lightllm
1.0.0
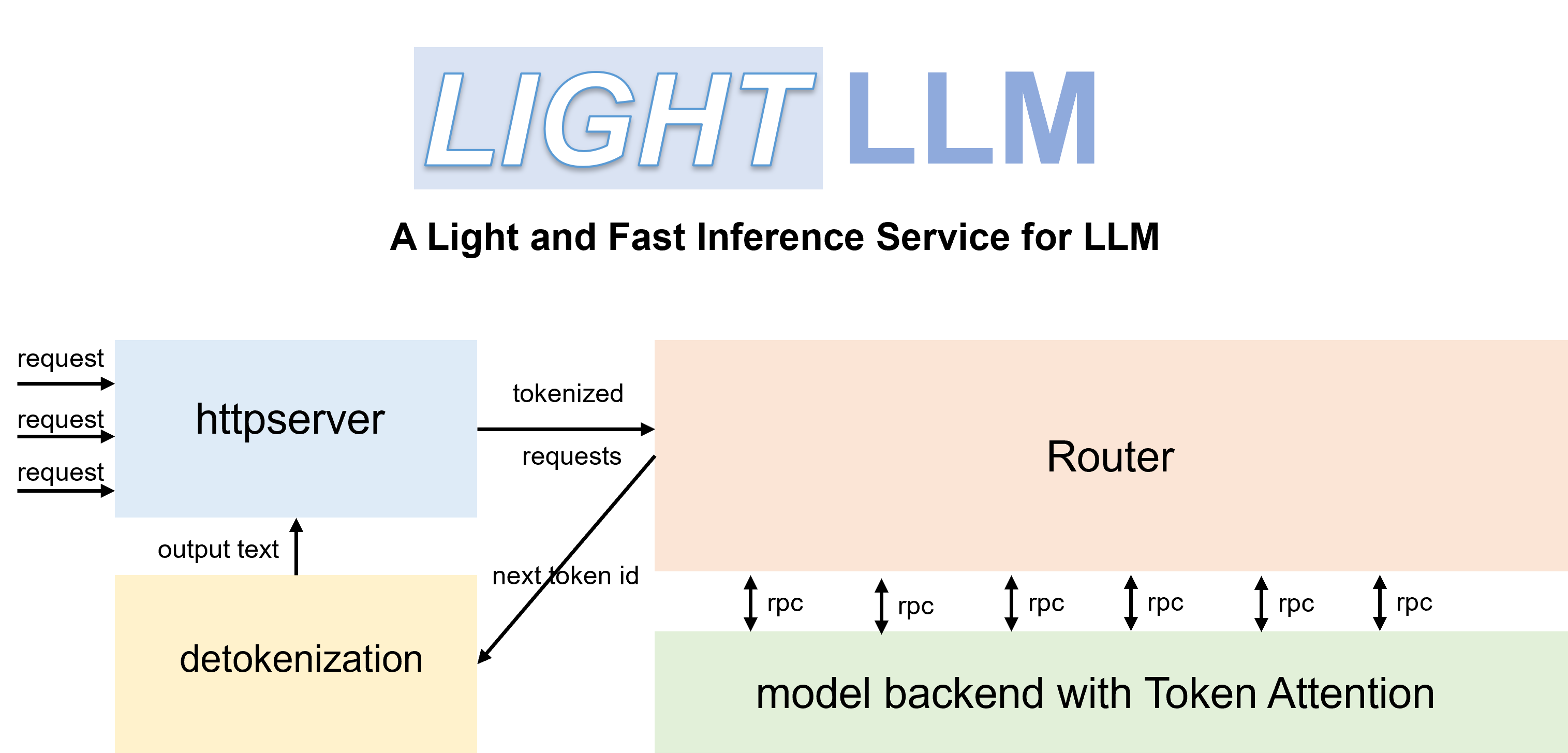
LightLLM es un marco de servicio e inferencia LLM (modelo de lenguaje grande) basado en Python, que destaca por su diseño liviano, fácil escalabilidad y rendimiento de alta velocidad. LightLLM aprovecha los puntos fuertes de numerosas implementaciones de código abierto reconocidas, incluidas, entre otras, FasterTransformer, TGI, vLLM y FlashAttention.
Documentos en inglés | 中文文档
Cuando inicia Qwen-7b, debe configurar el parámetro '--eos_id 151643 --trust_remote_code'.
ChatGLM2 necesita configurar el parámetro '--trust_remote_code'.
InternLM necesita configurar el parámetro '--trust_remote_code'.
InternVL-Chat(Phi3) necesita configurar el parámetro '--eos_id 32007 --trust_remote_code'.
InternVL-Chat(InternLM2) necesita configurar el parámetro '--eos_id 92542 --trust_remote_code'.
Qwen2-VL-7b necesita configurar el parámetro '--eos_id 151645 --trust_remote_code' y usar 'pip install git+https://github.com/huggingface/transformers' para actualizar a la última versión.
Stablelm necesita configurar el parámetro '--trust_remote_code'.
Phi-3 solo admite Mini y Small.
DeepSeek-V2-Lite y DeepSeek-V2 necesitan configurar el parámetro '--data_type bfloat16'
El código ha sido probado con Pytorch>=1.3, CUDA 11.8 y Python 3.9. Para instalar las dependencias necesarias, consulte el archivo de requisitos.txt proporcionado y siga las instrucciones que se indican a continuación.
# for cuda 11.8
pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu118
# this version nccl can support torch cuda graph
pip install nvidia-nccl-cu12==2.20.5Puede utilizar el contenedor oficial de Docker para ejecutar el modelo más fácilmente. Para hacer esto, siga estos pasos:
Extraiga el contenedor del Registro de contenedores de GitHub:
docker pull ghcr.io/modeltc/lightllm:mainEjecute el contenedor con soporte para GPU y mapeo de puertos:
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
ghcr.io/modeltc/lightllm:main /bin/bashAlternativamente, puedes construir el contenedor tú mismo:
docker build -t < image_name > .
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
< image_name > /bin/bashTambién puede utilizar un script auxiliar para iniciar tanto el contenedor como el servidor:
python tools/quick_launch_docker.py --help Nota: Si utiliza varias GPU, es posible que necesite aumentar el tamaño de la memoria compartida agregando --shm-size al comando docker run .
python setup.py installEl código se ha probado en una variedad de GPU, incluidas V100, A100, A800, 4090 y H800. Si está ejecutando el código en A100, A800, etc., le recomendamos usar triton==3.0.0.
pip install triton==3.0.0 --no-depsSi está ejecutando el código en H800 o V100, puede probar triton-nightly para obtener un mejor rendimiento.
pip install -U --index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/Triton-Nightly/pypi/simple/ triton-nightly --no-depsCon enrutadores eficientes y TokenAttention, LightLLM se puede implementar como un servicio y lograr un rendimiento de última generación.
Inicie el servidor:
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 120000 El parámetro max_total_token_num está influenciado por la memoria de GPU del entorno de implementación. También puede especificar --mem_faction para que se calcule automáticamente.
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--mem_faction 0.9Para iniciar una consulta en el shell:
curl http://127.0.0.1:8080/generate
-X POST
-d ' {"inputs":"What is AI?","parameters":{"max_new_tokens":17, "frequency_penalty":1}} '
-H ' Content-Type: application/json 'Para consultar desde Python:
import time
import requests
import json
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
data = {
'inputs' : 'What is AI?' ,
"parameters" : {
'do_sample' : False ,
'ignore_eos' : False ,
'max_new_tokens' : 1024 ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )python -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/Qwen-VL or /path/of/Qwen-VL-Chatpython -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/llava-v1.5-7b or /path/of/llava-v1.5-13b import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "<img></img>Generate the caption in English with grounding:" ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text ) import json
import requests
import base64
def run_once ( query , uris ):
images = []
for uri in uris :
if uri . startswith ( "http" ):
images . append ({ "type" : "url" , "data" : uri })
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images . append ({ 'type' : "base64" , "data" : b64 })
data = {
"inputs" : query ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" , " <|im_start|>" , " <|im_end|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
# url = "http://127.0.0.1:8080/generate_stream"
url = "http://127.0.0.1:8080/generate"
headers = { 'Content-Type' : 'application/json' }
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( " + result: ({})" . format ( response . json ()))
else :
print ( ' + error: {}, {}' . format ( response . status_code , response . text ))
"""
multi-img, multi-round:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<img></img>
<img></img>
上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|>
<|im_start|>assistant
根据提供的信息,两张图片分别是重庆和北京。<|im_end|>
<|im_start|>user
这两座城市分别在什么地方?<|im_end|>
<|im_start|>assistant
"""
run_once (
uris = [
"assets/mm_tutorial/Chongqing.jpeg" ,
"assets/mm_tutorial/Beijing.jpeg" ,
],
query = "<|im_start|>system n You are a helpful assistant.<|im_end|> n <|im_start|>user n <img></img> n <img></img> n上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|> n <|im_start|>assistant n根据提供的信息,两张图片分别是重庆和北京。<|im_end|> n <|im_start|>user n这两座城市分别在什么地方?<|im_end|> n <|im_start|>assistant n "
) import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: <image> n Please explain the picture. ASSISTANT:" ,
"parameters" : {
"max_new_tokens" : 200 ,
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )Parámetros de lanzamiento adicionales:
--enable_multimodal,--cache_capacity, mayor--cache_capacityrequiereshm-sizemayor
Soporte
--tp > 1, cuandotp > 1, el modelo visual se ejecuta en la gpu 0
La etiqueta de imagen especial para Qwen-VL es
<img></img>(<image>para Llava), la longitud dedata["multimodal_params"]["images"]debe ser la misma que el recuento de etiquetas, el número puede ser 0, 1, 2,...
Formato de imágenes de entrada: lista para dict como
{'type': 'url'/'base64', 'data': xxx}
Comparamos el rendimiento del servicio de LightLLM y vLLM==0.1.2 en LLaMA-7B usando un A800 con memoria GPU de 80G.
Para comenzar, prepare los datos de la siguiente manera:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.jsonInicie el servicio:
python -m lightllm.server.api_server --model_dir /path/llama-7b --tp 1 --max_total_token_num 121060 --tokenizer_mode autoEvaluación:
cd test
python benchmark_serving.py --tokenizer /path/llama-7b --dataset /path/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 2000 --request-rate 200Los resultados de la comparación de rendimiento se presentan a continuación:
| vllm | LuzLLM |
|---|---|
| Tiempo total: 361,79 s Rendimiento: 5,53 solicitudes/s | Tiempo total: 188,85 s Rendimiento: 10,59 solicitudes/s |
Para la depuración, ofrecemos scripts de prueba de rendimiento estáticos para varios modelos. Por ejemplo, puede evaluar el rendimiento de inferencia del modelo LLaMA mediante
cd test/model
python test_llama.pypip install protobuf==3.20.0 .error : PTX .version 7.4 does not support .target sm_89bash tools/resolve_ptx_version python -m lightllm.server.api_server ... Si tiene un proyecto que deba incorporarse, comuníquese por correo electrónico o cree una solicitud de extracción.
Una vez que haya instalado lightllm y lazyllm , podrá usar el siguiente código para crear su propio chatbot:
from lazyllm import TrainableModule , deploy , WebModule
# Model will be download automatically if you have an internet connection
m = TrainableModule ( 'internlm2-chat-7b' ). deploy_method ( deploy . lightllm )
WebModule ( m ). start (). wait ()Documentos: https://lazyllm.readthedocs.io/
Para obtener más información y discusión, únase a nuestro servidor de discordia.
Este repositorio se publica bajo la licencia Apache-2.0.
Aprendimos mucho de los siguientes proyectos al desarrollar LightLLM.


