Q Bench
1.0.0
¿Cómo se desempeñan los LLM multimodales en visión por computadora de bajo nivel?
Haoning Wu 1 * , Zicheng Zhang 2 * , Erli Zhang 1 * , Chaofeng Chen 1 , Liang Liao 1 ,
Annan Wang 1 , Chunyi Li 2 , Wenxiu Sun 3 , Qiong Yan 3 , Guangtao Zhai 2 , Weisi Lin 1 #
1 Universidad Tecnológica de Nanyang, 2 Universidad Jiaotong de Shanghai, 3 Sensetime Research
* Igual contribución. # Autor correspondiente.
Foco ICLR2024
Papel | Página del proyecto | GitHub | Datos (LLVisionQA) | Datos (LLDescribe) |质衡 (Q-Bench chino)


El Q-Bench propuesto incluye tres ámbitos para la visión de bajo nivel: percepción (A1), descripción (A2) y evaluación (A3).
Para percepción (A1)/descripción (A2), recopilamos dos conjuntos de datos de referencia LLVisionQA/LLDescribe.
Estamos abiertos a una evaluación basada en presentaciones para las dos tareas. Los detalles para la presentación son los siguientes.
Para la evaluación (A3), como utilizamos conjuntos de datos públicos , proporcionamos un código de evaluación abstracto para MLLM arbitrarios para que cualquiera pueda probarlo.
datasets Para Q-Bench-A1 (con preguntas de opción múltiple), las hemos convertido en conjuntos de datos en formato HF que se pueden descargar y usar automáticamente con la API datasets . Consulte las siguientes instrucciones:
conjuntos de datos de instalación de pip
desde conjuntos de datos import load_datasetds = load_dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id': 0,### 'imagen': <PIL .JpegImagePlugin.JpegImageFile modo de imagen=Tamaño RGB=4160x3120>,### 'pregunta': '¿Cómo es la iluminación de esto? ¿edificio?',### 'opción0': 'Alto',### 'opción1': 'Bajo',### 'opción2': 'Medio',### 'opción3': 'N/A', ### 'tipo_pregunta': 2,### 'preocupación_pregunta': 3,### 'elección_correcta': 'B'} desde conjuntos de datos import load_datasetds = load_dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id': 0,### 'image1': <PIL .Image.Image modo de imagen=Tamaño RGB=4032x3024>,### 'image2': <PIL.JpegImagePlugin.JpegImageFile imagen mode=RGB size=864x1152>,### 'pregunta': 'En comparación con la primera imagen, ¿cómo es la claridad de la segunda imagen?',### 'opción0': 'Más borrosa',### 'opción1 ': 'Más claro',### 'opción2': 'Más o menos lo mismo',### 'opción3': 'N/A',### 'tipo_pregunta': 2,### 'pregunta_preocupación': 0,### 'elección_correcta': 'B'}[2024/8/8] ¡TPAMI acaba de aceptar la parte de la tarea de comparación de visión de bajo nivel de Q-bench+ (también conocida como Q-Bench2)! Ven y prueba tu MLLM con Q-bench+_Dataset.
[2024/8/1] Q-Bench se lanza en VLMEvalKit, venga y pruebe su LMM con un comando como `python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose'.
[2024/6/17] Q-Bench , Q-Bench2 (Q-bench+) y A-Bench ahora se han unido a lmms-eval, ¡lo que facilita la prueba de LMM!
[3/6/2024] El repositorio de Github para A-Bench está en línea. ¿Quiere saber si su LMM es un maestro en la evaluación de imágenes generadas por IA? ¡¡Ven y prueba en A-Bench !!
[3/1] Estamos lanzando Co-instruct , Hacia una comparación abierta de calidad visual aquí. Pronto habrá más detalles.
[27/2] Nuestro trabajo Q-Insturct ha sido aceptado por CVPR 2024, ¡intente conocer los detalles sobre cómo instruir a los MLLM en visión de bajo nivel!
[23/2] ¡La parte de la tarea de comparación de visión de bajo nivel de Q-bench+ ahora está lanzada en Q-bench+ (Conjunto de datos)!
[2/10] Estamos lanzando el Q-bench+ extendido, que desafía a los MLLM con imágenes individuales y pares de imágenes en visión de bajo nivel. ¡La tabla de clasificación está en el sitio, consulte la capacidad de visión de bajo nivel de sus MLLM favoritos! Más detalles próximamente.
[1/16] Nuestro trabajo "Q-Bench: Un punto de referencia para modelos de cimentación de uso general en visión de bajo nivel" es aceptado por ICLR2024 como presentación destacada .

Probamos en tres modelos API de código cercano, GPT-4V-Turbo ( gpt-4-vision-preview , reemplazando los resultados de la versión anterior GPT-4V que ya no está disponible), Gemini Pro ( gemini-pro-vision ) y Qwen -VL-Plus ( qwen-vl-plus ). Ligeramente mejorado en comparación con la versión anterior, GPT-4V sigue siendo el mejor entre todos los MLLM y tiene un rendimiento casi humano de nivel junior. Le siguen Gemini Pro y Qwen-VL-Plus, aún mejores que los mejores MLLM de código abierto (0,65 en general).
Actualización el [18/7/2024]. Nos complace lanzar el nuevo rendimiento SOTA de BlueImage-GPT (fuente cercana).
Percepción, A1-Single
| Nombre del participante | sí o no | qué | cómo | distorsión | otros | distorsión en contexto | otros en contexto | en general |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0.7574 | 0,7325 | 0.5733 | 0.6488 | 0.7324 | 0.6867 | 0.7056 | 0.6893 |
BlueImage-GPT ( from VIVO nuevo campeón de VIVO) | 0.8467 | 0.8351 | 0.7469 | 0.7819 | 0.8594 | 0.7995 | 0.8240 | 0.8107 |
Gemini-Pro ( gemini-pro-vision ) | 0.7221 | 0.7300 | 0.6645 | 0.6530 | 0.7291 | 0.7082 | 0.7665 | 0.7058 |
GPT-4V-Turbo ( gpt-4-vision-preview ) | 0.7722 | 0.7839 | 0.6645 | 0.7101 | 0.7107 | 0.7936 | 0.7891 | 0,7410 |
| GPT-4V ( versión antigua ) | 0.7792 | 0.7918 | 0.6268 | 0.7058 | 0.7303 | 0.7466 | 0.7795 | 0.7336 |
| humano-1-junior | 0.8248 | 0.7939 | 0.6029 | 0.7562 | 0.7208 | 0.7637 | 0.7300 | 0,7431 |
| humano-2-mayor | 0.8431 | 0.8894 | 0.7202 | 0.7965 | 0.7947 | 0.8390 | 0.8707 | 0.8174 |
Percepción, par A1
| Nombre del participante | sí o no | qué | cómo | distorsión | otros | comparar | articulación | en general |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0.6685 | 0.5579 | 0.5991 | 0.6246 | 0.5877 | 0.6217 | 0.5920 | 0.6148 |
Qwen-VL-Max ( qwen-vl-max ) | 0.6765 | 0.6756 | 0.6535 | 0.6909 | 0.6118 | 0.6865 | 0.6129 | 0.6699 |
BlueImage-GPT ( from VIVO nuevo campeón de VIVO) | 0.8843 | 0.8033 | 0.7958 | 0.8464 | 0.8062 | 0.8462 | 0.7955 | 0.8348 |
Gemini-Pro ( gemini-pro-vision ) | 0.6578 | 0.5661 | 0.5674 | 0.6042 | 0.6055 | 0.6046 | 0.6044 | 0.6046 |
GPT-4V ( gpt-4-vision ) | 0.7975 | 0.6949 | 0.8442 | 0.7732 | 0.7993 | 0.8100 | 0.6800 | 0.7807 |
| Humano de nivel junior | 0.7811 | 0.7704 | 0.8233 | 0.7817 | 0.7722 | 0.8026 | 0.7639 | 0.8012 |
| Humano de nivel superior | 0.8300 | 0.8481 | 0.8985 | 0.8313 | 0.9078 | 0.8655 | 0.8225 | 0.8548 |
También hemos evaluado recientemente varios modelos nuevos de código abierto y pronto publicaremos sus resultados.
Ahora ofrecemos dos formas de descargar los conjuntos de datos (LLVisionQA y LLDescribe)
a través de GitHub Lanzamiento: consulte nuestro lanzamiento para obtener más detalles.
a través de Huggingface Datasets: consulte las notas de la versión de datos para descargar las imágenes.
Se recomienda encarecidamente convertir su modelo al formato Huggingface para probar estos datos sin problemas. Vea los scripts de ejemplo para IDEFICS-9B-Instruct de Huggingface como ejemplo y modifíquelos para que su modelo personalizado los pruebe en su modelo.
Envíe un correo electrónico [email protected] para enviar su resultado en formato json.
También puede enviarnos su modelo (podría ser Huggingface AutoModel o ModelScope AutoModel), junto con sus scripts de evaluación personalizados. Sus scripts personalizados se pueden modificar desde los scripts de plantilla que funcionan para LLaVA-v1.5 (para A1/A2) y aquí (para evaluación de la calidad de la imagen).
Envíe un correo electrónico [email protected] para enviar su modelo si se encuentra fuera de China continental. Envíe un correo electrónico [email protected] para enviar su modelo si se encuentra dentro de China continental.
A continuación se muestra una instantánea del conjunto de datos de referencia de LLVisionQA para la capacidad de percepción de bajo nivel de MLLM. Vea la clasificación aquí.
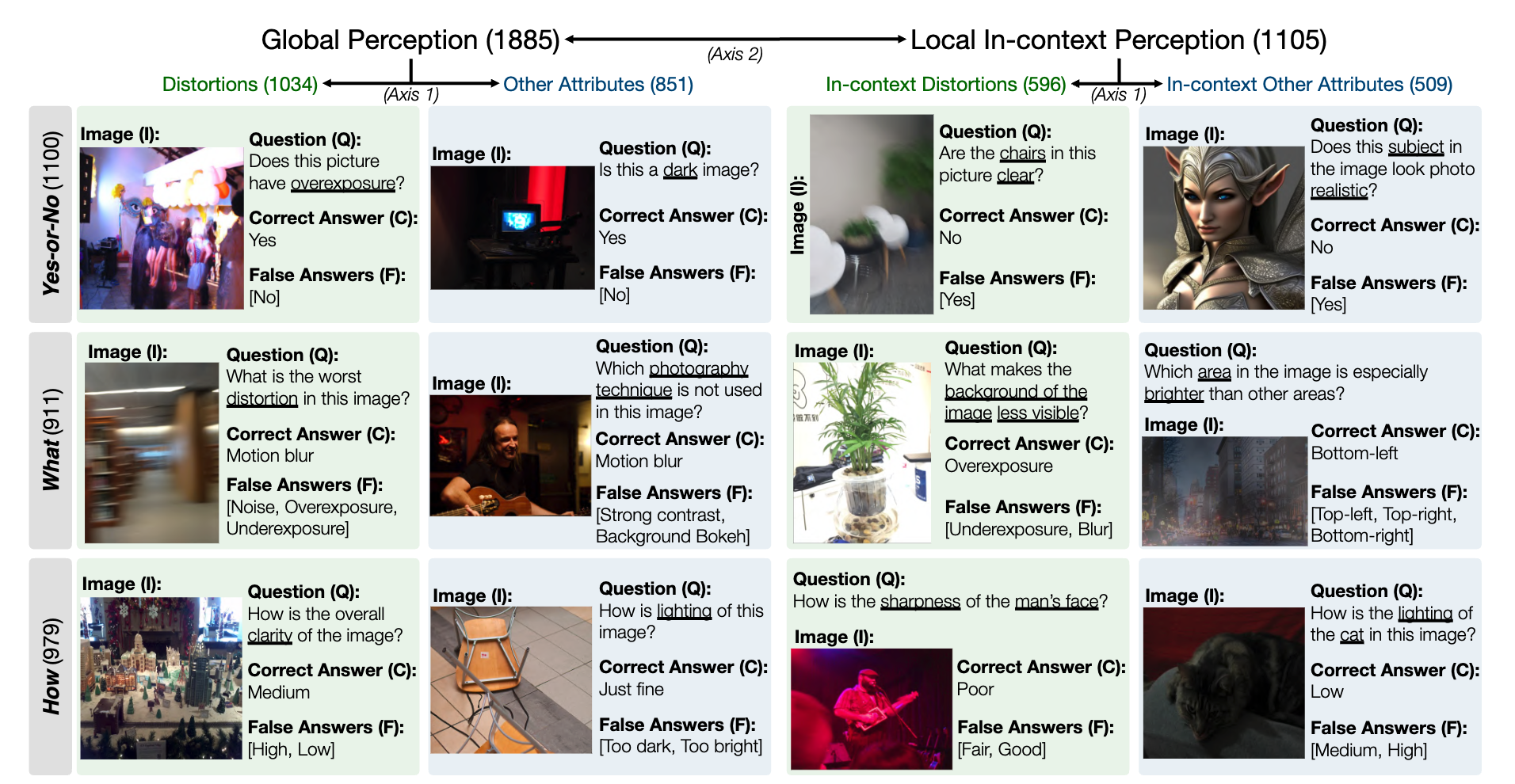
Medimos la precisión de las respuestas de los MLLM (proporcionados con la pregunta y todas las opciones) como métrica aquí.
A continuación se muestra una instantánea del conjunto de datos de referencia de LLDescribe para la capacidad de descripción de bajo nivel de MLLM. Vea la clasificación aquí.

Aquí medimos la integridad , precisión y relevancia de las descripciones de MLLM como métrica.
¡Una habilidad emocionante que los MLLM pueden predecir puntajes cuantitativos para IQA!
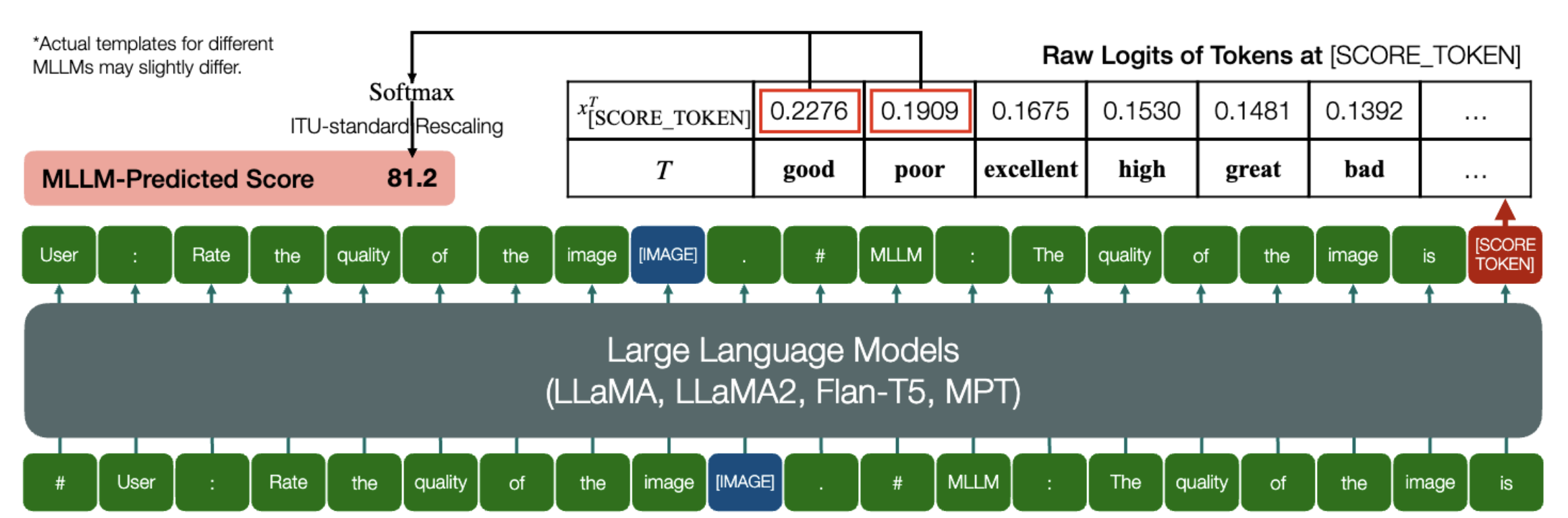
De manera similar a lo anterior, siempre que un modelo (basado en modelos de lenguaje causal) tenga los dos métodos siguientes: embed_image_and_text (para permitir entradas multimodales) y forward (para calcular logits), la Evaluación de la calidad de la imagen (IQA) con el modelo se puede lograr de la siguiente manera:
from PIL import Imagefrom my_mllm_model import Model, Tokenizer, embed_image_and_textmodel, tokenizer = Model(), Tokenizer()prompt = "##Usuario: Califica la calidad de la imagen.n"
"##Asistente: La calidad de la imagen es" ### Esta línea se puede modificar según el comportamiento predeterminado de MLLM.good_idx, pobre_idx = tokenizer(["bueno","pobre"]).tolist()image = Imagen. open("image_for_iqa.jpg")input_embeds = embed_image_and_text(imagen, mensaje)output_logits = model(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[good_idx, pobre_idx]] / 100).softmax(0)[0]*Tenga en cuenta que puede modificar la segunda línea según el formato predeterminado de su modelo, por ejemplo , para Shikra, "##Asistente: La calidad de la imagen es" se modifica como "##Asistente: La respuesta es". Está bien si su MLLM primero responde "¡Ok, me gustaría ayudar! La calidad de la imagen es", simplemente reemplace esto en la línea 2 del mensaje.
Además, proporcionamos una implementación completa de IDEFICS en IQA. Vea un ejemplo sobre cómo ejecutar IQA con este MLLM. Otros MLLM también se pueden modificar de la misma manera para usarlos en IQA.
Hemos preparado puntuaciones de opinión humana (MOS) en formato JSON para las siete bases de datos de IQA evaluadas en nuestro punto de referencia.
Consulte IQA_databases para obtener más detalles.
Movido a tablas de clasificación. Por favor haga clic para ver los detalles.
Comuníquese con cualquiera de los primeros autores de este artículo si tiene consultas.
Haoning Wu, [email protected] , @teowu
Zicheng Zhang, [email protected] , @zzc-1998
Erli Zhang, [email protected] , @ZhangErliCarl
Si encuentra interesante nuestro trabajo, no dude en citarlo:
@inproceedings{wu2024qbench,author = {Wu, Haoning y Zhang, Zicheng y Zhang, Erli y Chen, Chaofeng y Liao, Liang y Wang, Annan y Li, Chunyi y Sun, Wenxiu y Yan, Qiong y Zhai, Guangtao y Lin, Weisi},title = {Q-Bench: Un punto de referencia para modelos de cimentaciones de uso general en visión de bajo nivel},booktitle = {ICLR},año = {2024}} 

