LLM PuzzleTest
1.0.0
PuzzleVQA, nuestro nuevo conjunto de datos revela serios desafíos de los LLM multimodales para comprender patrones abstractos simples. Papel | Sitio web
¡Lanzamos AlgoPuzzleVQA, un conjunto de datos novedoso y desafiante para el razonamiento multimodal! Pronto lanzaremos más conjuntos de datos de rompecabezas multimodales. ¡Manténganse al tanto! Papel | Sitio web
Nos complace anunciar el lanzamiento de dos nuevos conjuntos de datos VQA centrados en acertijos:
El rendimiento de los MLLM en ambos conjuntos de datos es notablemente deficiente, lo que subraya la necesidad apremiante de mejoras sustanciales en sus capacidades de razonamiento multimodal.
Los grandes modelos multimodales amplían las impresionantes capacidades de los grandes modelos de lenguaje al integrar capacidades de comprensión multimodal. Sin embargo, no está claro cómo pueden emular la inteligencia general y la capacidad de razonamiento de los humanos. Como reconocer patrones y abstraer conceptos son clave para la inteligencia general, presentamos PuzzleVQA, una colección de rompecabezas basados en patrones abstractos. Con este conjunto de datos, evaluamos grandes modelos multimodales con patrones abstractos basados en conceptos fundamentales, incluidos colores, números, tamaños y formas. A través de nuestros experimentos con grandes modelos multimodales de última generación, descubrimos que no pueden generalizarse bien a patrones abstractos simples. En particular, ni siquiera GPT-4V puede resolver más de la mitad de los acertijos. Para diagnosticar los desafíos de razonamiento en grandes modelos multimodales, guiamos progresivamente los modelos con nuestras explicaciones de razonamiento de verdad fundamental para la percepción visual, el razonamiento inductivo y el razonamiento deductivo. Nuestro análisis sistemático encuentra que los principales obstáculos de GPT-4V son una percepción visual más débil y capacidades de razonamiento inductivo. A través de este trabajo, esperamos arrojar luz sobre las limitaciones de los grandes modelos multimodales y cómo pueden emular mejor los procesos cognitivos humanos en el futuro.
PuzzleVQA está disponible aquí y también en Huggingface.
La siguiente figura muestra una pregunta de ejemplo que involucra el concepto de color en PuzzleVQA y una respuesta incorrecta de GPT-4V. Generalmente se pueden observar tres etapas en el proceso de resolución: percepción visual (azul), razonamiento inductivo (verde) y razonamiento deductivo (rojo). En este caso, la percepción visual era incompleta, lo que provocó un error durante el razonamiento deductivo.

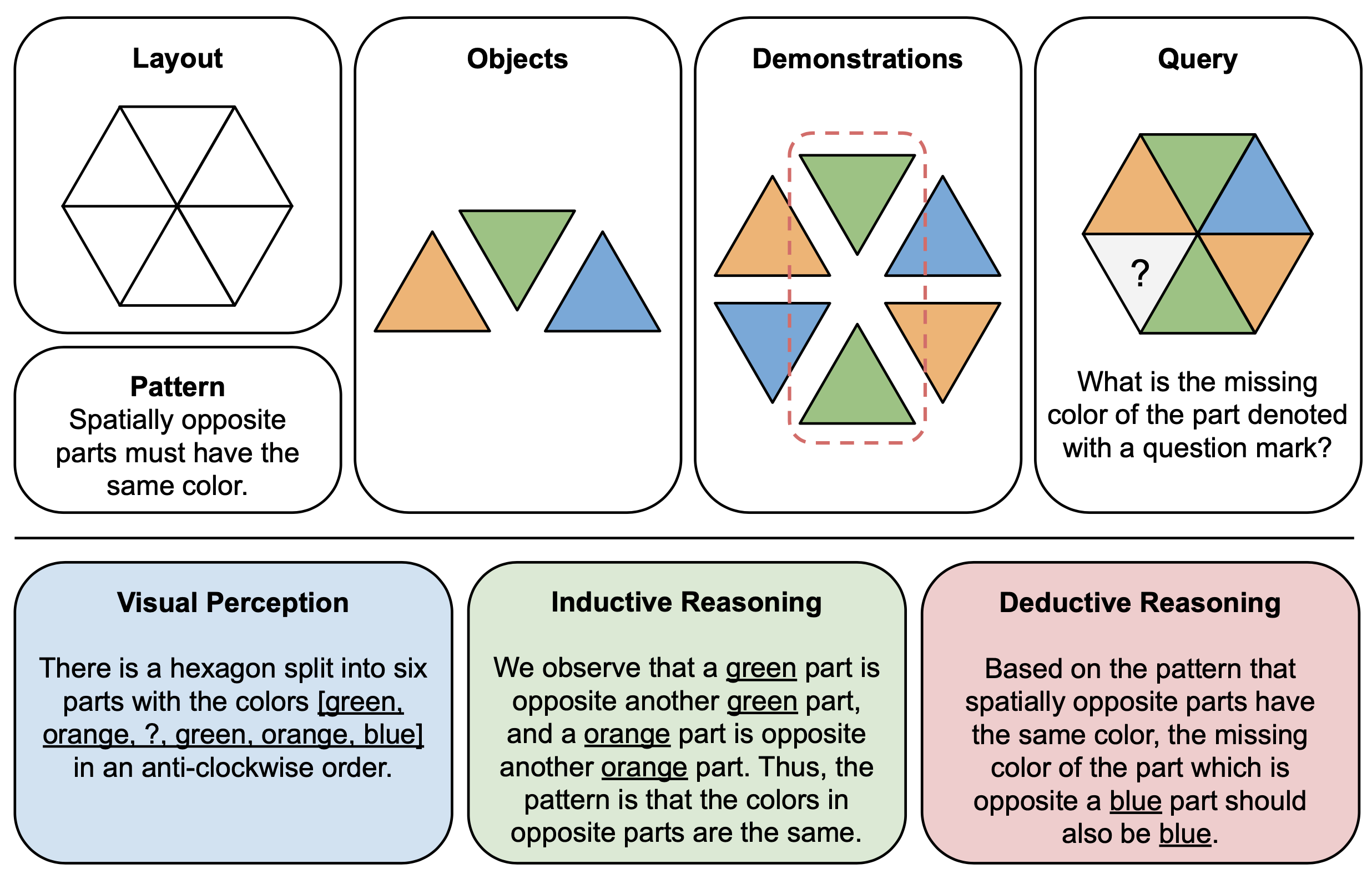
La siguiente figura muestra un ejemplo ilustrativo de componentes (arriba) y explicaciones de razonamiento (abajo) para acertijos abstractos en PuzzleVQA. Para construir cada instancia de rompecabezas, primero definimos el diseño y el patrón de una plantilla multimodal y completamos la plantilla con objetos adecuados que demuestren el patrón subyacente. Para lograr interpretabilidad, también construimos explicaciones de razonamiento de verdad fundamental para interpretar el rompecabezas y explicar las etapas generales de la solución.
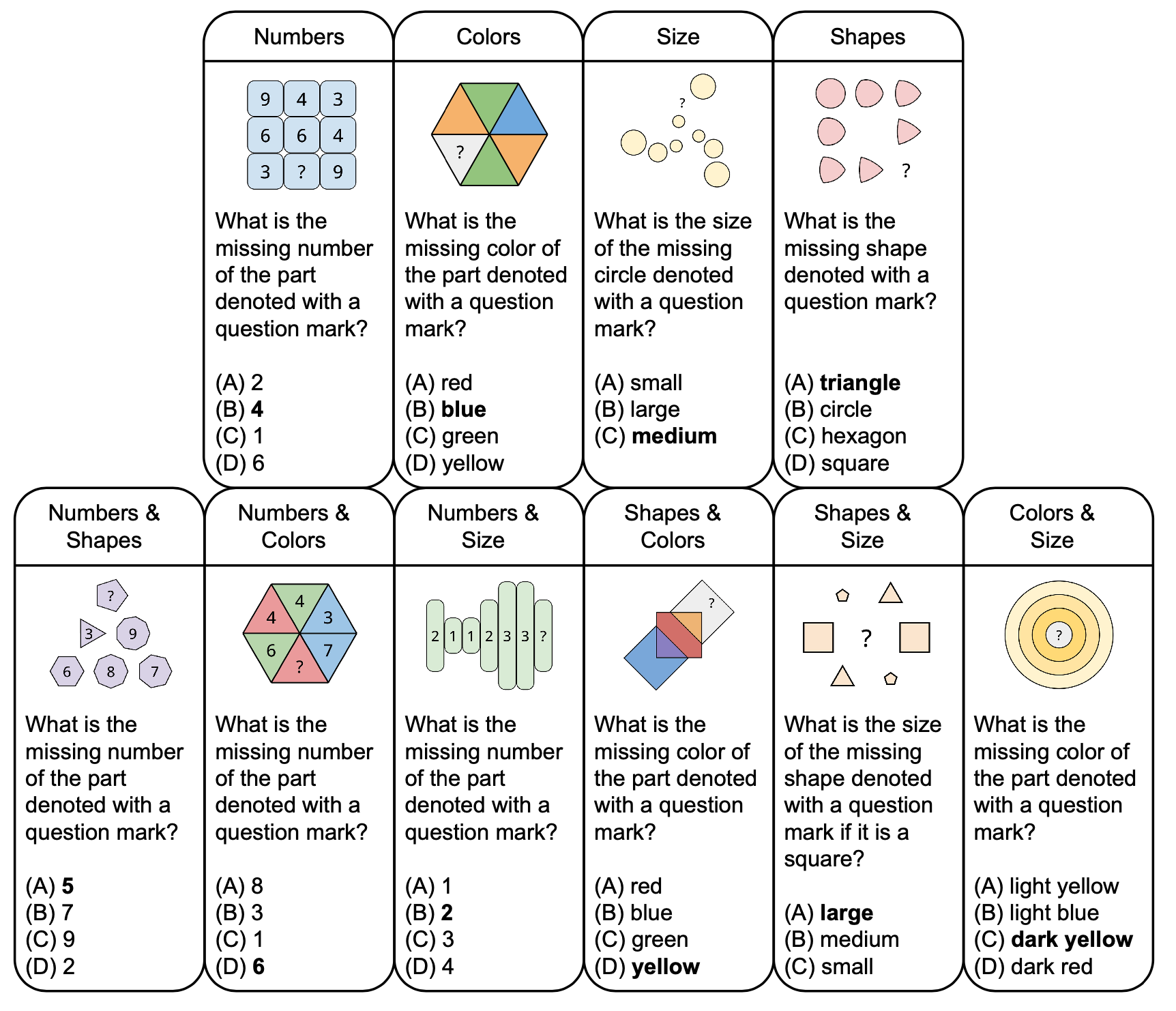
La siguiente figura muestra la taxonomía de rompecabezas abstractos en PuzzleVQA con preguntas de muestra, basadas en conceptos fundamentales como colores y tamaño. Para mejorar la diversidad, diseñamos rompecabezas de un solo concepto y de dos conceptos.
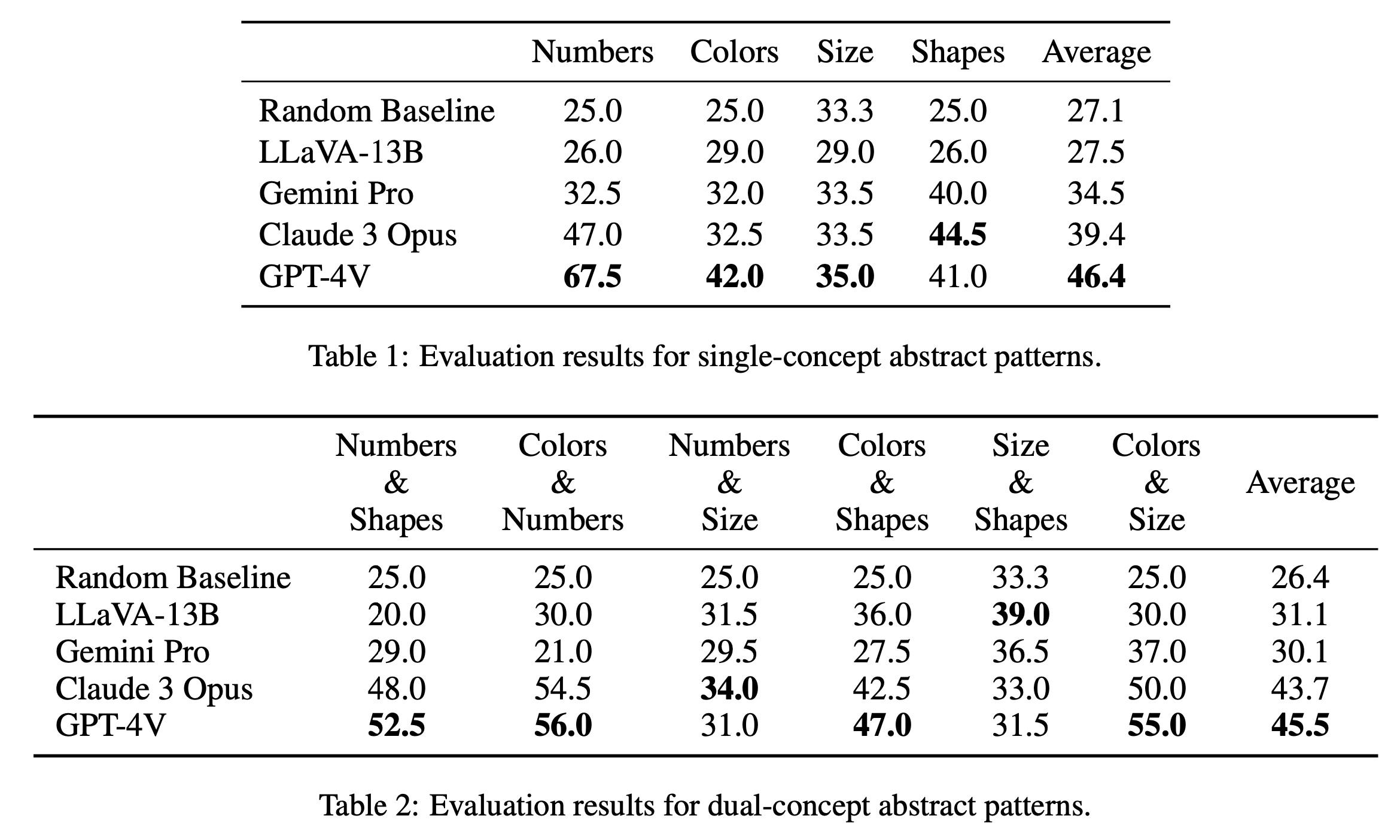
Presentamos los principales resultados de la evaluación de acertijos de concepto único y de concepto dual en la Tabla 1 y la Tabla 2, respectivamente. Los resultados de la evaluación para acertijos de un solo concepto, como se muestra en la Tabla 1, revelan diferencias notables en el rendimiento entre los modelos de código abierto y cerrado. GPT-4V se destaca con la puntuación promedio más alta de 46,4, lo que demuestra un razonamiento de patrones abstractos superior en acertijos de un solo concepto, como números, colores y tamaño. Destaca particularmente en la categoría "Números" con una puntuación de 67,5, superando con creces a otros modelos, lo que puede deberse a su ventaja en tareas de razonamiento matemático (Yang et al., 2023). Le sigue Claude 3 Opus con una media general de 39,4, mostrando su fortaleza en la categoría "Formas" con una puntuación máxima de 44,5. Los otros modelos, incluidos Gemini Pro y LLaVA-13B, van detrás con promedios de 34,5 y 27,5 respectivamente, con un rendimiento similar al de la línea de base aleatoria en varias categorías.
En la evaluación de acertijos de concepto dual, como se muestra en la Tabla 2, GPT-4V vuelve a destacar con la puntuación media más alta de 45,5. Obtuvo un desempeño particularmente bueno en categorías como "Colores y números" y "Colores y tamaños", con una puntuación de 56,0 y 55,0 respectivamente. Claude 3 Opus le sigue de cerca con una media de 43,7, mostrando un buen rendimiento en "Números y Tamaño" con la puntuación más alta de 34,0. Curiosamente, LLaVA-13B, a pesar de su promedio general más bajo de 31,1, obtiene la puntuación más alta en la categoría "Tamaño y formas" con 39,0. Gemini Pro, por otro lado, tiene un rendimiento más equilibrado en todas las categorías, pero con un promedio general ligeramente inferior de 30,1. En general, encontramos que los modelos funcionan de manera similar en promedio para patrones de concepto único y de concepto dual, lo que sugiere que son capaces de relacionar múltiples conceptos, como colores y números, entre sí.
@misc{chia2024puzzlevqa,
title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns},
author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria},
year={2024},
eprint={2403.13315},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Presentamos la novedosa tarea de resolución de acertijos multimodales, enmarcada en el contexto de la respuesta visual a preguntas. Presentamos un nuevo conjunto de datos, AlgoPuzzleVQA, diseñado para desafiar y evaluar las capacidades de los modelos de lenguaje multimodal para resolver acertijos algorítmicos que requieren comprensión visual, comprensión del lenguaje y razonamiento algorítmico complejo. Creamos los acertijos para abarcar una amplia gama de temas matemáticos y algorítmicos, como lógica booleana, combinatoria, teoría de grafos, optimización, búsqueda, etc., con el objetivo de evaluar la brecha entre la interpretación de datos visuales y las habilidades algorítmicas de resolución de problemas. El conjunto de datos se genera automáticamente a partir de código creado por humanos. Todos nuestros acertijos tienen soluciones exactas que se pueden encontrar a partir del algoritmo sin tediosos cálculos humanos. Garantiza que nuestro conjunto de datos pueda ampliarse arbitrariamente en términos de complejidad de razonamiento y tamaño del conjunto de datos. Nuestra investigación revela que los modelos de lenguaje grandes (LLM) como GPT4V y Gemini exhiben un rendimiento limitado en tareas de resolución de acertijos. Descubrimos que su desempeño es casi aleatorio en una configuración de preguntas y respuestas de opción múltiple para una cantidad significativa de acertijos. Los hallazgos enfatizan los desafíos de integrar conocimientos visuales, lingüísticos y algorítmicos para resolver problemas de razonamiento complejos.
PuzzleVQA está disponible aquí y también en Huggingface.
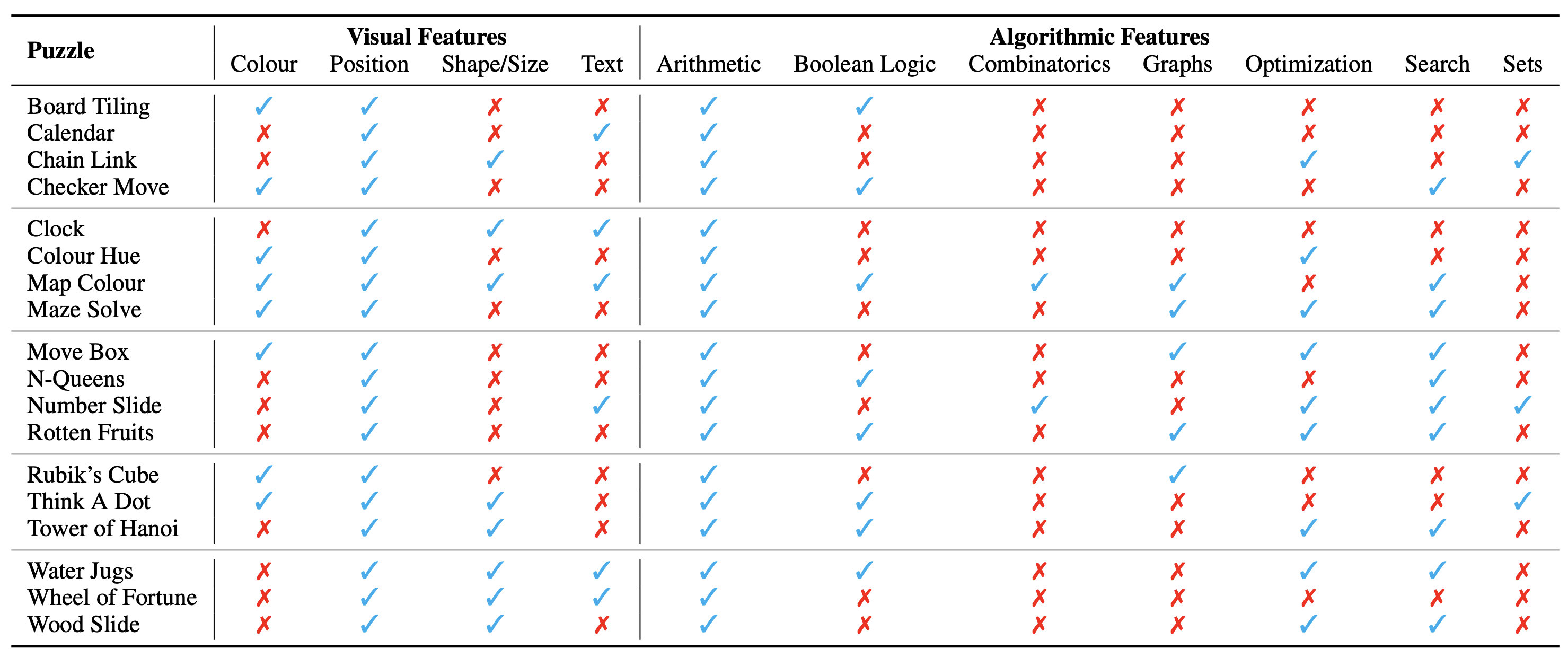
La configuración del rompecabezas/problema se muestra como una imagen, que constituye su contexto visual. Identificamos los siguientes aspectos fundamentales del contexto visual que influyen en la naturaleza de los rompecabezas:

También identificamos los conceptos algorítmicos necesarios para resolver los acertijos, es decir, para responder las preguntas de las instancias de los acertijos. Son los siguientes:

Las categorías algorítmicas no son mutuamente excluyentes, ya que necesitamos usar dos o más categorías para derivar la respuesta a la mayoría de los acertijos.
El conjunto de datos está disponible aquí en estos formatos. Creamos un total de 18 acertijos diferentes que abarcan diversos temas algorítmicos y matemáticos. Muchos de estos acertijos son populares en diversos entornos recreativos o académicos.
En total, tenemos 1800 instancias de 18 acertijos diferentes. Estas instancias son análogas a diferentes casos de prueba del rompecabezas, es decir, tienen diferentes combinaciones de entrada, estados inicial y objetivo, etc. Resolver de manera confiable todas las instancias requeriría encontrar el algoritmo exacto a usar y luego aplicarlo con precisión. Esto es similar a cómo verificamos la precisión de un programa de computadora cuyo objetivo es resolver una tarea particular a través de una amplia gama de casos de prueba.
Actualmente consideramos el conjunto de datos completo como un punto de referencia únicamente de evaluación . Los ejemplos detallados de todos los rompecabezas se muestran aquí.
Las instrucciones para generar el conjunto de datos se pueden encontrar aquí. El número de instancias y la dificultad de los rompecabezas se pueden escalar arbitrariamente a cualquier tamaño o nivel deseado.
La categorización ontológica de los acertijos es la siguiente:
La configuración experimental y los scripts se pueden encontrar en el directorio AlgoPuzzleVQA.
Considere citar el siguiente artículo si nuestro trabajo le resultó útil:
@article { ghosal2024algopuzzlevqa ,
title = { Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning } ,
author = { Ghosal, Deepanway and Han, Vernon Toh Yan and Chia, Yew Ken and and Poria, Soujanya } ,
journal = { arXiv preprint arXiv:2403.03864 } ,
year = { 2024 }
}

