PatrickStar
v0.4.6

Consulte CHANGE_LOG.md.
Los modelos preentrenados (PTM) se están convirtiendo en el punto de acceso tanto para la investigación de PNL como para su aplicación industrial. Sin embargo, la capacitación de PTM requiere enormes recursos de hardware, por lo que solo es accesible para una pequeña porción de personas en la comunidad de IA. ¡Ahora, PatrickStar pondrá la capacitación PTM a disposición de todos!
El error de falta de memoria (OOM) es la pesadilla de todo ingeniero que entrena PTM. A menudo tenemos que introducir más GPU para almacenar los parámetros del modelo y evitar este tipo de errores. PatrickStar trae una mejor solución para tal problema. Con el entrenamiento heterogéneo (DeepSpeed Zero Stage 3 también lo usa), PatrickStar podría usar completamente la memoria de la CPU y la GPU, de modo que podría usar menos GPU para entrenar modelos más grandes.
La idea de Patrick es así. Los datos que no son del modelo (principalmente activaciones) varían durante el entrenamiento, pero las soluciones de entrenamiento heterogéneas actuales dividen estáticamente los datos del modelo en CPU y GPU. Para utilizar mejor la GPU, PatrickStar propone una programación dinámica de la memoria con la ayuda de un módulo de gestión de memoria basado en fragmentos. La administración de memoria de PatrickStar admite la descarga de todo excepto la parte informática actual del modelo a la CPU para ahorrar GPU. Además, la administración de memoria basada en fragmentos es eficiente para la comunicación colectiva cuando se escala a múltiples GPU. Consulte el artículo y este documento para conocer la idea detrás de PatrickStar.
En el experimento, Patrickstar v0.4.3 puede entrenar un modelo de parámetros de 18 mil millones (18B) con 8 GPU Tesla V100 y 240 GB de memoria GPU en el nodo del centro de datos WeChat, cuya topología de red es así. PatrickStar es más del doble de grande que DeepSpeed. Y el rendimiento de PatrickStar también es mejor para modelos del mismo tamaño. La pstar es PatrickStar v0.4.3. Las profundidades indican el rendimiento de DeepSpeed v0.4.3 utilizando el ejemplo oficial de la etapa Zero3 del ejemplo de DeepSpeed con optimizaciones de activación abriéndose de forma predeterminada.

También evaluamos PatrickStar v0.4.3 en un solo nodo del A100 SuperPod. Puede entrenar el modelo 68B en 8xA100 con memoria de CPU de 1TB, que es más de 6 veces más grande que DeepSpeed v0.5.7. Además de la escala del modelo, PatrickStar es mucho más eficiente que DeepSpeed. Los scripts de referencia están aquí.

Los resultados detallados de las pruebas comparativas del centro de datos WeChat AI y NVIDIA SuperPod se publican en este documento de Google.
Escale PatrickStar a varias máquinas (nodo) en SuperPod. Logramos entrenar un GPT3-175B en 32 GPU. Hasta donde sabemos, es el primer trabajo que ejecuta GPT3 en un clúster de GPU tan pequeño. Microsoft usó 10,000 V100 para pertenecer a GPT3. Ahora puedes ajustarlo o incluso preparar el tuyo propio en 32 GPU A100, ¡increíble!

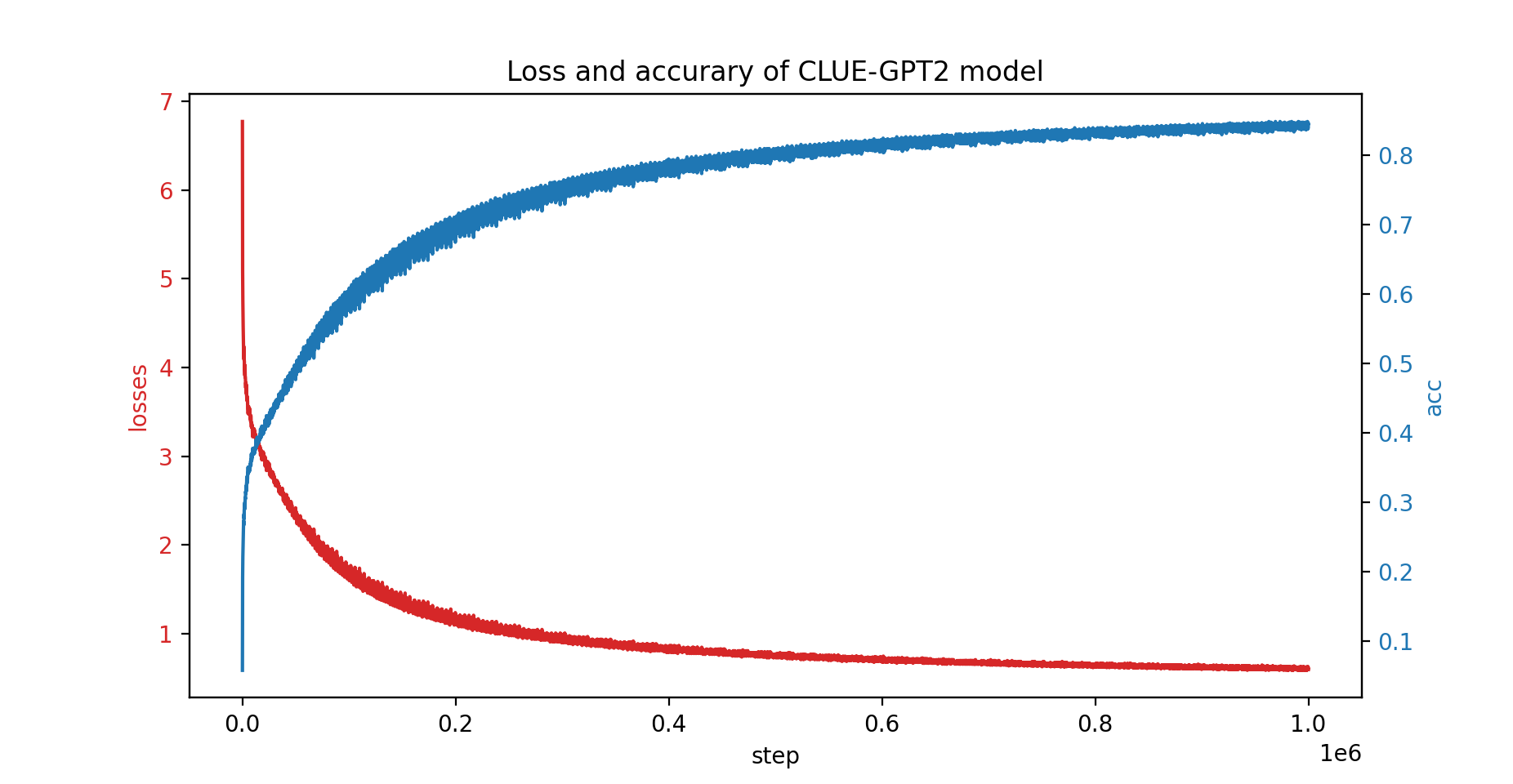
También entrenamos el modelo CLUE-GPT2 con PatrickStar; la curva de pérdida y precisión se muestra a continuación:
pip install .Tenga en cuenta que PatrickStar requiere gcc de la versión 7 o superior. También puede utilizar imágenes NVIDIA NGC; se prueba la siguiente imagen:
docker pull nvcr.io/nvidia/pytorch:21.06-py3PatrickStar se basa en PyTorch, lo que facilita la migración de un proyecto de pytorch. Aquí hay un ejemplo de PatrickStar:
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step () Usamos el mismo formato config que la configuración JSON de DeepSpeed, que incluye principalmente parámetros de optimizador, escalador de pérdidas y algunas configuraciones específicas de PatrickStar.
Para obtener una explicación detallada del ejemplo anterior, consulte la guía aquí.
Para obtener más ejemplos, consulte aquí.
Aquí encontrará un script de referencia de inicio rápido. Se ejecuta con datos generados aleatoriamente; por lo tanto, no es necesario preparar los datos reales. También demostró todas las técnicas de optimización de Patrickstar. Para obtener más trucos de optimización para ejecutar el punto de referencia, consulte Opciones de optimización.
Licencia BSD de 3 cláusulas
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{jiaruifang, zilinzhu, josephyu}@tencent.com
Desarrollado por el equipo de IA de WeChat y el equipo de PNL de Tencent.


