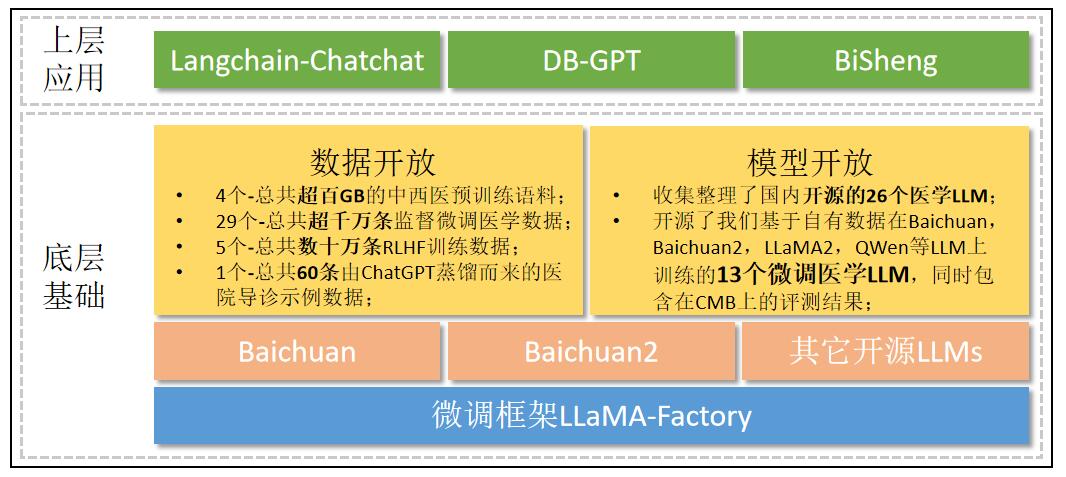
CareGPT
1.0.0
chino | inglés
Vídeotutorial Instalación e implementación experiencia en línea

⚡Características:
conda create - n llm python = 3.11
conda activate llm
python - m pip install - r requirements . txt # 转为HF格式
python - m transformers . models . llama . convert_llama_weights_to_hf
- - input_dir path_to_llama_weights - - model_size 7 B - - output_dir path_to_llama_model Si utiliza un conjunto de datos personalizado, asegúrese de proporcionar su definición de conjunto de datos en el archivo dataset_info.json en el siguiente formato.
"数据集名称" : {
"hf_hub_url" : " HuggingFace上的项目地址(若指定,则忽略下列三个参数) " ,
"script_url" : "包含数据加载脚本的本地文件夹名称(若指定,则忽略下列两个参数) " ,
"file_name" : "该目录下数据集文件的名称(若上述参数未指定,则此项必需) " ,
"file_sha1" : "数据集文件的SHA-1哈希值(可选) " ,
"columns" : {
"prompt" : "数据集代表提示词的表头名称(默认:instruction) " ,
"query" : "数据集代表请求的表头名称(默认:input) " ,
"response" : "数据集代表回答的表头名称(默认:output) " ,
"history" : "数据集代表历史对话的表头名称(默认:None) "
}
} Las columnas prompt y response no deben ser cadenas vacías. El contenido de la columna de query se concatenará con la columna prompt como entrada del modelo. La columna history debe ser una lista, donde cada elemento es una tupla de cadena que representa la solicitud del usuario y la respuesta del modelo, respectivamente.
Formato .txt , un dato no supervisado por línea.
Machine learning (ML) is a field devoted to understanding and building methods that let machines "learn" – that is, methods that leverage data to improve computer performance on some set of tasks.
Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, speech recognition, agriculture, and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks.[
{
"instruction" : "听起来很不错。人工智能可能在哪些方面面临挑战呢? " ,
"input" : " " ,
"output" : "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。 " ,
"history" : [
[ "你好,你能帮我解答一个问题吗? " , "当然,请问有什么问题? " ],
[ "我想了解人工智能的未来发展方向,你有什么想法吗? " , "人工智能在未来的发展方向可能包括更强大的机器学习算法,更先进的自然语言处理技术,以及更加智能的机器人。 " ]
]
}
][
{
"instruction" : "听起来很不错。人工智能可能在哪些方面面临挑战呢? " ,
"input" : " " ,
"output" : "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。 " ,
"history" : []
}
][
{
"instruction" : "生成三个与“道歉”意思相同的动词" ,
"input" : " " ,
"output" : [
"承认,表示遗憾,弥补。 " ,
"道歉"
]
}
] Compruebe si su tarjeta gráfica está conectada con NVLINK. Solo con la conexión NVLINK puede utilizar accelerate de manera efectiva para el entrenamiento acelerado en paralelo.
nvidia-smi topo -m
accelerate config # configure the environment
accelerate launch src / train_bash . py # arguments (same as above) # LLaMA-2
accelerate launch src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_train
- - dataset mm
- - finetuning_type lora
- - quantization_bit 4
- - overwrite_cache
- - output_dir output
- - per_device_train_batch_size 8
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 2.0
- - plot_loss
- - fp16
- - template llama2
- - lora_target q_proj , v_proj
# LLaMA
accelerate launch src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_train
- - dataset mm , hm
- - finetuning_type lora
- - overwrite_cache
- - output_dir output - 1
- - per_device_train_batch_size 4
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 2000
- - learning_rate 5e-5
- - num_train_epochs 2.0
- - plot_loss
- - fp16
- - template default
- - lora_target q_proj , v_proj # LLaMA-2, DPO
accelerate launch src / train_bash . py
- - stage dpo
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_train
- - dataset rlhf
- - template llama2
- - finetuning_type lora
- - quantization_bit 4
- - lora_target q_proj , v_proj
- - resume_lora_training False
- - checkpoint_dir . / output - 2
- - output_dir output - dpo
- - per_device_train_batch_size 2
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 1e-5
- - num_train_epochs 1.0
- - plot_loss
- - fp16 # LLaMA-2
python src / web_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / web_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / web_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2 # LLaMA-2
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / api_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2API de prueba:
curl - X 'POST'
'http://127.0.0.1:8888/v1/chat/completions'
- H 'accept: application/json'
- H 'Content-Type: application/json'
- d ' {
"model" : "string",
"messages": [
{
"role" : "user",
"content": "你好"
}
],
" temperature ": 0 ,
"top_p" : 0 ,
"max_new_tokens" : 0 ,
"stream" : false
}' # LLaMA-2
python src / cli_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / cli_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / cli_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2 # LLaMA-2
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_predict
- - dataset mm
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir predict_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_predict
- - dataset mm
- - template default
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir predict_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate # LLaMA-2
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_eval
- - dataset mm
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir eval_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_eval
- - dataset mm
- - template default
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir eval_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate Para evaluación de 4/8 bits, se recomienda utilizar --per_device_eval_batch_size=1 y --max_target_length 128
# LLaMA-2
python src / export_model . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir output_export
# LLaMA
python src / export_model . py
- - model_name_or_path . / Llama - 7 b - hf
- - template default
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir output_export % cd Gradio
python app . py 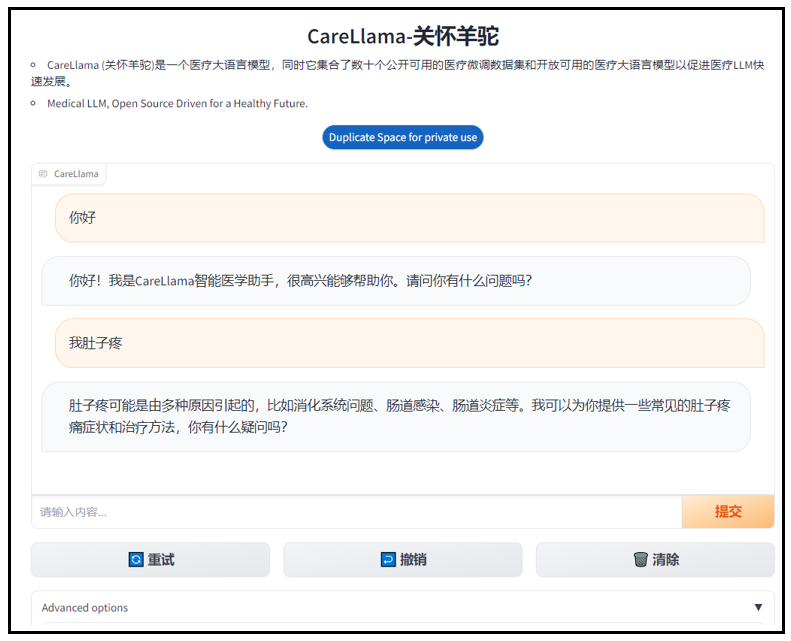
# LLaMA-2
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / api_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default设置, modifique接口地址a: http://127.0.0.1:8000/ (es decir, la dirección de su interfaz API) y luego podrá usarla. 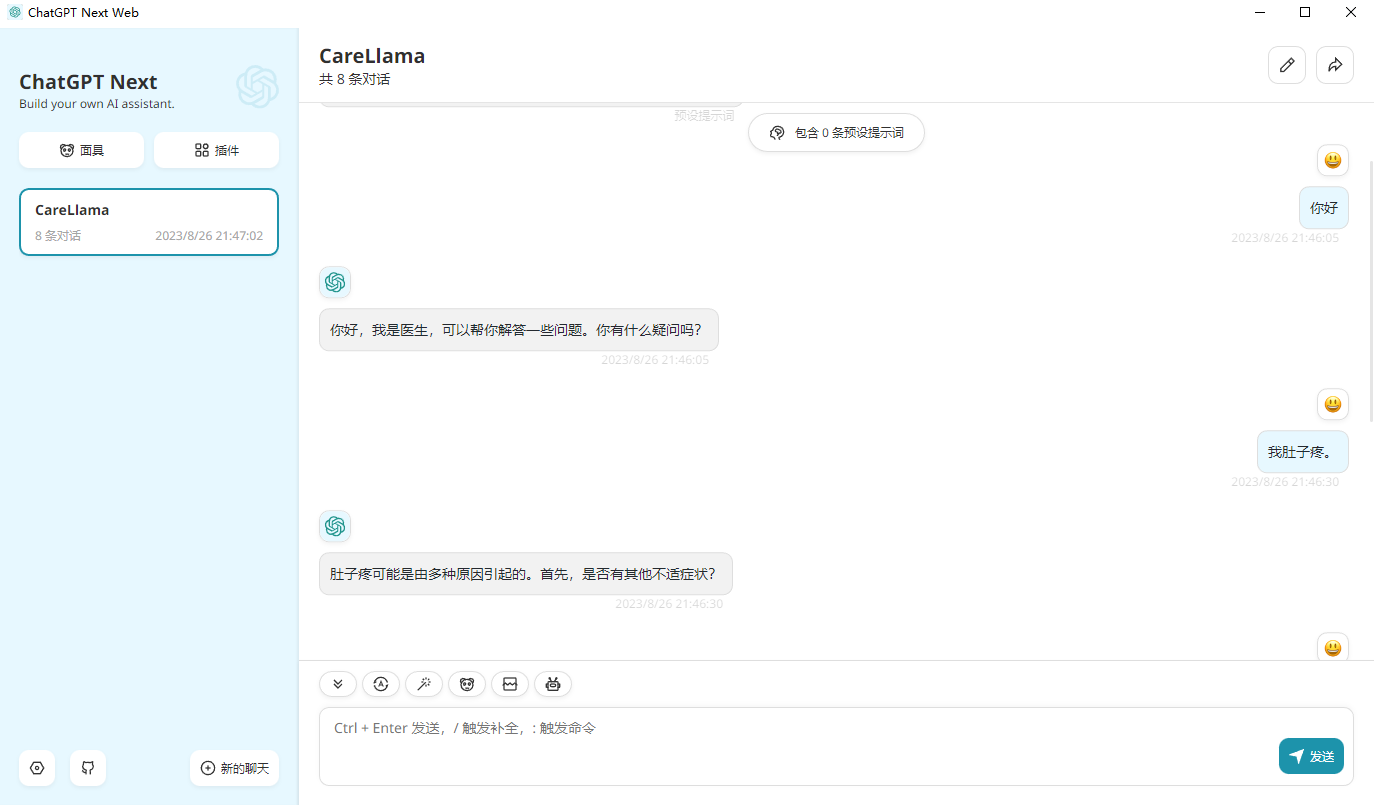
PubMed Central y PubMed Abstracts . Estos valiosos textos han enriquecido enormemente el sistema de conocimiento médico del modelo BLOOMZ, por lo que muchos proyectos de código abierto darán prioridad a BLOOMZ como modelo base para el ajuste médico;质量> 数量es la verdad, como: ¡Menos es más! Entregado a Qingyuan && Caspian Utilice 200 datos para ajustar el modelo, superando ¡MiniGPT-4! , los datos SFT a gran escala debilitarán el LLM de tareas posteriores o perderán ICL, CoT y otras capacidades;大规模预训练+小规模监督微调=超强的LLM模型;英文10B以下选择Mistral-7B中文, 10B以下选择Yi-6B 10B y 10B以上选择Qwen-14B和Yi-34B ; Importante
¡Todos son bienvenidos a agregar nuevas experiencias a ISSUE!
11 ~ 13 La metodología proviene de 13 mil millones de modelos de lenguaje grandes. ¡Cambiar solo un peso perderá por completo la capacidad del lenguaje! Las últimas investigaciones del Laboratorio de Procesamiento del Lenguaje Natural de la Universidad de Fudan.
14 Metodología de cómo las habilidades en modelos de lenguaje grandes se ven afectadas por la composición de datos de ajuste supervisado
La metodología 17 ~ 25 proviene de la optimización LLM: interpretación de la versión china de adaptación de rango óptimo (LORA) por capas
| escenario | Introducción a las pesas | Descargar dirección | Características | modelo base | método de ajuste fino | conjunto de datos |
|---|---|---|---|---|---|---|
| ?Supervisión y puesta a punto | Los datos de diálogo de varios turnos se entrenan en base a LLaMA2-7b-Chat | CareLlama2-7b-chat-sft-multi、?CareLlama2-7b-multi | Excelentes habilidades de conversación en varios turnos. | LLaMA2-7b-Chat | QLoRA | milímetros |
| Supervisar el ajuste | Se entrenan datos ricos y eficientes del diálogo médico-paciente en base a LLaMA2-7b-Chat | CareLlama2-7b-chat-sft-med | Excelentes capacidades de diagnóstico de enfermedades del paciente. | LLaMA2-7b-Chat | QLoRA | mmm |
| supervisar |


