DiGIT
1.0.0
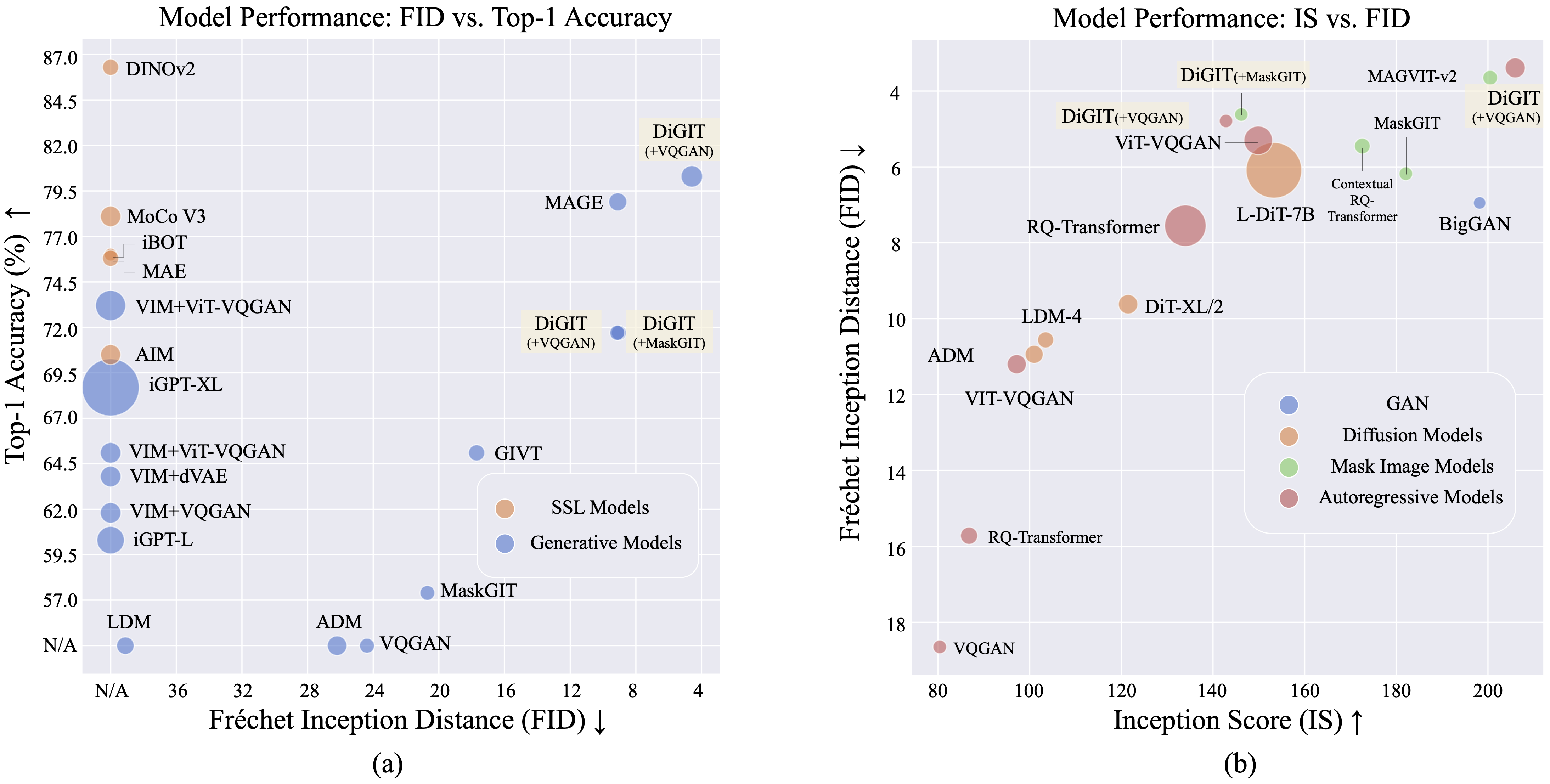
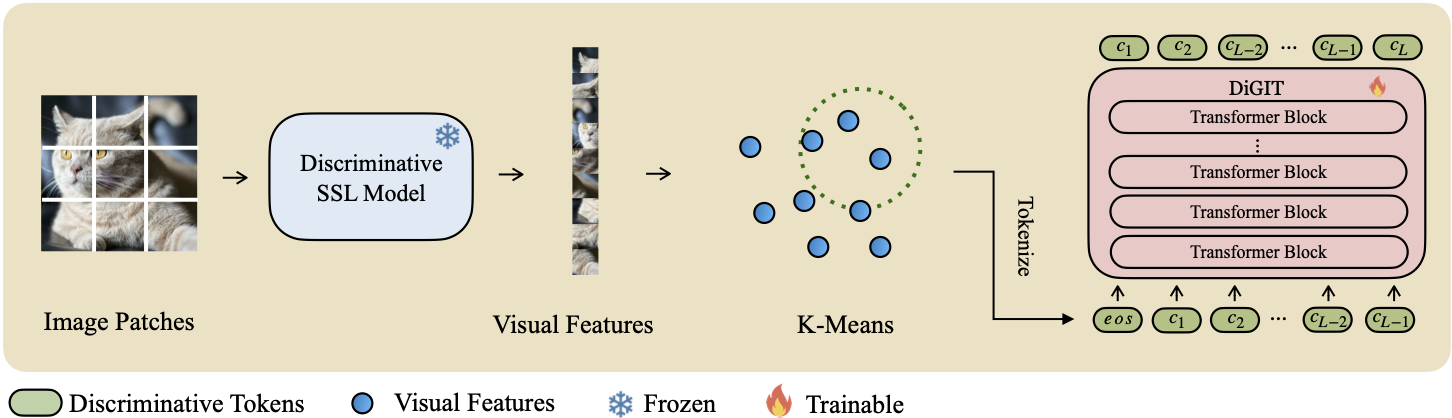
Presentamos DiGIT , un modelo generativo autorregresivo que realiza la predicción del siguiente token en un espacio latente abstracto derivado de modelos de aprendizaje autosupervisado (SSL). Al emplear la agrupación de K-Means en los estados ocultos del modelo DINOv2, creamos efectivamente un novedoso tokenizador discreto. Este método aumenta significativamente el rendimiento de generación de imágenes en el conjunto de datos ImageNet, logrando una puntuación FID de 4,59 para tareas incondicionales de clase y 3,39 para tareas condicionales de clase . Además, el modelo mejora la comprensión de la imagen, logrando una precisión de sonda lineal de 80,3 .
| Métodos | # fichas | Características | # parámetros | Top-1 Acc. |
|---|---|---|---|---|
| iGPT-L | 32 | 1536 | 1362M | 60.3 |
| iGPT-XL | 64 | 3072 | 6801M | 68,7 |
| VIM+VQGAN | 32 | 1024 | 650M | 61,8 |
| VIM+dVAE | 32 | 1024 | 650M | 63,8 |
| VIM+ViT-VQGAN | 32 | 1024 | 650M | 65.1 |
| VIM+ViT-VQGAN | 32 | 2048 | 1697M | 73.2 |
| APUNTAR | 16 | 1536 | 0,6 mil millones | 70,5 |
| DiGIT (Nuestro) | 16 | 1024 | 219M | 71,7 |
| DiGIT (Nuestro) | 16 | 1536 | 732M | 80.3 |
| Tipo | Métodos | # parámetro | # Época | DEFENSOR | ES |
|---|---|---|---|---|---|
| Ganar | GranGAN | 70M | - | 38,6 | 24,70 |
| Dif. | LDM | 395M | - | 39.1 | 22,83 |
| Dif. | ADM | 554M | - | 26.2 | 39,70 |
| MIM | MAGO | 200M | 1600 | 11.1 | 81.17 |
| MIM | MAGO | 463M | 1600 | 9.10 | 105.1 |
| MIM | MáscaraGIT | 227M | 300 | 20.7 | 42.08 |
| MIM | Dígito (+MáscaraGIT) | 219M | 200 | 9.04 | 75.04 |
| Arkansas | VQGAN | 214M | 200 | 24.38 | 30,93 |
| Arkansas | DíGITO (+VQGAN) | 219M | 400 | 9.13 | 73,85 |
| Arkansas | DíGITO (+VQGAN) | 732M | 200 | 4.59 | 141,29 |
| Tipo | Métodos | # parámetro | # Época | DEFENSOR | ES |
|---|---|---|---|---|---|
| Ganar | GranGAN | 160M | - | 6,95 | 198.2 |
| Dif. | ADM | 554M | - | 10.94 | 101.0 |
| Dif. | LDM-4 | 400M | - | 10.56 | 103,5 |
| Dif. | DiT-XL/2 | 675M | - | 9.62 | 121,50 |
| Dif. | L-DiT-7B | 7B | - | 6.09 | 153,32 |
| MIM | CQR-Trans | 371M | 300 | 5.45 | 172,6 |
| MIM+AR | var | 310M | 200 | 4.64 | - |
| MIM+RA | var | 310M | 200 | 3,60* | 257,5* |
| MIM+AR | var | 600M | 250 | 2,95* | 306.1* |
| MIM | MAGVIT-v2 | 307M | 1080 | 3.65 | 200,5 |
| Arkansas | VQVAE-2 | 13,5 mil millones | - | 31.11 | 45 |
| Arkansas | RQ-Trans | 480M | - | 15,72 | 86,8 |
| Arkansas | RQ-Trans | 3,8 mil millones | - | 7.55 | 134.0 |
| Arkansas | ViTVQGAN | 650M | 360 | 11.20 | 97,2 |
| Arkansas | ViTVQGAN | 1,7 mil millones | 360 | 5.3 | 149,9 |
| MIM | MáscaraGIT | 227M | 300 | 6.18 | 182.1 |
| MIM | Dígito (+MáscaraGIT) | 219M | 200 | 4.62 | 146.19 |
| Arkansas | VQGAN | 227M | 300 | 18.65 | 80,4 |
| Arkansas | DíGITO (+VQGAN) | 219M | 400 | 4.79 | 142,87 |
| Arkansas | DíGITO (+VQGAN) | 732M | 200 | 3.39 | 205.96 |
*: VAR se entrena con guía sin clasificador, mientras que todos los demás modelos no.
El archivo K-Means npy y los puntos de control del modelo se pueden descargar desde:
| Modelo | Enlace |
|---|---|
| ¿Pesas HF? | abrazando cara |
Para el modelo base utilizamos DINOv2-base y DINOv2-large para el modelo de gran tamaño. El VQGAN que utilizamos es el mismo que MAGE.
DiGIT
└── data/
├── ILSVRC2012
├── dinov2_base_short_224_l3
├── km_8k.npy
├── dinov2_large_short_224_l3
├── km_16k.npy
└── outputs/
├── base_8k_stage1
├── ...
└── models/
├── vqgan_jax_strongaug.ckpt
├── dinov2_vitb14_reg4_pretrain.pth
├── dinov2_vitl14_reg4_pretrain.pth
git clone https://github.com/DAMO-NLP-SG/DiGIT.git
cd DiGITfairseq mediante pip install fairseq . Descargue el conjunto de datos ImageNet y colóquelo en el directorio de su conjunto de datos $PATH_TO_YOUR_WORKSPACE/dataset/ILSVRC2012 .
Extraiga funciones SSL y guárdelas como archivos .npy. Utilice el algoritmo K-Means con faiss para calcular los centroides. También puede utilizar nuestros centroides previamente entrenados disponibles en Huggingface.
bash preprocess/run.shPaso 1
Entrene un modelo GPT con un tokenizador discriminativo. Puede encontrar los scripts de entrenamiento en scripts/train_stage1_ar.sh y los hiperparámetros están en config/stage1/dino_base.yaml . Para la configuración de generación condicional de clases, consulte scripts/train_stage1_classcond.sh .
Paso 2
Entrene un decodificador de píxeles (ya sea modelo AR o modelo NAR) condicionado a los tokens discriminativos. Puede encontrar los scripts de entrenamiento autorregresivos en scripts/train_stage2_ar.sh y los scripts de entrenamiento NAR en scripts/train_stage2_nar.sh .
Se creará una carpeta llamada outputs/EXP_NAME/checkpoints para guardar los puntos de control. Los archivos de registro de TensorBoard se guardan en outputs/EXP_NAME/tb . Los registros se registrarán en outputs/EXP_NAME/train.log .
Puede monitorear el proceso de capacitación usando tensorboard --logdir=outputs/EXP_NAME/tb .
Primer muestreo de tokens discriminativos con scripts/infer_stage1_ar.sh . Para el tamaño del modelo base, recomendamos configurar topk=200, y para un tamaño de modelo grande, use topk=400.
Luego ejecute scripts/infer_stage2_ar.sh para muestrear tokens VQ en función de los tokens discriminativos muestreados previamente.
Los tokens generados y las imágenes sintetizadas se almacenarán en un directorio llamado outputs/EXP_NAME/results .
Prepare el conjunto de validación de ImageNet para la evaluación FID:
python prepare_imgnet_val.py --data_path $PATH_TO_YOUR_WORKSPACE /dataset/ILSVRC2012 --output_dir imagenet-val Instale la herramienta de evaluación ejecutando pip install torch-fidelity .
Ejecute el siguiente comando para evaluar FID:
python fairseq_user/eval_fid.py --results-path $IMG_SAVE_DIR --subset $GEN_SUBSETbash scripts/train_stage1_linearprobe.shEste proyecto tiene la licencia MIT; consulte el archivo de LICENCIA para obtener más detalles.
Si encuentra útil nuestro proyecto, espero que pueda destacar nuestro repositorio y citar nuestro trabajo de la siguiente manera.
@misc { zhu2024stabilize ,
title = { Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective } ,
author = { Yongxin Zhu and Bocheng Li and Hang Zhang and Xin Li and Linli Xu and Lidong Bing } ,
year = { 2024 } ,
eprint = { 2410.12490 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

