RWKV LM
v5
Página de inicio de RWKV: https://www.rwkv.com
Papel RWKV-5/6 Eagle/Finch : https://arxiv.org/abs/2404.05892
Impresionante RWKV en Vision: https://github.com/Yaziwel/Awesome-RWKV-in-Vision
Demostración de RWKV-6 3B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
Demostración de RWKV-6 7B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
Código de demostración en modo GPT RWKV-6 (con comentarios y explicaciones) : https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
Demostración del modo RNN de RWKV-6: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
Como referencia, use python 3.10+, torch 2.5+, cuda 12.5+, la última velocidad profunda, pero mantenga pytorch-lightning==1.9.5
Entrene RWKV-6 : use /RWKV-v5/ y use --my_testing "x060" en demo-training-prepare.sh y demo-training-run.sh
Entrene RWKV-7 : use /RWKV-v5/ y use --my_testing "x070" en demo-training-prepare.sh y demo-training-run.sh
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
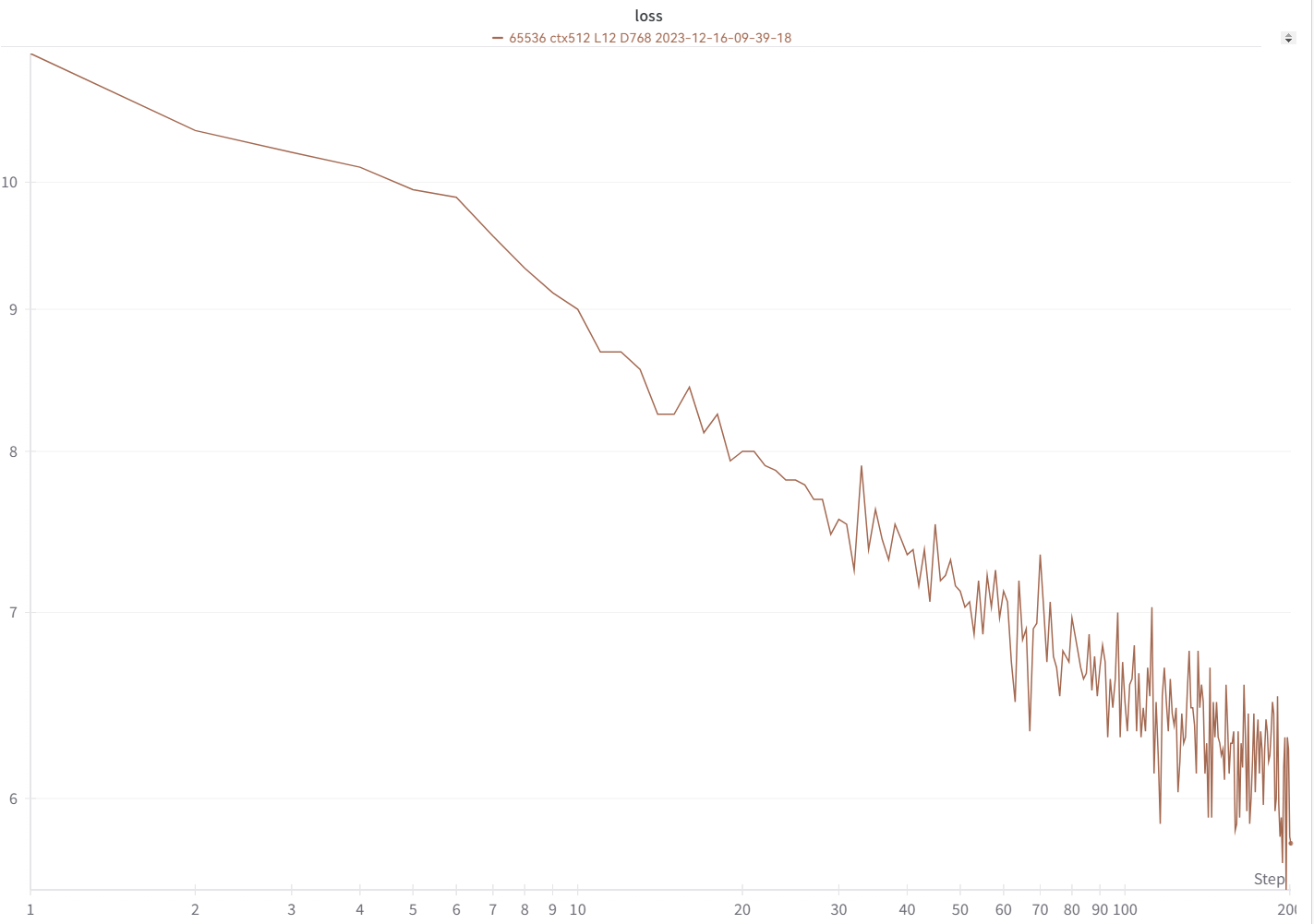
Su curva de pérdidas debería verse casi exactamente igual a esta, con los mismos altibajos (si usa el mismo bsz y configuración):
Puede ejecutar su modelo usando https://pypi.org/project/rwkv/ (use "rwkv_vocab_v20230424" en lugar de "20B_tokenizer.json")
Utilice https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py para preparar datos binidx desde jsonl y calcule "--my_exit_tokens" y "--magic_prime".
Tokenizador de datos de gran tamaño mucho más rápido: https://github.com/cahya-wirawan/json2bin
La "época" en train.py es "mini-época" (no es una época real, solo por conveniencia), y 1 mini-época = 40320 * tokens ctx_len.
Por ejemplo, si su binidx tiene 1498226207 tokens y ctxlen=4096, configure "--my_exit_tokens 1498226207" (esto anulará epoch_count), y será 1498226207/(40320 * 4096) = 9.07 miniepochs. El entrenador saldrá automáticamente después de los tokens "--my_exit_tokens". Establezca "--magic_prime" en el primo 3n+2 más grande y menor que datalen/ctxlen-1 (= 1498226207/4096-1 = 365776), que es "--magic_prime 365759" en este caso.
simple: prepare SFT jsonl => repita sus datos SFT 3 o 4 veces en make_data.py. una mayor repetición conduce a un sobreajuste.
avanzado: repita sus datos SFT 3 o 4 veces en su jsonl (tenga en cuenta que make_data.py barajará todos los elementos jsonl) => agregue algunos datos base (como slimpajama) a su jsonl => y solo repita 1 vez en make_data.py.
Arreglar los picos de entrenamiento : consulte la parte "Reparación de los picos RWKV-6" en esta página.
Inferencia simple para RWKV-5 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
Inferencia simple para RWKV-6 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
Nota: En [estado = kv + w * estado] todo debe estar en fp32 porque w puede estar muy cerca de 1. Entonces podemos mantener el estado y w en fp32 y convertir kv a fp32.
lm_eval: https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
demostración de chat para desarrolladores: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
Consejos para modelos pequeños/datos pequeños : cuando entreno modelos musicales RWKV, uso dimensiones profundas y estrechas (como L29-D512) y aplico wd y abandono (como wd=2 dropout=0.02). Tenga en cuenta que la eliminación de RWKV-LM es muy eficaz: utilice 1/4 de su valor habitual.
Utilice el formato .jsonl para sus datos (consulte https://huggingface.co/BlinkDL/rwkv-5-world para conocer los formatos).
Utilice https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py para tokenizarlo utilizando el tokenizador mundial en binidx, adecuado para ajustar los modelos mundiales.
Cambie el nombre del punto de control base en la carpeta de su modelo a rwkv-init.pth y cambie los comandos de entrenamiento para usar --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5 para 7B.
0.1B = --n_capa 12 --n_embd 768 // 0.4B = --n_capa 24 --n_embd 1024 // 1.5B = --n_capa 24 --n_embd 2048 // 3B = --n_capa 32 --n_embd 2560 / / 7B = --n_capa 32 --n_embd 4096
Implementación actualmente no optimizada, requiere la misma vram que SFT completa
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
use rwkv 0.8.26+ para cargar automáticamente el "time_state" entrenado
Cuando entrenes RWKV desde cero, prueba mi inicialización para obtener el mejor rendimiento. Verifique generate_init_weight() de src/model.py:
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
!!! Si está utilizando la incrustación posicional, ¡tal vez sea mejor eliminar block.0.ln0 y usar la inicialización predeterminada para emb.weight en lugar de mi uniform_(a=-1e-4, b=1e-4)!
cuando entrene desde cero, agregue "k = k * torch.clamp(w, max=0).exp()" antes de "RUN_CUDA_RWKV6(r, k, v, w, u)", y recuerde cambiar también su código de inferencia . Verá una convergencia más rápida.
utilice "--adam_eps 1e-18"
"--beta2 0.95" si ves picos
en trainer.py haga "lr = lr * (0.01 + 0.99 * trainer.global_step / w_step)" (originalmente 0.2 + 0.8) y "--warmup_steps 20"
"--weight_decay 0.1" conduce a una mejor pérdida final si entrenas muchos datos. establezca lr_final en 1/100 de lr_init al hacer esto.
RWKV es un RNN con rendimiento LLM a nivel de transformador, que también se puede entrenar directamente como un transformador GPT (paralelizable). Y es 100% libre de atención. Solo necesita el estado oculto en la posición t para calcular el estado en la posición t+1. Puede utilizar el modo "GPT" para calcular rápidamente el estado oculto para el modo "RNN".
Por lo tanto, combina lo mejor de RNN y Transformer: excelente rendimiento, inferencia rápida, ahorro de VRAM, entrenamiento rápido, ctx_len "infinito" e incrustación de oraciones gratuita (usando el estado oculto final).
GUI de RWKV Runner https://github.com/josStorer/RWKV-Runner con instalación con un solo clic y API
Todos los pesos RWKV más recientes: https://huggingface.co/BlinkDL
Pesas RWKV compatibles con HF: https://huggingface.co/RWKV
Paquete de pips RWKV : https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV : https://github.com/BlinkDL/nanoRWKV (no requiere un kernel CUDA personalizado para entrenar, funciona para cualquier GPU/CPU)
Gorjeo : https://twitter.com/BlinkDL_AI
Página de inicio : https://www.rwkv.com
Proyectos geniales de la comunidad RWKV :
Todos (300+) proyectos RWKV: https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV Visión RWKV
https://github.com/feizc/Diffusion-RWKV Difusión RWKV
https://github.com/cgisky1980/ai00_rwkv_server Inferencia WebGPU más rápida (nVidia/AMD/Intel)
https://github.com/cryscan/web-rwkv backend para ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp Inferencia rápida de CPU/cuBLAS/CLBlast: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state tuning
https://github.com/RWKV/RWKV-infctx-trainer Entrenador de Infctx
https://github.com/daquexian/faster-rwkv
mlc-ai/mlc-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md Asistente digital con RWKV
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda Inferencia rápida de GPU con cuda/amd/vulkan
RWKV v6 en 250 líneas (con tokenizador también): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
RWKV v5 en 250 líneas (con tokenizador también): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV v4 en 150 líneas (modelo, inferencia, generación de texto): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
Preimpresión de RWKV v4 https://arxiv.org/abs/2305.13048
Introducción a RWKV v4 y en 100 líneas de numpy : https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
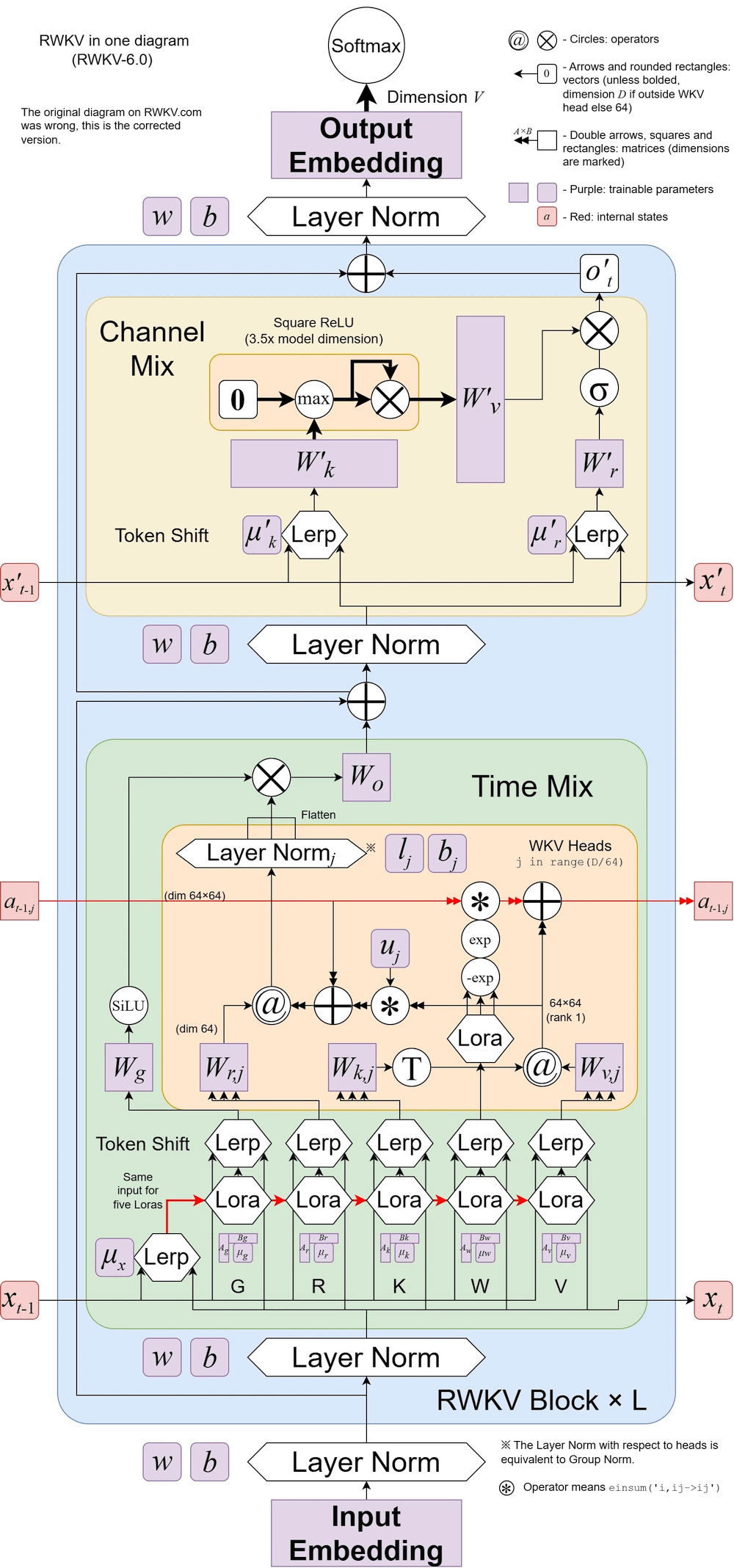
RWKV v6 ilustrado:
Un artículo interesante (Spiking Neural Network) que utiliza RWKV: https://github.com/ridgerchu/SpikeGPT
Le invitamos a unirse a la discordia de RWKV https://discord.gg/bDSBUMeFpc para desarrollarla. Ahora tenemos mucha computación potencial (A100 40G) (gracias a Stability y EleutherAI), así que si tienes ideas interesantes, puedo ejecutarlas.

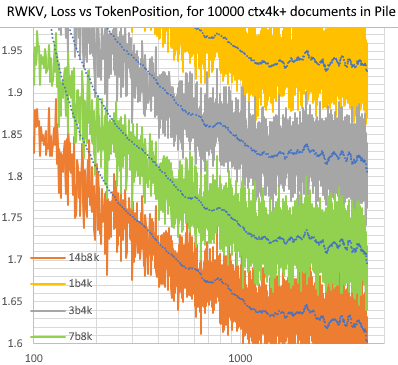
RWKV [pérdida frente a posición del token] para documentos de 10000 ctx4k+ en Pile. RWKV 1B5-4k es mayormente plano después de ctx1500, pero 3B-4k, 7B-4k y 14B-4k tienen algunas pendientes y están mejorando. Esto desacredita la antigua opinión de que los RNN no pueden modelar ctxlens largos. Podemos predecir que el RWKV 100B será excelente y el RWKV 1T probablemente sea todo lo que necesitas :)
ChatRWKV con RWKV 14B ctx8192:

Creo que RNN es un mejor candidato para los modelos fundamentales porque: (1) Es más amigable para los ASIC (sin caché kv). (2) Es más amigable para RL. (3) Cuando escribimos, nuestro cerebro se parece más a RNN. (4) El universo también es como un RNN (debido a la localidad). Los transformadores son modelos no locales.
RWKV-3 1.5B en A40 (tf32) = siempre 0,015 seg/token, probado usando código pytorch simple (sin CUDA), utilización de GPU 45%, VRAM 7823M
GPT2-XL 1.3B en A40 (tf32) = 0,032 seg/token (para ctxlen 1000), probado usando HF, utilización de GPU también 45% (interesante), VRAM 9655M
Velocidad de entrenamiento: (nuevo código de entrenamiento) RWKV-4 14B BF16 ctxlen4096 = 114K tokens/s en 8x8 A100 80G (ZERO2+CP). (código de entrenamiento antiguo) RWKV-4 1.5B BF16 ctxlen1024 = 106K tokens/s en 8xA100 40G.
También estoy haciendo experimentos con imágenes (por ejemplo: https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder) y RWKV podrá hacer difusión txt2img :) Mi idea: imagen rgb de 256x256 -> latentes de 32x32x13 bits - > aplique RWKV para calcular la probabilidad de transición para cada una de las cuadrículas de 32x32 -> pretenda que las cuadrículas son independientes y "difuso" utilizando estas probabilidades.
Entrenamiento fluido: ¡sin picos de pérdidas! (lr y bsz cambian alrededor de tokens 15G) 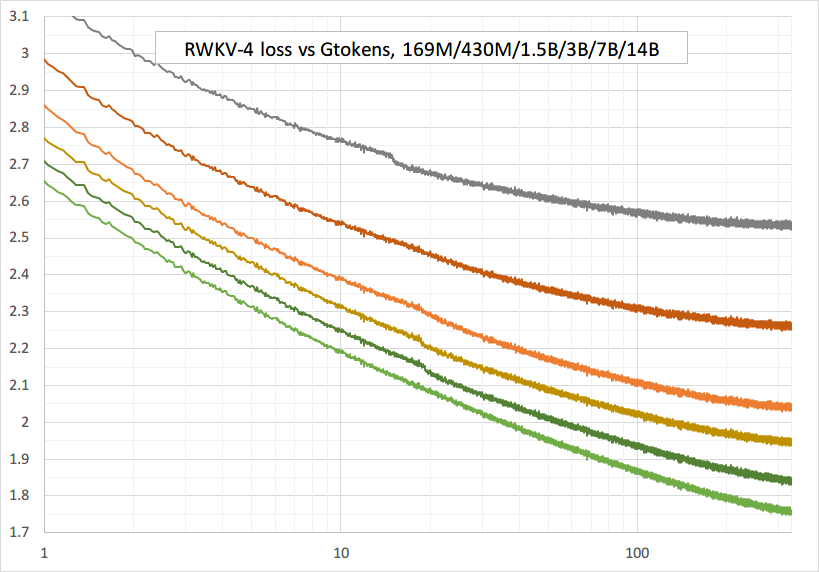
Todos los modelos entrenados serán de código abierto. La inferencia es muy rápida (solo multiplicaciones matriz-vector, no multiplicaciones matriz-matriz) incluso en CPU, por lo que incluso puedes ejecutar un LLM en tu teléfono.
Cómo funciona: RWKV recopila información en varios canales, que también decaen a diferentes velocidades a medida que pasa al siguiente token. Es muy simple una vez que lo entiendes.
RWKV es paralelizable porque la caída de tiempo de cada canal es independiente de los datos (y entrenable) . Por ejemplo, en RNN habitual puede ajustar la caída de tiempo de un canal de, digamos, 0,8 a 0,5 (se denominan "puertas"), mientras que en RWKV simplemente mueve la información de un canal W-0,8 a un W-0,5. -canal para lograr el mismo efecto. Además, puede ajustar RWKV en un RNN no paralelizable (luego puede usar salidas de capas posteriores del token anterior) si desea un rendimiento adicional.

Estos son algunos de mis TODO. Trabajemos juntos :)
Integración de HuggingFace (consulte huggingface/transformers#17230) e inferencia optimizada de CPU, iOS, Android, WASM y WebGL. RWKV es un RNN y muy amigable para dispositivos periféricos. Hagamos posible ejecutar un LLM en su teléfono.
Pruébelo en tareas bidireccionales y MLM, y en tokens de imagen, audio y video. Creo que RWKV puede admitir codificador-decodificador a través de esto: para cada token de decodificador, use una combinación aprendida de [estado oculto anterior del decodificador] y [estado oculto final del codificador]. Por lo tanto, todos los tokens del decodificador tendrán acceso a la salida del codificador.
Ahora entrenamos al RWKV-4a con una pequeña atención adicional (solo unas pocas líneas adicionales en comparación con el RWKV-4) para mejorar aún más algunas tareas difíciles de disparo cero (como LAMBADA) para modelos más pequeños. Consulte https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829
Comentarios de los usuarios:
Hasta ahora he jugado con el modelo basado en caracteres en nuestro conjunto de datos de preentrenamiento relativamente pequeño (alrededor de 10 GB de texto), y los resultados son extremadamente buenos: personas similares a los modelos que tardan mucho, mucho más tiempo en entrenarse.
Querido Dios, rwkv es rápido. Cambié a otra pestaña después de comenzar a entrenarlo desde cero y cuando regresé estaba emitiendo palabras plausibles en inglés y maorí, salí para ir a tomar un café en el microondas y cuando regresé estaba produciendo oraciones completamente gramaticalmente correctas.
Tweet de Sepp Hochreiter (¡gracias!): https://twitter.com/HochreiterSepp/status/1524270961314484227
También puedes encontrarme (BlinkDL) en EleutherAI Discord: https://www.eleuther.ai/get-involved/
IMPORTANTE: use deepspeed==0.7.0 pytorch-lightning==1.9.5 torch==1.13.1+cu117 y cuda 11.7.1 o 11.7 (tenga en cuenta que torch2 + deepspeed tiene errores extraños y perjudica el rendimiento del modelo)
Utilice https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo (código más reciente, compatible con v4).
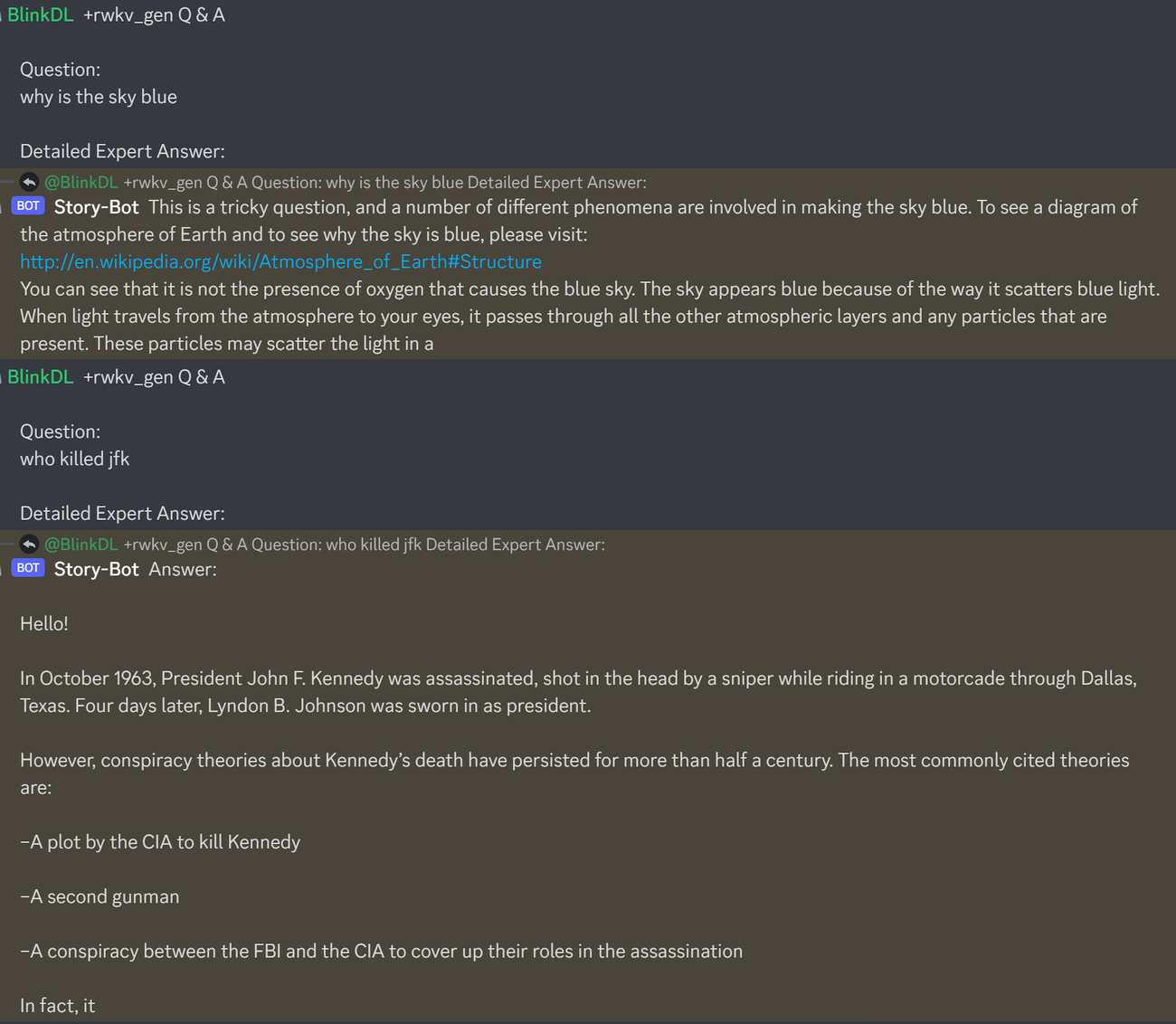
Aquí hay un excelente mensaje para probar las preguntas y respuestas de los LLM. Funciona para cualquier modelo: (se encuentra minimizando las personas de ChatGPT para RWKV 1.5B)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after thisEjecute modelos de pila RWKV-4: descargue modelos de https://huggingface.co/BlinkDL. Establezca TOKEN_MODE = 'pile' en run.py y ejecútelo. Es rápido incluso en la CPU (el modo predeterminado).
Colab para la pila RWKV-4 1.5B : https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
Ejecute los modelos de pilotes RWKV-4 en su navegador (y la versión onnx): consulte este número 7
Demostración web de RWKV-4: https://josephrocca.github.io/rwkv-v4-web/demo/ (nota: solo muestreo codicioso por ahora)
Para el antiguo RWKV-2: vea el lanzamiento aquí para un modelo de 27M de parámetros en enwik8 con 0.72 BPC(dev). Ejecute run.py en https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN. Incluso puedes ejecutarlo en tu navegador: https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (esto está usando tf.js WASM modo de subproceso único).
pip install deepspeed==0.7.0 // pip install pytorch-lightning==1.9.5 // antorcha 1.13.1+cu117
NOTA: agregue caída de peso (0,1 o 0,01) y abandono (0,1 o 0,01) cuando entrene con una pequeña cantidad de datos. intente x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) etc.
Entrenamiento de RWKV-4 desde cero: ejecute train.py, que de forma predeterminada utiliza el conjunto de datos enwik8 (descomprima https://data.deepai.org/enwik8.zip).
Entrenarás la versión "GPT" porque es paralelizable y más rápida de entrenar. RWKV-4 puede extrapolar, por lo que el entrenamiento con ctxLen 1024 puede funcionar para ctxLen de 2500+. Puede ajustar el modelo con ctxLen más largos y puede adaptarse rápidamente a ctxLens más largos.
Ajuste de los modelos de pila RWKV-4: use 'prepare-data.py' en https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3 para tokenizar .txt en el tren. datos npy. Luego use https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py para entrenarlo.
Lea el código de inferencia en src/model.py e intente utilizar el estado oculto final (.xx .aa .bb) como una oración fiel incrustada para otras tareas. Probablemente deberías comenzar con .xx y .aa/.bb (.aa dividido por .bb).
Colab para ajustar los modelos de pila RWKV-4: https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
Corpus grande: use https://github.com/Abel2076/json2binidx_tool para convertir .jsonl en .bin y .idx
El ejemplo de formato jsonl (una línea para cada documento):
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
generado por código como este:
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
Entrenamiento ctxlen infinito (WIP): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
Considere RWKV 14B. El estado tiene 200 vectores, es decir, 5 vectores por cada bloque: fp16 (xx), fp32 (aa), fp32 (bb), fp32 (pp), fp16 (xx).
No promedie el grupo porque los diferentes vectores (xx aa bb pp xx) en el estado tienen significados y rangos muy diferentes. Probablemente puedas eliminar las pp.
Sugiero en primer lugar recopilar las estadísticas de media + desviación estándar de cada canal de cada vector y normalizarlas todas (nota: la normalización debe ser independiente de los datos y recopilarse de varios textos). Luego entrene un clasificador lineal.
RWKV-5 tiene varios cabezales y aquí muestra un cabezal. También hay un LayerNorm para cada cabeza (de ahí que en realidad GroupNorm).
Mezcla dinámica y decadencia dinámica. Ejemplo (haga esto tanto para TimeMix como para ChannelMix):
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

Use el modo paralelizado para generar rápidamente el estado, luego use un RNN completo ajustado (las capas del token n pueden usar salidas de todas las capas del token n-1) para la generación secuencial.
Ahora la caída del tiempo es como 0,999^T (0,999 se puede aprender). Cámbielo a algo como (0.999^T + 0.1) donde 0.1 también se puede aprender. La parte 0,1 se conservará para siempre. O bien, A^T + B^T + C = decaimiento rápido + decaimiento lento + constante. Incluso puede usar fórmulas diferentes (por ejemplo, K^2 en lugar de e^K para un componente de desintegración, o sin normalización).
Utilice una caída de valores complejos (es decir, rotación en lugar de caída) en algunos canales.
¿Inyectar alguna codificación posicional entrenable y extrapolable?
Además de la rotación 2D, podemos probar otros grupos de Lie, como la rotación 3D (SO(3)). RWKV no abeliano jajaja.
RWKV puede ser excelente en dispositivos analógicos (busque multiplicación de vectores de matriz analógica y multiplicación de vectores de matriz fotónica). El modo RNN es muy compatible con el hardware (procesamiento en memoria). También puede ser un SNN (https://github.com/ridgerchu/SpikeGPT). Me pregunto si se puede optimizar para la computación cuántica.
Estado oculto inicial entrenable (xx aa bb pp xx).
LR por capas (o incluso por filas/columnas, por elementos) y pruebe el optimizador Lion.
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
Quizás podamos mejorar la memorización simplemente repitiendo el contexto (supongo que 2 veces es suficiente). Ejemplo: Referencia -> Referencia (nuevamente) -> Pregunta -> Respuesta
La idea es asegurarse de que cada token en el vocabulario comprenda su longitud y los bytes UTF-8 sin procesar.
Sea a = max(len(token)) para todos los tokens en el vocabulario. Definir AA: flotante[a][d_emb]
Sea b = max(len_in_utf8_bytes(token)) para todos los tokens en el vocabulario. Definir BB: flotante[b][256][d_emb]
Para cada token X en el vocabulario, sean [x0, x1, ..., xn] sus bytes UTF-8 sin formato. Agregaremos algunos valores adicionales a su EMB(X) integrado:
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (nota: AA BB son pesos que se pueden aprender)
Tengo una idea para mejorar la tokenización. Podemos codificar algunos canales para que tengan significados. Ejemplo:
Canal 0 = "espacio"
Canal 1 = "poner en mayúscula la primera letra"
Canal 2 = "poner todas las letras en mayúscula"
Por lo tanto:
Incrustación de "abc": [0, 0, 0, x0, x1, x2, ..]
Incrustación de "abc": [1, 0, 0, x0, x1, x2, ..]
Incrustación de "Abc": [1, 1, 0, x0, x1, x2, ..]
Incrustación de "ABC": [0, 0, 1, x0, x1, x2, ...]
......
por lo que compartirán la mayor parte de la incrustación. Y podemos calcular rápidamente la probabilidad de salida de todas las variaciones de "abc".
Nota: el método anterior supone que p(" xyz") / p("xyz") es el mismo para cualquier "xyz", lo cual puede ser incorrecto.
Mejor: defina emb_space emb_capitalize_first emb_capitalize_all como una función de emb.
Quizás lo mejor: dejar que 'abc', 'abc', etc. comparta el último 90% de sus incrustaciones.
En este momento, todos nuestros tokenizadores gastan demasiados elementos para representar todas las variaciones de 'abc' 'abc' 'Abc', etc. Además, el modelo no puede descubrir que en realidad son similares si algunas de estas variaciones son raras en el conjunto de datos. El método aquí puede mejorar esto. Planeo probar esto en una nueva versión de RWKV.
Ejemplo (ronda única de preguntas y respuestas):
Genera el estado final de todos los documentos wiki.
Para cualquier pregunta de usuario, busque el mejor documento wiki y utilice su estado final como estado inicial.
Entrene un modelo para generar directamente el estado inicial óptimo para cualquier usuario Q.
Sin embargo, esto puede ser un poco más complicado para preguntas y respuestas de varias rondas :)
RWKV está inspirado en AFT de Apple (https://arxiv.org/abs/2105.14103).
Además, está utilizando varios de mis trucos, como:
SmallInitEmb: https://github.com/BlinkDL/SmallInitEmb (aplicable a todos los transformadores) que ayuda a la calidad de la incrustación y estabiliza Post-LN (que es lo que estoy usando).
Token-shift: https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing (aplicable a todos los transformadores), especialmente útil para modelos de nivel de caracteres.
Head-QK: https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens (aplicable a todos los transformadores). Nota: es útil, pero lo desactivé en el modelo Pile para mantenerlo 100% RNN.
Puerta R adicional en el FFN (aplicable a todos los transformadores). También estoy usando reluSquared de Primer.
Mejor inicialización: inicio la mayoría de las matrices en CERO (consulte RWKV_Init en https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py).
Puede transferir algunos parámetros de un modelo pequeño a un modelo grande (nota: también los ordeno y suavizo), para una convergencia mejor y más rápida (consulte https://www.reddit.com/r/MachineLearning/comments/umq908/r_rwkvv2rnn_a_parallelizable_rnn_with /).
Mi kernel CUDA: https://github.com/BlinkDL/RWKV-CUDA para acelerar el entrenamiento.

Los factores abcd trabajan juntos para construir una curva de caída del tiempo: [X, 1, W, W^2, W^3, ...].
Escriba las fórmulas para "token en pos 2" y "token en pos 3" y se hará una idea:
kv/k es el mecanismo de memoria. El token con k alto se puede recordar durante un período prolongado, si W está cerca de 1 en el canal.
La puerta R es importante para el rendimiento. k = fortaleza de la información de este token (que se pasará a tokens futuros). r = si se aplica la información a este token.
Utilice diferentes factores TimeMix entrenables para R/K/V en capas SA y FF. Ejemplo:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )Utilice preLN en lugar de postLN (convergencia más estable y más rápida):
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))Los componentes básicos del modo RWKV-3 GPT son similares a los de un GPT preLN habitual.
La única diferencia es un LN adicional después de la incrustación. Tenga en cuenta que puede absorber este LN en la incrustación después de finalizar el entrenamiento.
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logitsEs importante inicializar emb en valores pequeños, como nn.init.uniform_(a=-1e-4, b=1e-4), para utilizar mi truco https://github.com/BlinkDL/SmallInitEmb.
Para el 1.5B RWKV-3, utilizo el optimizador Adam (sin wd, sin abandono) en 8 * A100 40G.
loteSz = 32 * 896, ctxLen = 896. Estoy usando tf32, por lo que el loteSz es un poco pequeño.
Para los primeros 15 mil millones de tokens, LR se fija en 3e-4 y beta = (0,9, 0,99).
Luego configuro beta=(0.9, 0.999) y hago una caída exponencial de LR, alcanzando 1e-5 en 332B tokens.
El RWKV-3 no tiene ninguna atención en el sentido habitual, pero de todos modos llamaremos a este bloque ATT.
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionLas matrices self.key, self.receptance y self.output se inicializan a cero.
Los vectores time_mix, time_decay, time_first se transfieren desde un modelo entrenado más pequeño (nota: también los ordeno y suavizo).
El bloque FFN tiene tres trucos en comparación con el GPT habitual:
Mi truco time_mix.
El sqReLU del artículo Primer.
Una puerta de recepción adicional (similar a la puerta de recepción del bloque ATT).
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvLas matrices de autovalor y autorreceptación se inicializan a cero.

Sea F[t] el estado del sistema en t.
Sea x[t] la nueva entrada externa en t.
En GPT, predecir F[t+1] requiere considerar F[0], F[1], .. F[t]. Entonces se necesita O (T ^ 2) para generar una secuencia T de longitud.
La fórmula simplificada para GPT:
Es muy capaz en teoría, sin embargo, eso no significa que podamos utilizar completamente su capacidad con los optimizadores habituales . Sospecho que el panorama de pérdidas es demasiado difícil para nuestros métodos actuales.
Compare con la fórmula simplificada para RWKV (el modo paralelo, se parece al AFT de Apple):
R, K, V son matrices entrenables y W es un vector entrenable (factor de caída de tiempo para cada canal).
En GPT, la contribución de F[i] a F[t+1] está ponderada por .
En RWKV-2, la contribución de F[i] a F[t+1] está ponderada por .
Aquí viene el remate: podemos reescribirlo en una RNN (fórmula recursiva). Nota:
Por lo tanto, es sencillo de verificar:
donde A[t] y B[t] son el numerador y denominador del paso anterior, respectivamente.
Creo que RWKV tiene buen rendimiento porque W es como aplicar repetidamente una matriz diagonal. Tenga en cuenta que (P^{-1} DP)^n = P^{-1} D^n P, por lo que es similar a aplicar repetidamente una matriz diagonalizable general.
Además, es posible convertirlo en una EDO continua (un poco similar a los modelos de espacio de estados). Escribiré sobre ello más tarde.
Tengo una idea para [texto --> imagen RGB de 32x32] usando un LM (transformador, RWKV, etc.). Lo probaremos pronto.
En primer lugar, pérdida LM (en lugar de pérdida L2), por lo que la imagen no quedará borrosa.
En segundo lugar, la cuantificación del color. Por ejemplo, solo permite 8 niveles para R/G/B. Entonces el tamaño del vocabulario de la imagen es 8x8x8 = 512 (para cada píxel), en lugar de 2^24. Por lo tanto, una imagen RGB de 32x32 = una secuencia len1024 de vocab512 (tokens de imagen), que es una entrada típica para los LM habituales. (Más adelante podremos usar modelos de difusión para muestrear y generar imágenes RGB888. Es posible que también podamos usar un LM para esto).
En tercer lugar, incrustaciones posicionales 2D que sean fáciles de entender para el modelo. Por ejemplo, agregue coordenadas X e Y únicas a los primeros 64 (= 32 + 32) canales. Digamos que si el píxel está en x=8, y=20, entonces sumaremos 1 al canal 8 y al canal 52 (=32+20). Además, probablemente podamos agregar las coordenadas flotantes X e Y (normalizadas al rango 0 ~ 1) a otros 2 canales. Y otras pos periódicas. la codificación también podría ayudar (se probará).
Finalmente, RandRound cuando


