CAMEL
1.0.0

Estamos orgullosos de presentar Asclepius , un modelo clínico de lenguaje grande más avanzado. Como este modelo se entrenó a partir de notas clínicas sintéticas, es accesible públicamente a través de Huggingface. Si está considerando utilizar CAMEL, le recomendamos encarecidamente que cambie a Asclepius. Para obtener más información, visite este enlace.
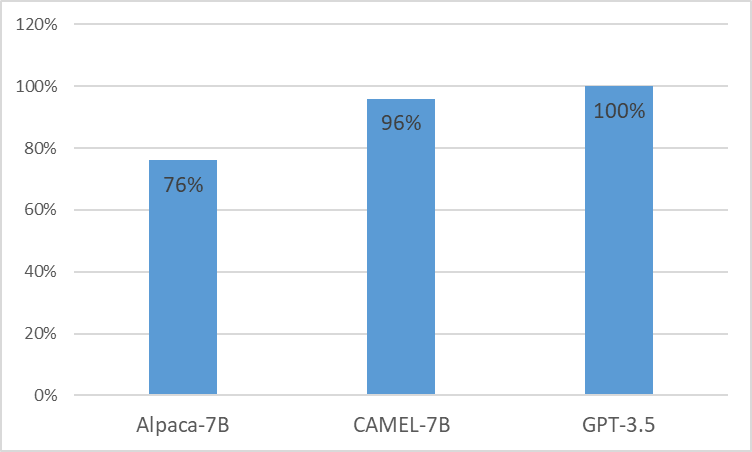
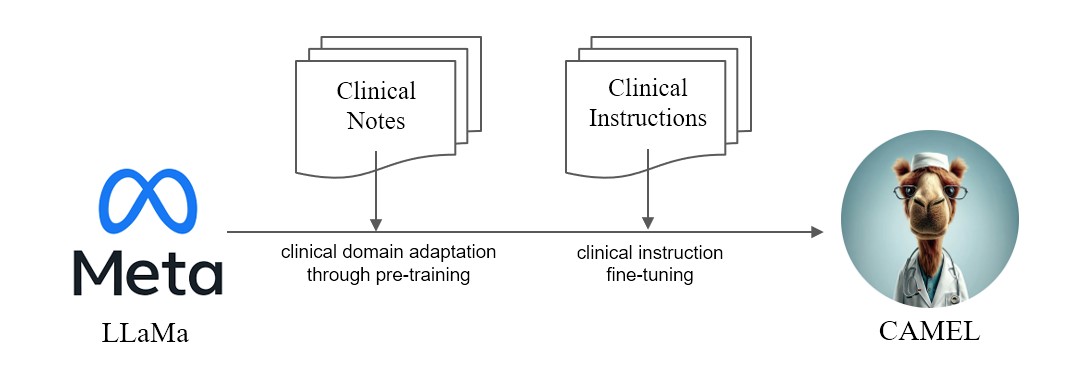
Presentamos CAMEL , Modelo Clínicamente Adaptado Mejorado de LLaMA. Como LLaMA para su fundación, CAMEL recibe capacitación previa en notas clínicas MIMIC-III y MIMIC-IV, y se perfecciona en instrucciones clínicas (Figura 2). Nuestra evaluación preliminar con la evaluación GPT-4 demuestra que CAMEL logra más del 96% de la calidad de GPT-3.5 de OpenAI (Figura 1). De acuerdo con las políticas de uso de datos de nuestros datos fuente, tanto nuestro conjunto de datos de instrucción como nuestro modelo se publicarán en PhysioNet con acceso acreditado. Para facilitar la replicación, también publicaremos todo el código, lo que permitirá a las instituciones sanitarias individuales reproducir nuestro modelo utilizando sus propias notas clínicas. Para obtener más detalles, consulte nuestra publicación de blog .
Debido al problema de licencia de los conjuntos de datos MIMIC e i2b2, no podemos publicar el conjunto de datos de instrucciones y los puntos de control. Publicaremos nuestro modelo y datos a través de psychonet en unas pocas semanas.
conda create -n camel python=3.9 -y
conda activate camel
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia -y
pip install pandarallel pandas jupyter numpy datasets sentencepiece openai fire
pip install git+https://github.com/huggingface/transformers.git@871598be552c38537bc047a409b4a6840ba1c1e4
<eos> .$ python pretraining_preprocess/mimiciii_preproc.py --mimiciii_note_path {MIMICIII_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/mimiciv_preproc.py --discharge_note_path {DISCHAGE_NOTE_PATH} --radiology_note_path {RADIOLOGY_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/tokenize_data.py --data_path {DATA_PATH} --save_path {SAVE_PATH} $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/train.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {DATA_FILE}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 1
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
NOTA: Para generar instrucciones, debe utilizar la API certificada de Azure Openai.
Generación de instrucciones
OPENAI_API_KEYOPENAI_API_BASEOPENAI_DEPLOYMENT_NAME$ python instructino/preprocess_note.py$ python instruction/de_id_gen.py --input {PREPROCESSED_NOTES} --output {OUTPUT_FILE_1} --mode inst$ python instruction/de_id_postprocess.py --input {OUTPUT_FILE_1} --output {OUTPUT_FILE_2}$ python instruction/de_id_gen.py --input {OUTPUT__FILE_2} --output {inst_output/OUTPUT_FILE_deid} --mode ans$ python instruction/instructtion_gen.py --input {PREPROCESSED_NOTES} --output {inst_output/OUTPUT_FILE} --source {mimiciii, mimiciv, i2b2}$ python instruction/merge_data.py --data_path {inst_output} --output {OUTPUT_FILE_FINAL}Ejecutar ajuste de instrucciones
nproc_per_node y gradient accumulate step para que se ajuste a su hardware (tamaño de lote global = 128). $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/instruction_ft.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {OUTPUT_FILE_FINAL}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "epoch"
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
--ddp_timeout 18000
Ejecutar modelo en MTSamples
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py
--model_name {MODEL_PATH}
--data_path eval/mtsamples_instructions.json
--output_path {OUTPUT_PATH}
mtsamples_results.json en la carpeta eval .Ejecute GPT-4 para evaluación
python eval/gpt4_evaluate.py --input {INPUT_PATH} --output {OUTPUT_PATH}
@misc{CAMEL,
title = {CAMEL : Clinically Adapted Model Enhanced from LLaMA},
author = {Sunjun Kweon and Junu Kim and Seongsu Bae and Eunbyeol Cho and Sujeong Im and Jiyoun Kim and Gyubok Lee and JongHak Moon and JeongWoo Oh and Edward Choi},
month = {May},
year = {2023}
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/starmpcc/CAMEL}},
}


