xcodec
1.0.0
Códec semántico y acústico unificado para el modelo de lenguaje de audio.
Título : El códec sí importa: exploración de las deficiencias semánticas del códec para el modelo de lenguaje de audio
Autores : Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo*, Wei Xue*
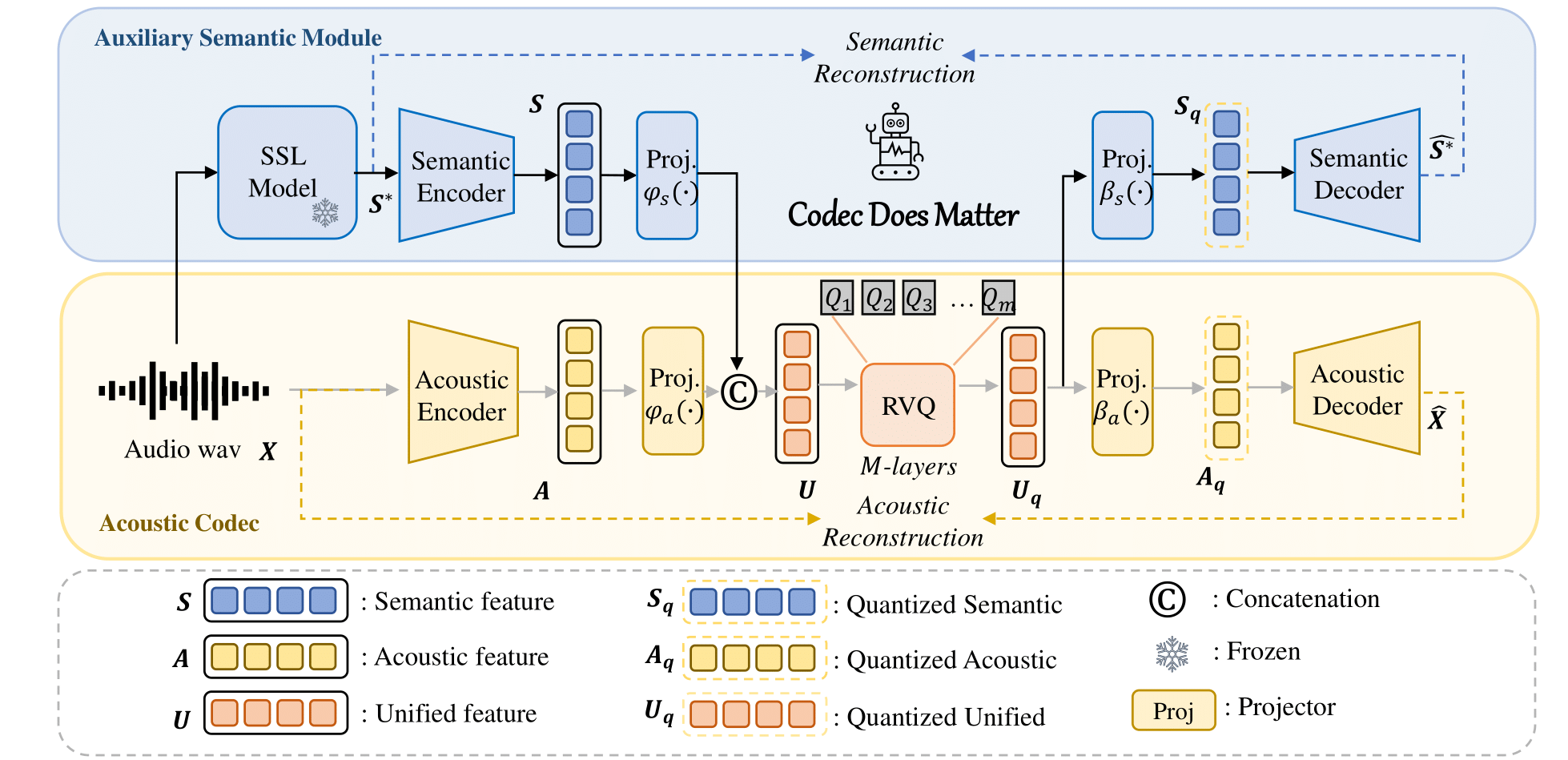
Puede aplicar fácilmente nuestro enfoque para mejorar cualquier códec acústico existente:
Por ejemplo
class Codec ():
def __init__ ( self ):
# Acoustic codec components
self . encoder = Encoder (...) # Acoustic encoder
self . decoder = Decoder (...) # Acoustic decoder
self . quantizer = RVQ (...) # Residual Vector Quantizer (RVQ)
# Adding the semantic module
self . semantic_model = AutoModel . from_pretrained (...) # e.g., Hubert, WavLM
# Adding Projector
self . fc_prior = nn . Linear (...)
self . fc_post1 = nn . Linear (...)
self . fc_post2 = nn . Linear (...)
def forward ( self , x , bw ):
# Encode the input acoustically and semantically
e_acoustic = self . encoder ( x )
e_semantic = self . semantic_model ( x )
# Combine acoustic and semantic features
combined_features = torch . cat ([ e_acoustic , e_semantic ])
# Apply prior transformation
transformed_features = self . fc_prior ( combined_features )
# Quantize the unified semantic and acoustic features
quantized , codes , bandwidth , commit_loss = self . quantizer ( transformed_features , bw )
# Post-process the quantized features
quantized_semantic = self . fc_post1 ( quantized )
quantized_acoustic = self . fc_post2 ( quantized )
# Decode the quantized acoustic features
output = self . decoder ( quantized_acoustic )
def semantic_loss ( self , semantic , quantized_semantic ):
return F . mse_loss ( semantic , quantized_semantic ) Para obtener más detalles, consulte nuestro código.
? enlaces al centro de modelos de Huggingface.
| Nombre del modelo | abrazando la cara | configuración | Modelo semántico | Dominio | Datos de entrenamiento |
|---|---|---|---|---|---|
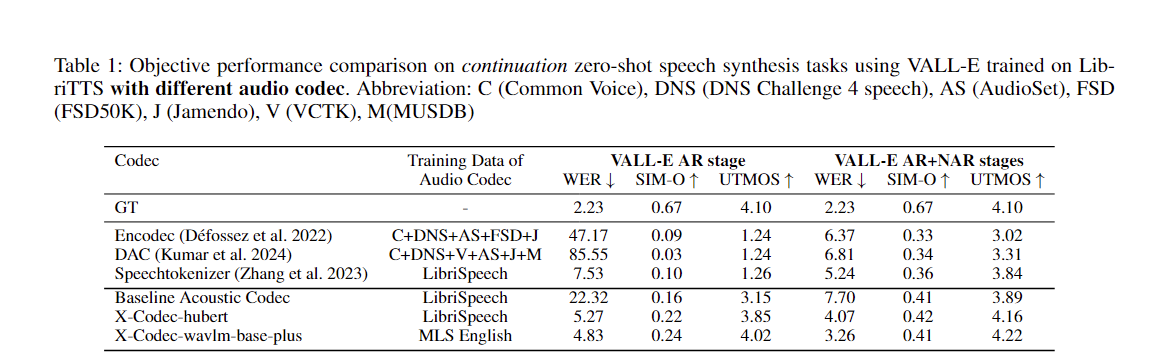
| xcodec_hubert_librispeech | ? | ? | ? base Hubert | Discurso | Librispeech |
| xcodec_wavlm_mls (no mencionado en el artículo) | ? | ? | ? Wavlm-base-plus | Discurso | MLS Inglés |
| xcodec_wavlm_more_data (no mencionado en el documento) | ? | ? | ? Wavlm-base-plus | Discurso | MLS Inglés + Datos internos |
| xcodec_hubert_general_audio | ? | ? | ?Hubert-base-audio-general | Audio general | 200.000 horas de datos internos |
| xcodec_hubert_general_audio_more_data (no mencionado en el documento) | ? | ? | ?Hubert-base-audio-general | Audio general | Datos más equilibrados |
Para ejecutar la inferencia, primero descargue el modelo y la configuración de Hugging Face.
python inference.pyPrepare el archivo_entrenamiento y el archivo_validación en config. El archivo debe enumerar las rutas a sus archivos de audio:
/path/to/your/xxx.wav
/path/to/your/yyy.wav
...Entonces:
torchrun --nnodes=1 --nproc-per-node=8 main_launch_vqdp.pyMe gustaría extender un agradecimiento especial a los autores de Uniaudio y DAC, ya que nuestro código base está tomado principalmente de Uniaudio y DAC.
Si encuentra útil este repositorio, considere citarlo en el siguiente formato:
@article { ye2024codecdoesmatterexploring ,
title = { Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model } ,
author = { Zhen Ye and Peiwen Sun and Jiahe Lei and Hongzhan Lin and Xu Tan and Zheqi Dai and Qiuqiang Kong and Jianyi Chen and Jiahao Pan and Qifeng Liu and Yike Guo and Wei Xue } ,
journal = { arXiv preprint arXiv:2408.17175 } ,
year = { 2024 } ,
}

