)
- Vaya a esta página y haga clic en "Última rama de funciones nuevas" en Linux x86_64 (para mí, era 530.xx.xx)
- Haga clic en la pestaña "Productos compatibles" y Ctrl + F para encontrar su GPU; si aparece en la lista, continúe; de lo contrario, retroceda e intente con la "Última versión de la rama de producción"; anote el número, por ejemplo, 530
- En una terminal, escriba:
sudo add-apt-repository ppa:graphics-drivers/ppa - Actualizar con
sudo apt-get update - Inicie la aplicación Driver Manager y debería ver una lista de ellos; NO seleccione el recomendado (por ejemplo, nvidia-driver-530-open), seleccione exactamente el anterior (por ejemplo, nvidia-driver-530) y aplique cambios; O instálelo en la terminal con
sudo apt-get install nvidia-driver-530 - EN ESTE PUNTO, debería aparecer una ventana emergente a través de su CLI sobre Arranque seguro, solicitándole una contraseña de 8 dígitos: configúrela y escríbala
- Reinicie su PC y antes de cifrar/iniciar sesión de usuario, debería ver una pantalla similar a BIOS (estoy escribiendo esto desde la memoria) con una opción para ingresar una clave MOK; haga clic en él e ingrese su contraseña, luego envíela y arranque; algo de información aquí
- Inicie sesión como normalmente y escriba el comando
nvidia-smi ; si tiene éxito, debería imprimir una tabla; De lo contrario, dirá algo como "No se pudo conectar a la GPU; asegúrese de que esté instalado el controlador más actualizado". - Ahora, para instalar CUDA (el último comando aquí debería imprimir información sobre su nueva instalación de CUDA); de esta guía:
sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
- Ahora regresa y sigue los pasos 7-9; Si recibe este "ERROR: No se puede activar Python Venv, abortando...", vaya al siguiente paso (de lo contrario, estará listo y copiará la dirección IP de la CLI como de costumbre y podrá comenzar a jugar con SD)
- Este problema de Github tiene alguna solución para este problema de venv... para mí, lo que funcionó fue ejecutar
python3 -c 'import venv'
python3 -m venv venv/
Y luego vamos a la carpeta /stable-diffusion-webui y ejecutamos:
rm -rf venv/
python3 -m venv venv/
Después de eso, funcionó para mí.
Profundizando
- Lea sobre técnicas de estímulo, porque hay muchas cosas que saber (por ejemplo, estímulo positivo versus estímulo negativo, pasos de muestreo, método de muestreo, etc.)
- Guía del libro de instrucciones de OpenArt
- Guía definitiva de indicaciones SD
- Una guía sucinta
- Consejos de indicaciones de 4chan (NSFW)
- Colección de indicaciones e imágenes.
- Guía paso a paso de indicaciones para chicas anime
- Lea sobre el conocimiento de SD en general:
- Publicación seminal de difusión estable
- CompVis / Stability AI Github (hogar de los modelos SD originales)
- Compendio de difusión estable (buen recurso externo)
- Centro de enlaces de difusión estable (increíble recurso de 4chan)
- Mina de oro de difusión estable
- Mina de oro SD simplificada
- Aleatorio/Varios. Enlaces SD
- Preguntas frecuentes (NSFW)
- Otras preguntas frecuentes
- Únase a la discordia de difusión estable
- Manténgase al día con las novedades de Difusión Estable
- ¿Sabía que a partir de marzo de 2023, estará disponible un modelo de difusión de texto a vídeo con 1,700 millones de parámetros?
- Juega con la WebUI, juega con diferentes modelos, configuraciones, etc.
Incitación
El orden de las palabras en una indicación tiene un efecto: las palabras anteriores tienen prioridad. La estructura general de un buen mensaje, desde aquí:
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
Y otra buena guía dice que el mensaje debe seguir esta estructura:
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
Un artículo fundamental sobre modelos txt2img de ingeniería rápida, aquí. El recurso definitivo sobre las indicaciones para LLM, aquí.
Independientemente de lo que solicite, intente seguir algún tipo de estructura para que su proceso sea replicable. A continuación se muestran los elementos de sintaxis de aviso necesarios:
- () = modificador x1.05
- [] = modificador /1,05
- (palabra: 1.05) == (palabra)
- (palabra:1.1025) == ((palabra))
- (palabra:.952) == [palabra]
- (palabra:.907) == [[palabra]]
- La palabra clave AND le permite generar dos mensajes separados a la vez para fusionarlos; bueno para que las cosas no se rompan en el espacio latente
- Por ejemplo,
1girl standing on grass in front of castle AND castle in background
Modelo novedoso de IA
El modelo predeterminado es bastante claro pero, como suele ser el caso en la historia, el sexo impulsa la mayoría de las cosas. NovelAI (NAI) era un servicio de generación de contenido SD centrado en anime y se filtró su modelo principal. La mayoría de las imágenes generadas en SD de hombres y mujeres de anime que ves (NSFW o no) provienen de este modelo filtrado.
En cualquier caso, es realmente bueno para generar personas y la mayoría de los modelos o LoRA con los que jugarás fusionando son compatibles porque están entrenados en imágenes de anime. Además, los humanos presentan un caso de uso inicial realmente bueno para ajustar exactamente qué LoRA desea utilizar con fines profesionales. Estarás solucionando muchos problemas y la mayoría de las guías que existen son para imágenes de mujeres. Más adelante entraremos en los codificadores automáticos variables (VAE), que aportan verdadero realismo al modelo.
- Siga la guía Speedrun de NovelAI
- Necesitará descargar en Torrent el modelo filtrado o encontrarlo en otro lugar.
- Una vez que coloque los archivos en la carpeta de WebUI,
stable-diffusion-webuimodelsStable-diffusion , y seleccione el modelo allí, deberá esperar unos minutos mientras la CLI carga los pesos de VAE.- Si tiene problemas aquí, copie el archivo config.yaml de la carpeta donde estaba el modelo y siga el mismo esquema de nombres (como en esta guía).
- Esto es importante... Recrea la imagen de Asuka exactamente, consultando la guía de solución de problemas si no coincide.
- Encuentra nuevos modelos SD y LoRA
- CivitAI
- abrazando cara
- Modelos ODS
- Carga madre del modelo SDG (NSFW)
- Carga madre SDG LoRA (NSFW)
- Muchos modelos populares (también la guía de indicaciones anterior) (NSFW)
lora
La adaptación de bajo rango (LoRA) permite realizar ajustes para un modelo determinado. Más información sobre LoRA aquí. En la WebUI, puede agregar LoRA a un modelo como si fuera la guinda de un pastel. Entrenar nuevos LoRA también es bastante fácil. Existen otros medios "ancestrales" de ajuste fino (por ejemplo, inversión textual e hiperredes), pero los LoRA son lo último en tecnología.
- Tanque ZTZ99A - tanque militar LoRA (un tanque específico)
- Aviones de combate - avión de combate LoRA
- epi_noiseoffset: LoRA que resalta las imágenes y aumenta el contraste
Usaré el tanque LoRA a lo largo de la guía. Tenga en cuenta que este no es un LoRA muy bueno, ya que está diseñado para imágenes de estilo anime, pero está bien para jugar.
- Siga esta guía rápida para instalar la extensión
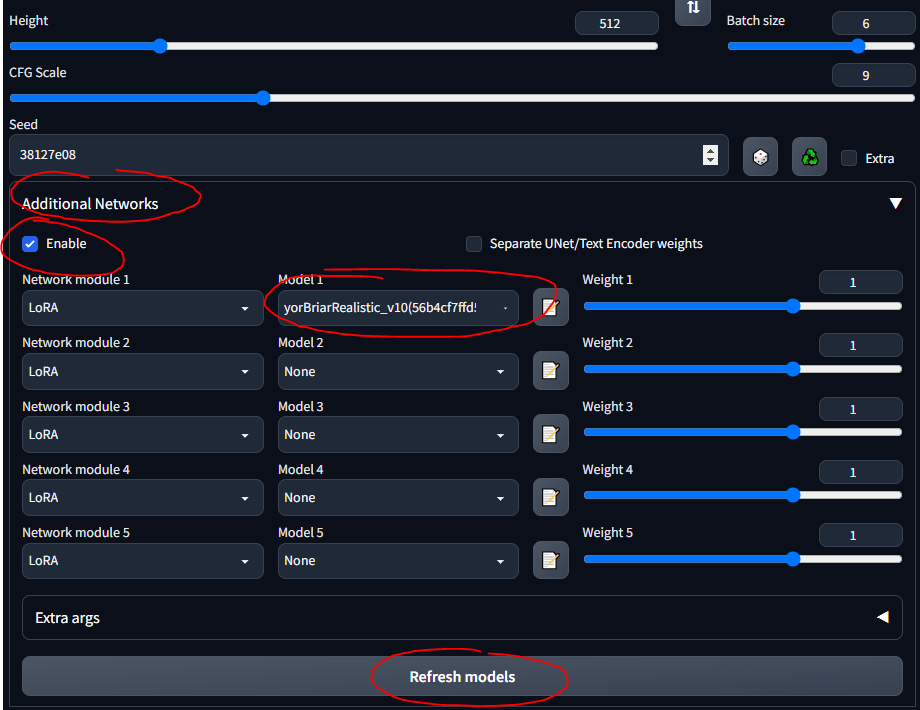
- Ahora debería ver una sección "Redes adicionales" en la interfaz de usuario
- Coloque sus LoRA en
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora - Selecciona y listo
- ASEGÚRESE DE MARCAR 'HABILITAR'
- Sólo debes saber que cualquier LoRA que descargues probablemente tenga información que describa cómo usarlo... como "usa la palabra clave tanque" o algo así; asegúrese de leer su descripción desde donde lo descargue (por ejemplo, CivitAI)
Jugando con modelos
Basándonos en la sección anterior... diferentes modelos tienen diferentes datos de entrenamiento y palabras clave de entrenamiento... por lo que usar etiquetas booru en algunos modelos no funciona muy bien. A continuación se muestran algunos de los modelos con los que jugué y las "instrucciones" para ellos.
SDG Model Motherload, utilizado para obtener la mayoría de los modelos, solo estoy resumiendo las instrucciones aquí para una referencia rápida; La mayoría de los modelos son para porno literal, me centré en los realistas. Siga los enlaces para ver ejemplos de indicaciones, imágenes y notas detalladas sobre el uso de cada uno de ellos.
- Modelo SD predeterminado (1.5, desde el paso de configuración; puedes jugar con las versiones 2.x de SD pero, para ser sincero, apestan)
- Modelo NovelAI (de la primera guía)
- Anything v3 - modelo de anime de propósito general
- Dreamshaper: realismo, multiusos
- Deliberado: realismo, fantasía, pinturas, paisajes.
- Sueño interminable: realismo, fantasía, bueno para las personas y los animales.
- Utiliza el sistema de etiquetas booru
- Epic Diffusion: ultrarrealismo, destinado a reemplazar la SD original
- AbyssOrangeMix (AOM): anime, realismo, artístico, pinturas, extremadamente común y bueno para probar.
- Kotosmix: propósito general, realismo, anime, paisajes, personas, se recomienda el sampler DPM++ 2M Karras
CivitAI se utilizó para conseguir todos los demás. Debe crear una cuenta , de lo contrario no podrá ver material NSFW, incluidas armas y equipo militar. En CivitAI, algunos modelos (puntos de control) incluyen VAE; Si dice esto, descárgalo también y colócalo junto al modelo.
- ChilloutMix: ultrarrealismo, retratos, uno de los más populares
- Protogen x3.4 - ultrarrealismo
- Utilice palabras desencadenantes: estilo modelshoot, estilo analógico, estilo mdjrny-v4, nousr robot
- Dreamlike Photoreal 2.0: ultrarrealismo
- Utilice una palabra desencadenante: fotorrealista
- Kit de herramientas de SPYBG para artistas digitales: realismo, arte conceptual
- Utilice palabras desencadenantes: tk-char, tk-env
VAEs
Los codificadores automáticos variables hacen que las imágenes se vean mejor, más nítidas y menos apagadas. Algunos también arreglan manos y rostros. Pero es sobre todo una cuestión de saturación y sombreado. Explicado aquí y aquí (NSFW). El NovelAI / Anything VAE se utiliza comúnmente. Es básicamente un complemento para tu modelo, como un LoRA.
Encuentre VAE en la lista de VAE:
- NAI / Cualquier cosa - para modelos de anime
- Viene con el modelo NAI por defecto cuando lo colocas en la carpeta de modelos.
- SD 1.5 - para modelos realistas
- Descargar un VAE
- Siga esta sección rápida de la guía para configurar VAE en WebUI
- Asegúrate de ponerlos en
stable-diffusion-webuimodelsVAE
- Experimente creando imágenes con y sin su VAE para ver las diferencias.
Ponlo todo junto
Aquí hay algunas notas generales y cosas útiles que aprendí a lo largo del camino y que no necesariamente se ajustan al flujo cronológico de esta guía.
El proceso general de DS
Una buena forma de aprender es buscar imágenes interesantes en CivitAI, AIbooru u otros sitios SD (4chan, Reddit, etc.), abrir lo que quiera y copiar los parámetros de generación en la WebUI. Divulgación completa: recrear una imagen exactamente no siempre es posible, como se describe aquí. Pero generalmente puedes acercarte bastante. Para jugar realmente, baje el CFG para que el modelo pueda volverse más creativo. Pruebe lotes y aléjese de la computadora para regresar a los lotes y elegir.
El proceso general para un flujo de trabajo WebUI es:
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
- txt2img - solicitar y obtener imágenes
- img2img: edita imágenes y genera otras similares
- inpainting: edita partes de imágenes (lo discutiremos más adelante)
- extra: ediciones de imágenes finales (lo discutiremos más adelante)
Mensajes de guardado
A veces desea volver a las indicaciones sin pegar imágenes o escribirlas desde cero. Puede guardar indicaciones para reutilizarlas en la WebUI.
- Escribe un mensaje positivo y/o negativo.
- Debajo del botón Generar, haga clic en el botón de la derecha para guardar su "estilo"
- Introduzca un nombre y guarde
- Selecciónelo en cualquier momento haciendo clic en el menú desplegable Estilos
Configuración de txt2img
Esta sección es más o menos un resumen de la información de esta guía.
- Más pasos de muestreo generalmente significan más precisión (a excepción de los muestreadores "a", como Euler a, que cambian de vez en cuando)
- Juega con esto de forma intermitente; En general, cuando está activado, realmente hace que las caras se vean bien.
- Resoluciones más altas. la solución es buena para imágenes superiores a 512x512; útil si hay más de una persona en una imagen
- CFG es mejor en valores medios-bajos, como 5-10
Regenerar una imagen generada previamente
Para trabajar a partir de una imagen generada en SD que ya existe; tal vez alguien te lo envió o quieres recrear uno que hiciste:
- En la WebUI, vaya a la pestaña Información PNG
- Arrastra y suelta la imagen que te interesa en la interfaz de usuario.
- Se guardan en
stable-diffusion-webuioutputstxt2img-images<date>
- Vea los parámetros utilizados a la derecha.
- Funciona porque los PNG pueden almacenar metadatos
- Puedes enviarlo directamente a la página txt2img con el botón correspondiente.
- Es posible que deba verificar de un lado a otro para asegurarse de que el modelo, VAE y otros parámetros se completen automáticamente correctamente
Tenga en cuenta que algunos sitios eliminan metadatos PNG cuando se cargan imágenes (por ejemplo, 4chan), así que busque URL de las imágenes completas o utilice sitios que conserven metadatos SD, como CivitAI o AIbooru.
Solución de errores
Recibí algunos errores de vez en cuando. Principalmente errores de falta de memoria (VRAM) que se solucionaron reduciendo los valores de algunos parámetros. A veces el Restaurador se enfrenta y Contrata. arreglar la configuración puede causar esto. En el archivo stable-diffusion-webuiwebui-user.bat , en la línea set COMMANDLINE_ARGS= , puedes poner algunas banderas que corrigen errores comunes.
- Un error de NaN, algo así como "un VAE produjo algo de NaN", agregue el parámetro
--disable-nan-check - Si alguna vez obtienes imágenes en negro, agrega
--no-half - Si sigue quedándose sin VRAM, agregue
--medvram o para computadoras tipo papa, --lowvram - Restauración facial: corrección de Codeformer aquí (si se rompe, intente restablecer su Internet primero)
- La carga lenta del modelo (al cambiar a uno nuevo) probablemente se deba a que los archivos .safetensors se cargan lentamente si las cosas no están configuradas correctamente. Este hilo lo discute.
Un problema realmente común surge de tener una versión incorrecta de Python o de Torch. Recibirá errores como "no se puede instalar Torch" o "Torch no puede encontrar la GPU". La solución más sencilla es:
- Desinstale cualquier versión de Python que haya actualizado, porque SD WebUI espera 3.10.6 (he usado 3.11.5 e ignoré el error de inicio, pero 3.10.6 parece funcionar mejor) (también puede usar un administrador de versiones si estás lo suficientemente avanzado)
- Instale Python 3.10.6, asegurándose de agregarlo a su RUTA (tanto su carpeta
Python como las carpetas Python/Scripts ) - Elimine la carpeta
venv en su carpeta stable-diffusion-webui - Ejecute
stable-diffusion-webuiwebui-user.bat y deje que reconstruya el venv correctamente - Disfrutar
Todos los argumentos de la línea de comando se pueden encontrar aquí.
Ponerse cómodo
Algunas extensiones pueden mejorar el uso de WebUI. Obtenga el enlace de Github, vaya a la pestaña Extensiones, instale desde la URL; Opcionalmente, en la pestaña Extensiones, haga clic en Disponible, luego Cargar desde y podrá buscar extensiones localmente, esto refleja la wiki de extensiones de Github.
- Tag Completer: recomienda y completa automáticamente etiquetas booru a medida que escribes
- Estado de la interfaz de usuario web de difusión estable: conserva el estado de la interfaz de usuario incluso después de reiniciar
- Pruebe mi mensaje: una secuencia de comandos que puede ejecutar para eliminar palabras individuales de su mensaje y ver cómo afecta la generación de imágenes.
- Modelo-Palabra clave: autocompleta palabras clave asociadas con algunos modelos y LoRA, bastante bien mantenido y actualizado a partir de abril de 2023.
- NSFW Checker: oscurece las imágenes NSFW; Útil si trabajas en una oficina, ya que muchos buenos modelos permiten contenido NSFW y es posible que no quieras verlo en el trabajo.
- TENGA EN CUENTA: esta extensión puede estropear la pintura o incluso la generación al oscurecer las imágenes NSFW (no temporalmente, literalmente genera una imagen negra), así que asegúrese de desactivarla según sea necesario.
- Aviso de Gelbooru: extrae etiquetas y crea un aviso automático a partir de cualquier imagen de Gelbooru usando su hash.
- booru2prompt: similar a Gelbooru Prompt pero con un poco más de funcionalidad
- Solicitudes dinámicas: un lenguaje de plantilla para la generación de solicitudes que le permite ejecutar solicitudes aleatorias o combinatorias para generar varias imágenes (utiliza comodines)
- Se describe un poco más aquí.
- Kit de herramientas de modelos: extensión popular que le ayuda a gestionar, editar y crear modelos.
- Model Converter: útil para convertir modelos, cambiar precisiones, etc., cuando estás entrenando el tuyo propio.
Pruebas
Ahora que tienes algunos modelos, LoRA e indicaciones... ¿cómo puedes probar para ver qué funciona mejor? Debajo del panel Redes adicionales, se encuentra el menú desplegable Script. Aquí, haga clic en Gráfico X/Y/Z. En el tipo X, seleccione Nombre del punto de control; en los valores X, haga clic en el botón a la derecha para pegar todos sus modelos. En el tipo Y, pruebe con la escala VAE, o quizás semilla, o CFG. Cualquiera que sea el atributo que elija, pegue (o ingrese) los valores que desea graficar. Por ejemplo, si tiene 5 modelos y 5 VAE, creará una cuadrícula de 25 imágenes y comparará el rendimiento de cada modelo con cada VAE. Esto es muy versátil y puede ayudarte a decidir qué usar. Sólo tenga en cuenta que si sus ejes X o Y son modelos de VAE, tiene que cargar el modelo o los pesos de VAE para cada combinación, por lo que puede llevar un tiempo.
Puede encontrar un recurso realmente bueno sobre comparaciones de SD aquí (NSFW). Hay muchos enlaces para seguir. Puede comenzar a comprender cómo los distintos modelos, VAE, LoRA, valores de parámetros, etc., afectan la generación de imágenes.
Adopté un mensaje de prueba desde aquí y usé el tanque LoRA para hacer esta cuadrícula X/Y. Puede ver cómo funcionan los distintos modelos y samplers entre sí. A partir de esta prueba podemos evaluar que:
- Los modelos ChilloutMix, Deliberate, Dreamlike Photoreal y Epic Diffusion parecen producir las imágenes de tanques más "realistas".
- En pruebas independientes posteriores, se descubrió que Protogen X34 Photorealism y SpyBGs Toolkit también eran bastante buenos con los tanques.
- Los samplers más prometedores aquí parecen ser DPM++ SDE o cualquiera de los samplers de Karras.

Los parámetros exactos utilizados (sin incluir el modelo o el muestreador) para cada una de estas imágenes de tanques se detallan a continuación (nuevamente, tomados de aquí):
- Aviso positivo: tanque, bf2042, mejor calidad, obra maestra, resolución ultra alta (fotorrealista: 1.4), aspecto detallado, iluminación cinematográfica, fotografía cinematográfica muy detallada, colorida y moderna, un grupo de soldados en el campo de batalla, explosiones en el campo de batalla por todas partes, aviones de combate y helicópteros volando en el cielo, dos tanques en tierra, en una zona desértica, edificios en llamas y un vehículo blindado militar abandonado al fondo
- Mensaje negativo: desnudo, (peor calidad:2), (baja calidad:2), (calidad normal:2), baja resolución, mala anatomía, malas manos, calidad normal, ((monocromo)), ((escala de grises)), colapsado sombra de ojos, múltiples golpes en los ojos, cabello rosado, agujeros en los senos, ng_deepnegative_v1_75t, nsfw, pezones, dedos adicionales, ((brazos adicionales)), (piernas adicionales), manos mutadas, (fusionadas dedos), (demasiados dedos), (cuello largo: 1,3)
- Pasos: 22
- Escala CFG: 7,5
- Semilla: 1656460887
- Tamaño: 480x480
- Saltar clip: 2
- AddNet habilitado: Verdadero, Módulo AddNet 1: LoRA, Modelo AddNet 1: ztz99ATank_ztz99ATank(82a1a1085b2b), Peso AddNet A 1: 1, Peso AddNet B 1: 1
Interfaz de usuario web avanzada
En esta sección se encuentran las cosas más avanzadas que puede hacer una vez que se familiarice con el uso de modelos, LoRA, VAE, indicaciones, parámetros, secuencias de comandos y extensiones en la pestaña txt2image de la WebUI.
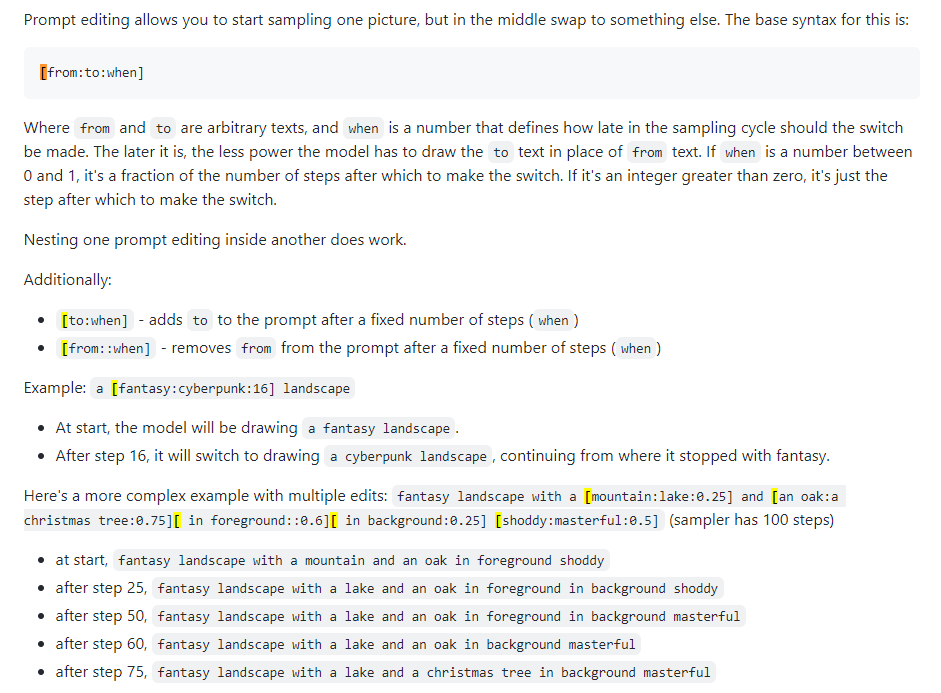
Edición rápida
También conocido como mezcla rápida. La edición de mensajes le permite hacer que el modelo cambie su mensaje en pasos específicos. La siguiente imagen fue tomada de una publicación de 4chan y describe la técnica. Por ejemplo, como se indica en esta guía, se puede utilizar la edición rápida para fusionar caras.
Xformers
Xformers o capas de atención cruzada. Una forma de acelerar la generación de imágenes (medida en segundos/iteración, o s/it) en las GPU de Nvidia reduce el uso de VRAM pero provoca no determinismo. Considere esto solo si tiene una GPU potente; De manera realista, necesitas un Quadro.
img2img
No se usa mucho exactamente, es una pestaña algo confusa. Se puede utilizar para generar imágenes a partir de bocetos, como en Huggingface Image to Image SD Playground. Esta pestaña tiene una subpestaña, inpainting, que es el tema de la siguiente sección y una capacidad muy importante de la WebUI. Si bien puedes usar esta sección para generar imágenes alteradas a partir de una que ya hayas creado (salida a stable-diffusion-webuioutputsimg2img-images ), la funcionalidad es irregular para mí... parece usar una cantidad increíble de memoria y Apenas puedo hacerlo funcionar. Vaya a la siguiente sección a continuación.
en pintura
Aquí es donde reside el poder del creador de contenido o de alguien interesado en la perturbación de imágenes. La salida está en stable-diffusion-webuioutputsimg2img-images .
- Guía para pintar y pintar
- 4chan en pintura (NSFW)
- Guía definitiva de pintura.
- Tome una imagen que le guste pero que no sea perfecta, algo está mal; es necesario modificarlo
- O genere uno y haga clic en Enviar a inpaint (todas las configuraciones se completarán automáticamente)
- Ahora estás en la subpestaña img2img -> inpaint
- Dibuja (con el mouse) en la imagen el punto exacto que deseas cambiar
- Establezca el modo de máscara en "enmascarado en pintura", el contenido enmascarado en "original" y el área en pintura en "solo enmascarado"
- En el área de mensajes de arriba, escriba el nuevo mensaje para modificar ese punto de la imagen; haz un mensaje negativo si quieres
- Genere una imagen (idealmente, haga un lote de 4 aproximadamente)
- Cualquiera que prefiera, haga clic en Enviar a inpaint e itere hasta que tenga una imagen terminada.
pintar
Outpainting es un proceso semántico bastante complejo. Outpainting te permite tomar una imagen y expandirla tantas veces como quieras, esencialmente haciendo crecer sus bordes. El proceso se describe aquí. Expande la imagen solo 64 píxeles a la vez. Hay dos herramientas de interfaz de usuario para esto (que pude encontrar):
- Alpha Canvas (integrado en WebUI como extensión/script)
- Hua (aplicación web para pintar y pintar)
Extras
Esta pestaña WebUI es específicamente para ampliación. Si obtiene una imagen que realmente le gusta, puede mejorarla aquí al final de su flujo de trabajo. Las imágenes mejoradas se almacenan en stable-diffusion-webuioutputsextras-images . Algunos de los problemas de memoria asociados con el escalado con escaladores más potentes durante la generación en la pestaña txt2img (por ejemplo, los 4x+) no ocurren aquí porque no estás generando nuevas imágenes, solo estás escalando imágenes estáticas.
Redes de control
La mejor manera de entender lo que hace ControlNet es como decir "pintar con esteroides". Le das una imagen de entrada (generada en SD o no) y puede modificar todo. También son posibles con ControlNets las poses. Puede dar una pose de referencia para una persona y generar las imágenes correspondientes según su mensaje típico. Un buen comienzo para comprender ControlNets está aquí.
- Instale la extensión ControlNet, sd-webui-controlnet en WebUI
- Asegúrese de recargar la interfaz de usuario haciendo clic en el botón Recargar interfaz de usuario en la pestaña de configuración
- Verifique que el botón ControlNet esté ahora en la pestaña txt2img (e img2img), debajo de Redes adicionales (donde coloca sus LoRA)
- Activar múltiples modelos ControlNet: Configuración -> ControlNet -> Control deslizante Mutli ControlNet -> 2+
- Vuelva a cargar la interfaz de usuario y en el área ControlNet debería ver varias pestañas de modelo.
- Puede combinar ControlNets (por ejemplo, Canny y OpenPose) como si utilizara múltiples LoRA.
- Obtenga un modelo ControlNet
- Los modelos Canny son modelos de detección de bordes; Las imágenes se convierten en imágenes de bordes en blanco y negro, donde los bordes le dicen a SD, aproximadamente, cómo se verá su imagen.
- Los modelos OpenPose toman una imagen de una persona y la convierten en un modelo de pose para usar en imágenes posteriores.
- Hay muchos otros modelos que también se pueden investigar allí.
- Tomemos los modelos Canny y OpenPose.
- Ponlos en
stable-diffusion-webuiextensionssd-webui-controlnetmodels - Obtenga cualquier imagen de su interés o genere una nueva; Aquí usaré esta imagen de tanque que generé anteriormente.

- Configuraciones en txt2img: método de muestreo "DDIM", pasos de muestreo 20, ancho/alto igual que la imagen seleccionada
- Configuraciones en la pestaña ControlNet: marque Habilitar, Preprocesador "Canny", Modelo "control_canny-fp16", ancho/alto del lienzo igual que la imagen seleccionada (todas las demás configuraciones son predeterminadas)
- Modifique sus indicaciones y haga clic en generar; Intenté convertir la imagen de mi tanque a una en Marte.

- El mensaje positivo fue: una escena en Marte, espacio exterior, espacio, universo, ((fondo del espacio galaxia)), estrellas, base lunar, futurista, fondo negro, fondo oscuro, estrellas en el cielo, (noche) arena roja, ((estrellas en el fondo)), tanque, bf2042, mejor calidad, obra maestra, resolución ultra alta, (fotorrealista: 1.4), piel detallada, iluminación cinematográfica, fotografía cinematográfica muy detallada, colorida y moderna, un grupo de soldados en el campo de batalla, explosión en el campo de batalla por todas partes, chorro cazas y helicópteros volando en el cielo, dos tanques en tierra, en una zona desértica, edificios en llamas y un vehículo blindado militar abandonado en el fondo, árbol, bosque, cielo
- Ve a tomar una imagen con personas y podrás hacer tanto el modelo Canny en Control Model - 0 como el modelo OpenPose en Control Model - 1 para divertirte realmente con él.
- De nuevo, mira este vídeo para profundizar realmente en Canny y OpenPose.
Hacer cosas nuevas
Todo esto está muy bien, pero a veces se necesitan mejores modelos o LoRA para casos de uso profesional. Debido a que la mayor parte del contenido de SD está literalmente destinado a generar mujeres o pornografía, es posible que sea necesario capacitar modelos específicos y LoRA.
- Explore todos los temas de interés aquí
- Entrenamiento de LoRA
- tren LoRA
- Guía de entrenamiento de Lazy LoRA
- Una buena guía de formación de LoRA de CivitAI
- Otra guía de formación de LoRA
- Más información general sobre LoRA
- Fusionando modelos
- Modelos de mezcla
Entrenando nuevos modelos
Consulte la sección sobre DreamBooth.
Fusión de puntos de control
HACER
La pestaña de fusión de puntos de control en la WebUI le permite combinar dos modelos, como mezclar dos salsas en una olla, donde el resultado es una nueva salsa que es una combinación de ambas.
Entrenamiento de LoRA
HACER
Entrenar un LoRA no es necesariamente difícil, es sólo cuestión de recopilar suficientes datos.
Configuración de Google Colab
Este es un paso importante si tiene que trabajar lejos de su equipo. Google Colab Pro cuesta 10 dólares al mes y te brinda 89 GB de RAM y acceso a buenas GPU, por lo que técnicamente puedes ejecutar indicaciones desde tu teléfono y hacer que funcionen para ti en un servidor en Tombuctú. Si no te importa un poco de coste extra, Google Colab Pro+ cuesta 50 dólares al mes y es incluso mejor.
- Vaya a este SD Colab prediseñado
- Puedes clonarlo en tu GDrive o simplemente usarlo tal como está para que siempre esté actualizado desde Github.
- Ejecute los primeros 4 bloques de código (tarda un poco)
- Omitir el bloque de código ControlNet
- Ejecute 'Iniciar difusión estable' (tarda un poco)
- Pon nombre de usuario/contraseña si quieres (probablemente sea una buena idea ya que Gradio es público)
- Haga clic en el enlace de Gradio ('ejecutándose en una URL pública')
- Utilice la WebUI como de costumbre
- Envíe el enlace a su teléfono y podrá generar imágenes sobre la marcha
- Para agregar nuevos modelos y LoRA, debe tener nuevas carpetas en su Google Drive:
gdrive/MyDrive/sd/stable-diffusion-webui , y desde esta carpeta base puede usar la misma estructura de carpetas que ha estado haciendo en el local. interfaz de usuario web- Realice la instalación de la extensión LoRA como antes y la estructura de carpetas se completará automáticamente como en el escritorio.
- Ahora, cada vez que quieras usarlo, solo tienes que ejecutar el bloque de código 'Iniciar difusión estable' (ninguna de las otras cosas), obtener un enlace de gradio y listo.
Google Colab siempre es gratuito y puedes usarlo para siempre, pero puede resultar un poco lento. Actualizar a Colab Pro por $10 al mes te brinda más potencia. Pero Colab Pro+ por $50 al mes es donde realmente está la diversión. Pro+ te permite ejecutar tu código durante 24 horas incluso después de cerrar la pestaña.
TODO Recibo un error extraño que interrumpe mi suscripción Pro cuando configuro mi tiempo de ejecución -> configuración del cuaderno de tipo runetime en clase GPU Premium y RAM alta. Es porque xFormers no fue creado con soporte CUDA. Esto podría resolverse usando TPU en su lugar o desactivando xFormers, pero no tengo paciencia para ello en este momento. Pruebe los problemas de Colab.
A mitad del viaje
MJ es realmente bueno para los artistas. No es EN ABSOLUTO tan extensible o potente como SD en la WebUI (NSFW es imposible), pero puedes generar algunas cosas bastante impresionantes. Puedes usarlo gratis en MJ Discord (regístrate en su sitio) para recibir algunas indicaciones o pagar $8 al mes por el plan básico, después de lo cual podrás usarlo en tu propio servidor privado. Todos los comandos de Discord se pueden encontrar aquí y aquí. La estructura del mensaje para MJ es:
/imagine <optional image prompt> <prompt> --parameters
Parámetros de MJ
Estos son para MJ V4, prácticamente los mismos para MJ 5. Todos los modelos se describen aquí.
- --ar 1.2-2.1: relación de aspecto, el valor predeterminado es 1:1
- --caos 0-100: variación en, el valor predeterminado es 0
- --sin plantas: elimina las plantas
- --q 0.0-2.0: tiempo de calidad de renderizado, el valor predeterminado es 1
- --semilla: la semilla
- --stop 10-100: detiene el trabajo a medio camino para generar una imagen más borrosa
- --estilo 4a/4b/4c: estilo de MJ 4'
- --stylize 0-1000: cuán fuerte es la estética de MJ, el valor predeterminado es 100
- --uplight: utiliza un escalador "ligero", la imagen es menos detallada
- --upbeta: utiliza un escalador beta, más cercano a la imagen original
- --upanime: escalador de imágenes de anime
- --niji: modelo alternativo para imágenes de anime
- --hd: utiliza un modelo anterior que produce imágenes más grandes, bueno para resúmenes y paisajes
- --prueba: utilice el modelo de prueba especial MJ
- -portp: use el modelo de prueba especializado en fotografía MJ
- -Wile: solo para MJ 5, genera una imagen repetida
- Verificador de imágenes tilables
- --V 1/2/3/4/5: ¿Qué versión MJ usar (5 es mejor)
MJ avanzado indicadores
- Puede inyectar una imagen (o imágenes) al comienzo de un aviso para influir en su estilo y colores. Vea este documento. Cargue una imagen en su servidor de discordia y haga clic con el botón derecho para obtener el enlace.
- La remezcla le permite hacer variaciones de una imagen, cambiar modelos, sujetos o medio. Vea este documento.
- Las indicaciones múltiples permiten que MJ considere dos o más conceptos separados individualmente. Versiones MJ 1-4 y Niji solamente. Por ejemplo, "hot dog" hará imágenes de la comida, "Hot :: Dog" hará imágenes de un canino cálido. También puede agregar pesas a las indicaciones; Por ejemplo, "Hot :: 2 Dog" hará imágenes de perros en llamas. MJ 1/2/3 acepta pesos enteros, MJ 4 puede aceptar decimales. Vea este documento.
- Mezclar le permite subir 2-5 imágenes para fusionarlas en una nueva imagen. El comando /mezcla se describe aquí.
Dreamstudio
HACER
DreamStudio (no Dreambooth) es la plataforma insignia de la compañía Stability AI. Su sitio es una plataforma, Dreambooth Studio, del que puede generar imágenes. Se descansa entre MidJourney y WebUI en términos de funcionalidad abierta. Dreambooth Studio parece estar construido sobre la plataforma Invoke.ai, que puede instalar y ejecutar localmente como WebUI.
Horda estable
HACER
La Horda estable es un esfuerzo comunitario para hacer que todos sean una difusión estable para todos. Esencialmente funciona como Torrenting o Bitcoin hashing, donde todos contribuyen con parte de su poder de GPU para generar contenido SD. Se puede acceder a la aplicación Horde aquí.
Dreambooth
HACER
Dreambooth (no DreamStudio) fue la implementación de Google de una técnica de ajuste fino del modelo de difusión estable. En resumen: puede usarlo para entrenar modelos con sus propias imágenes. Puede usarlo directamente desde aquí o aquí. Es más complejo que solo descargar modelos y hacer clic en WebUI, ya que está trabajando para entrenar y serializar un nuevo modelo. Algunos videos resumen cómo hacerlo:
- Dreambooth Tutorial fácil
- Entrenamiento de 10 minutos de DreamBooth
- Webui Dreambooth Extension
Y algunas buenas guías:
- Reddit Advanced Dreambooth consejo
- Simple Dreambooth
- Dreambooth Dump (mucha información, desplazarse por los enlaces)
Un Google Colab para Dreambooth:
- Thelastben Dreambooth Training Colab (el mismo autor que el SD Colab descrito en la configuración de Google Colab)
También hay un entrenador modelo llamado Everydream. Aquí se puede encontrar una comparación completa entre Dreambooth y Everydream aquí.
Difusión de video
HACER
Es posible que a partir de marzo de 2023 utilice una difusión estable para generar videos. Actualmente (abril de 2023), la funcionalidad es bastante simplista, ya que los videos se generan a partir de imágenes similares, marco, dando a los videos una especie de aspecto "Flipbook". Hay dos extensiones principales para la webui que puede usar:
- Animador - Más fácil
- Deforum - Más funcionalidad
Depósito de chatarra
Cosas de las que no sé mucho pero necesito investigar
Hay un proceso que puede seguir para obtener buenos resultados una y otra vez ... esto se refinará con el tiempo.
- HACER
- Highres Fix, aquí
- escalado, pero aquí sobre todo
¿Integración de chatgpt?
pintar
Dall-E 2
deforum https://deforum.github.io/


