EasyEdit
1.0.0

Un marco de edición de conocimientos fácil de usar para modelos de lenguaje grandes.
Instalación • Inicio rápido • Documento • Documento • Demostración • Comparativa • Colaboradores • Diapositivas • Vídeo • Destacado por AK
2024-10-23, EasyEdit integra métodos de decodificación restringidos desde la edición dirigida para mitigar las alucinaciones en LLM y MLLM, con información detallada disponible en DoLa y DeCo.
2024-09-26, ?? Nuestro artículo "WISE: Repensar la memoria del conocimiento para la edición permanente de modelos de lenguaje grandes" ha sido aceptado por NeurIPS 2024 .
2024-09-20, ?? Nuestros artículos: "Mecanismos de conocimiento en modelos de lenguaje grandes: una encuesta y perspectiva" y "Edición de conocimiento conceptual para modelos de lenguaje grandes" han sido aceptados por EMNLP 2024 Findings .
2024-07-29, EasyEdit ha agregado un nuevo algoritmo de edición de modelos EMMET, que generaliza ROME a la configuración por lotes. Básicamente, esto permite realizar ediciones por lotes utilizando la función de pérdida de ROME.
El 23 de julio de 2024, publicamos un nuevo artículo: "Mecanismos de conocimiento en modelos lingüísticos grandes: una encuesta y una perspectiva", que revisa cómo se adquiere, utiliza y evoluciona el conocimiento en modelos lingüísticos grandes. Esta encuesta puede proporcionar los mecanismos fundamentales para manipular (editar) el conocimiento de manera precisa y eficiente en los LLM.
2024-06-04, ?? EasyEdit Paper ha sido aceptado por la vía de demostración del sistema ACL 2024 .
El 3 de junio de 2024, publicamos un artículo titulado "WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models" , además de presentar una nueva tarea de edición: la edición continua de conocimientos y el correspondiente método de edición permanente llamado WISE.
El 24 de abril de 2024, EasyEdit anunció la compatibilidad con el método ROME para Llama3-8B . Se recomienda a los usuarios que actualicen su paquete de transformadores a la versión 4.40.0.
2024-03-29, EasyEdit introdujo soporte de reversión para GRACE . Para obtener una introducción detallada, consulte la documentación de EasyEdit. Las actualizaciones futuras incluirán gradualmente soporte de reversión para otros métodos.
El 22 de marzo de 2024, se publicó un nuevo artículo titulado "Desintoxicación de modelos de lenguaje grandes mediante la edición de conocimientos" , junto con un nuevo conjunto de datos llamado SafeEdit y un nuevo método de desintoxicación llamado DINM.
El 12 de marzo de 2024, se publicó otro artículo titulado "Edición de conocimiento conceptual para modelos de lenguaje grandes" , que presenta un nuevo conjunto de datos denominado ConceptEdit.
2024-03-01, EasyEdit agregó soporte para un nuevo método llamado FT-M . Este método implica entrenar una capa MLP específica utilizando la pérdida de entropía cruzada en la respuesta objetivo y enmascarando el texto original . Supera la implementación de FT-L en ROMA. Se agradece el consejo del autor del número 173.
El 27 de febrero de 2024, EasyEdit agregó soporte para un nuevo método llamado InstructEdit, con detalles técnicos proporcionados en el documento "InstructEdit: Edición de conocimientos basada en instrucciones para modelos de lenguaje grandes" .
Accelerate .Un estudio exhaustivo de la edición de conocimientos para modelos de lenguaje grandes [artículo] [punto de referencia] [código]
Tutorial IJCAI 2024 Google Drive
COLING 2024 Tutorial Google Drive
Tutorial AAAI 2024 Google Drive
Tutorial de AACL 2023 [Google Drive] [Baidu Pan]
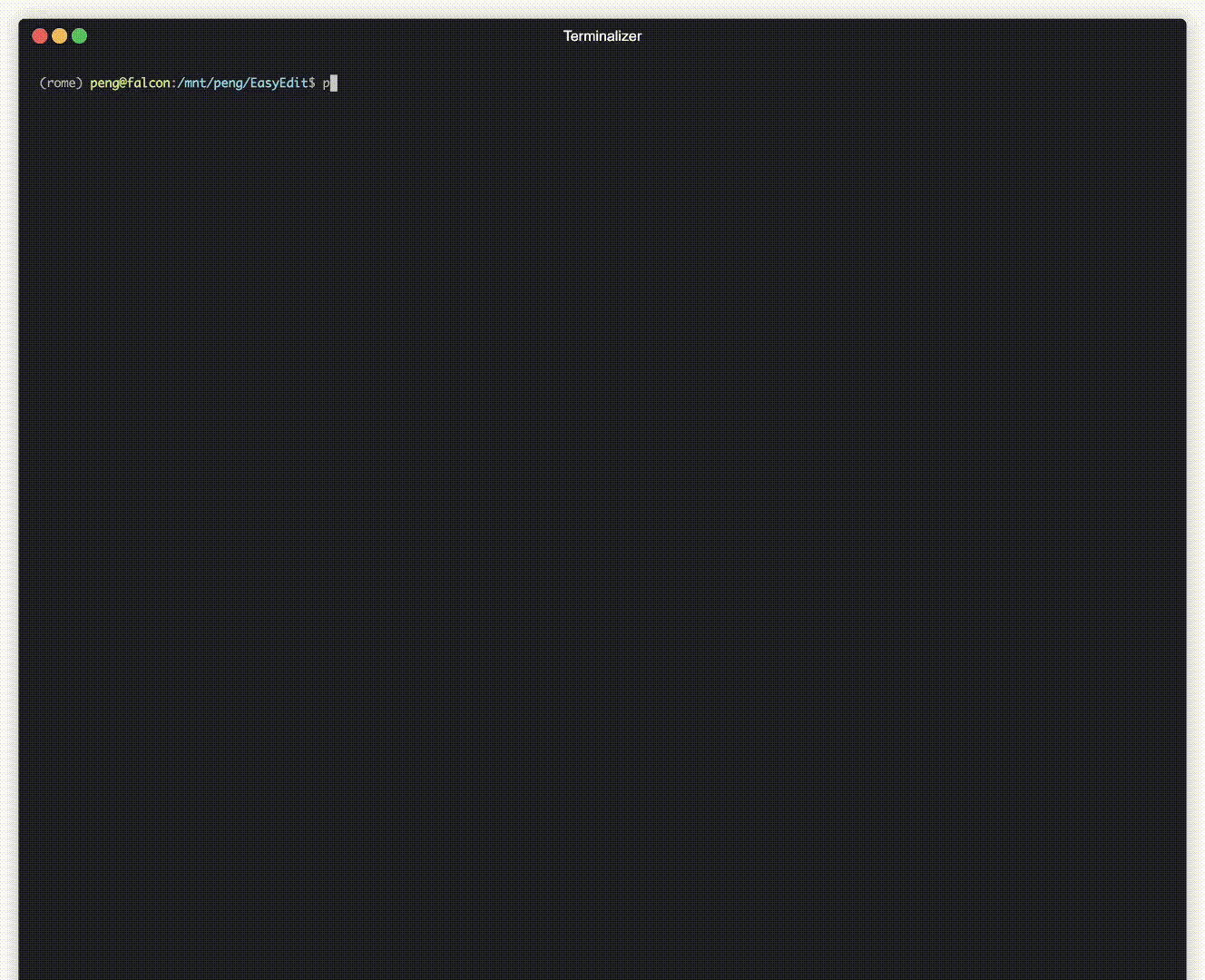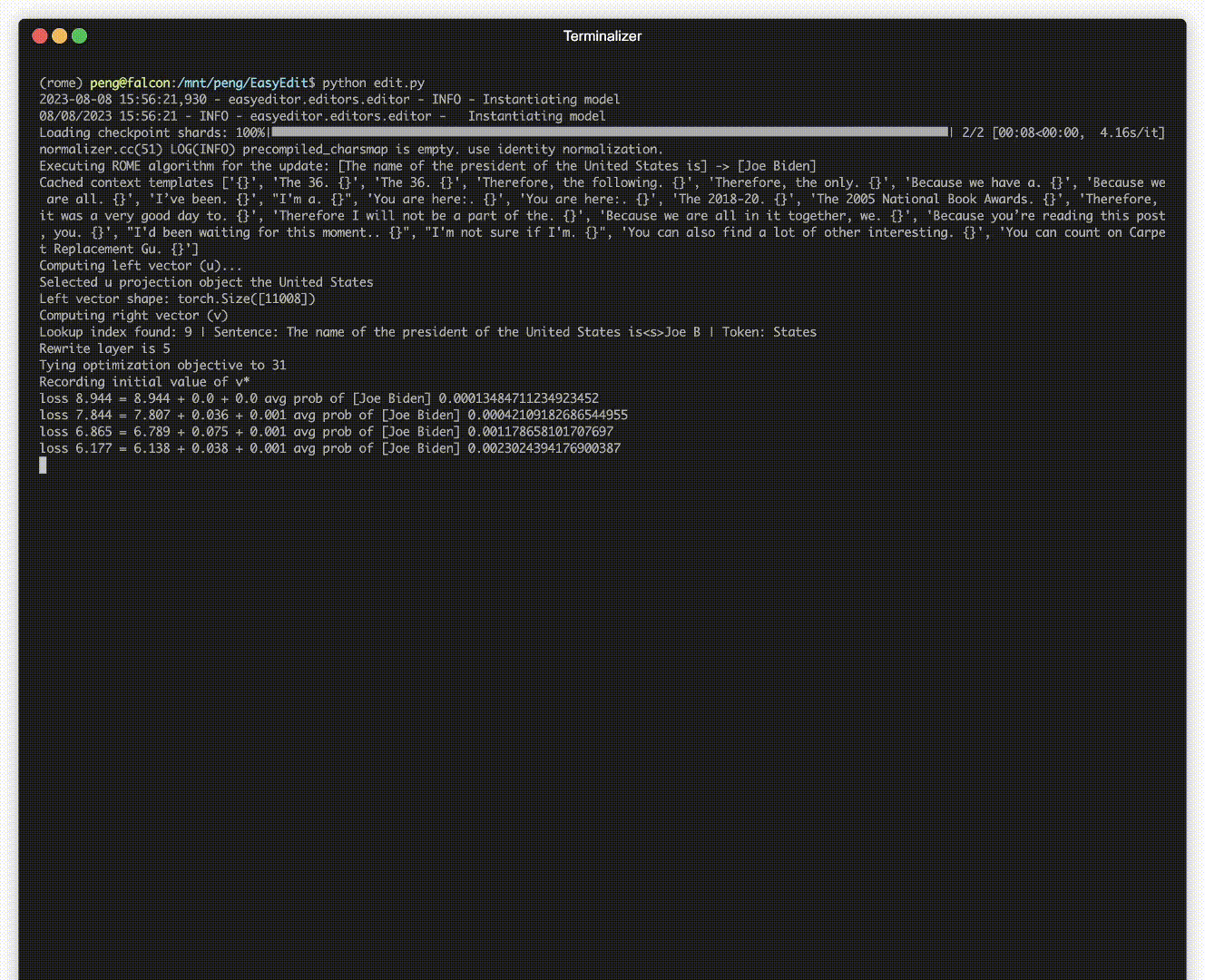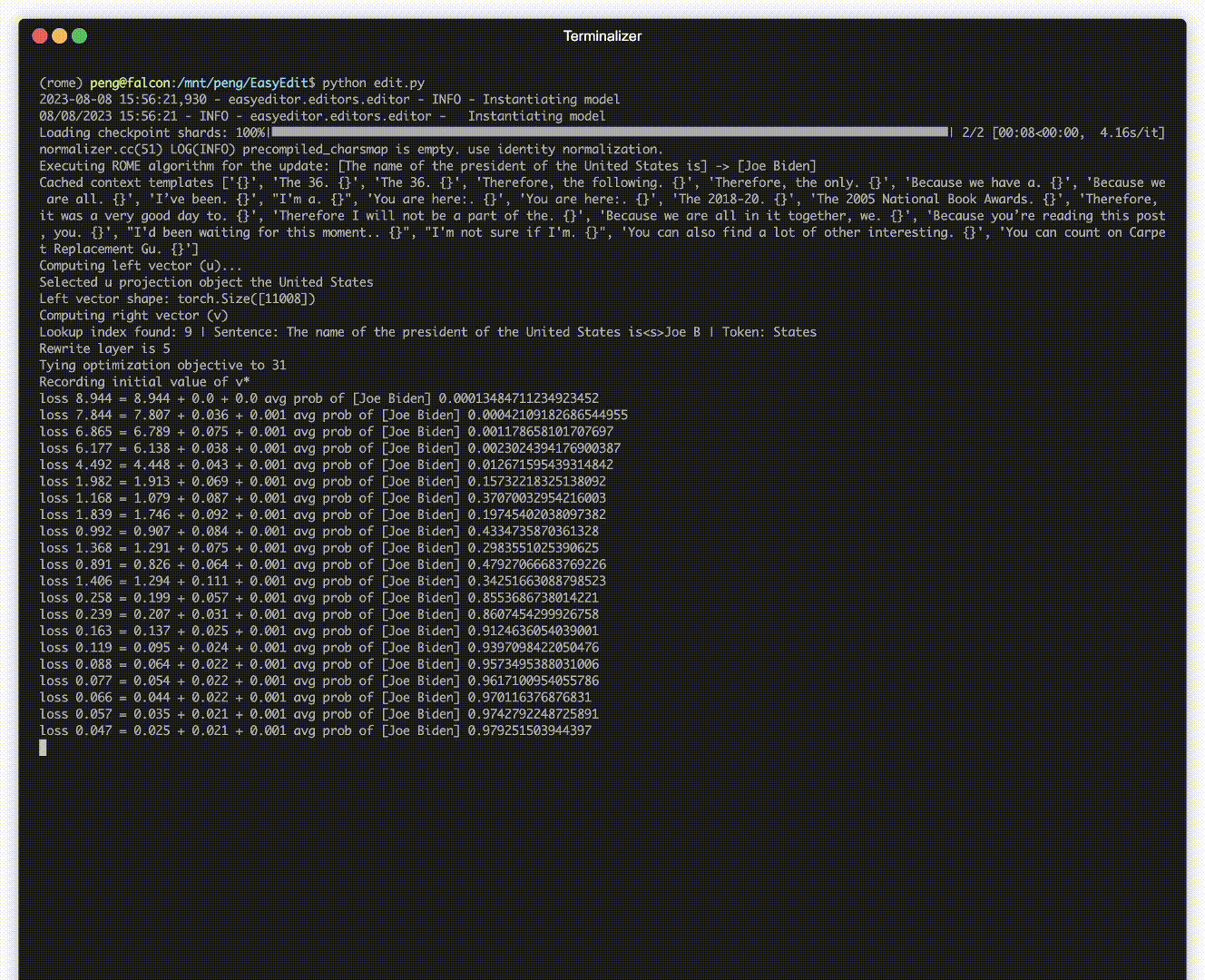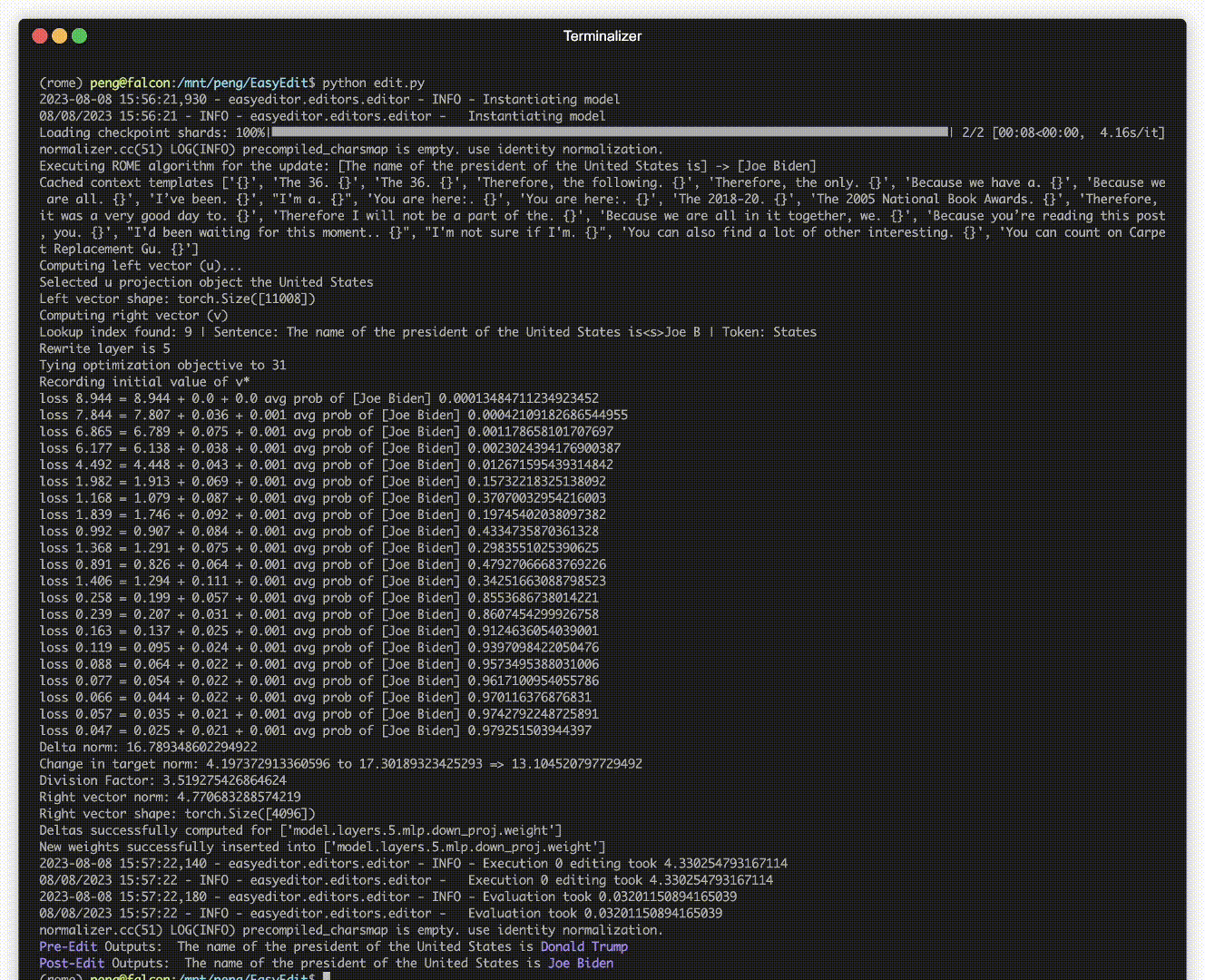
Hay una demostración de edición. El archivo GIF es creado por Terminalizer.
¡Ofrecemos un práctico Jupyter Notebook! Le permite editar el conocimiento de un LLM sobre el presidente de los EE. UU., pasando de Biden a Trump e incluso de regreso a Biden. Esto incluye métodos como WISE, AlphaEdit, AdaLoRA y edición basada en mensajes.
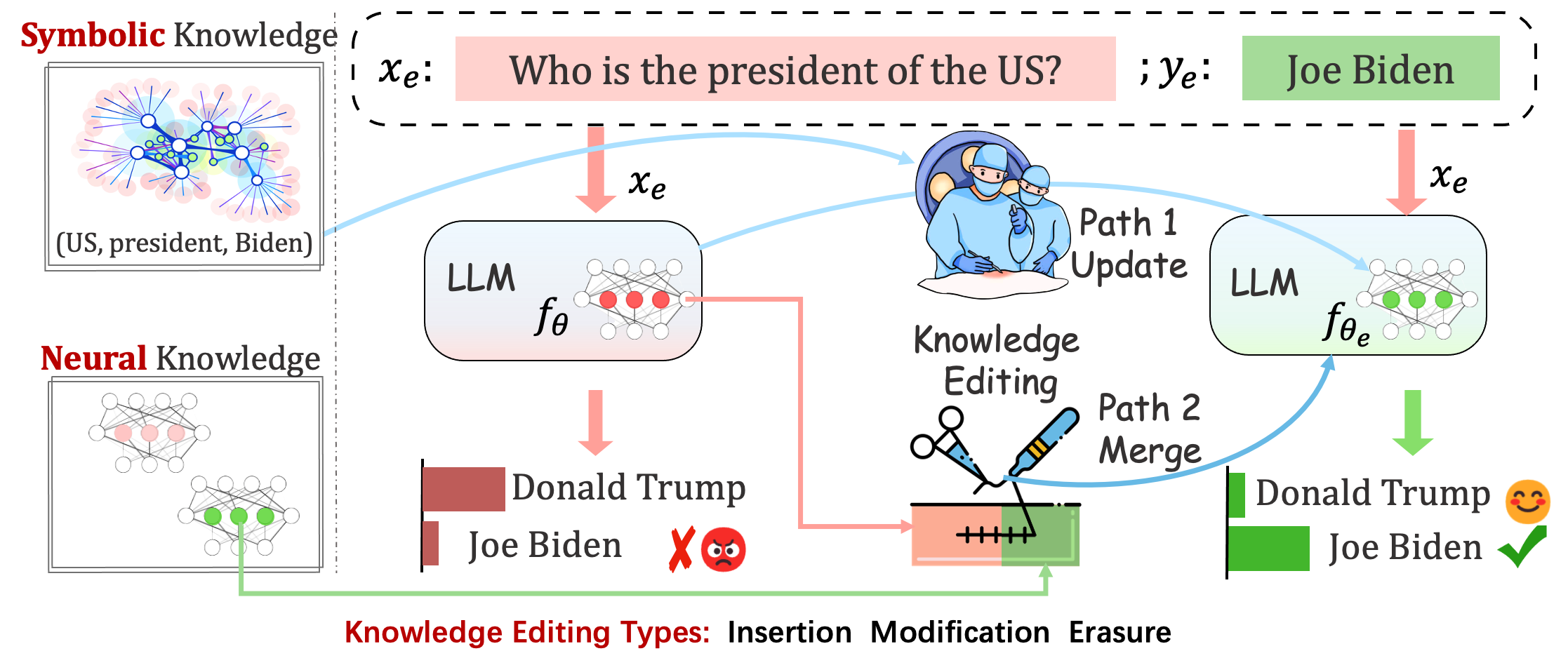
Los modelos implementados aún pueden cometer errores impredecibles. Por ejemplo, los LLM alucinan notoriamente, perpetúan el sesgo y decaen en los hechos , por lo que deberíamos poder ajustar comportamientos específicos de los modelos previamente entrenados.
La edición de conocimientos tiene como objetivo ajustar los modelos base.
Evaluar el rendimiento del modelo después de una única edición. El modelo recarga los pesos originales (por ejemplo, LoRA descarta los pesos del adaptador) después de una única edición. Deberías establecer sequential_edit=False
Esto requiere edición secuencial y la evaluación se realiza después de que se hayan aplicado todas las actualizaciones de conocimientos:
Realiza ajustes de parámetros para sequential_edit=True : README (para más detalles).
Sin influir en el comportamiento del modelo en muestras no relacionadas, el objetivo final es crear un modelo editado.
Tarea de edición para subtítulos de imágenes y respuesta visual a preguntas . LÉAME
La tarea propuesta toma el intento preliminar de editar las personalidades de los LLM editando sus opiniones sobre temas específicos, dado que las opiniones de un individuo pueden reflejar aspectos de sus rasgos de personalidad. Nos basamos en la teoría establecida de los CINCO GRANDES como base para construir nuestro conjunto de datos y evaluar las expresiones de personalidad de los LLM. LÉAME
Evaluación
Basado en logits
Basado en generación
Mientras que para evaluar Acc y TPEI , puede descargar el clasificador capacitado desde aquí.
El proceso de edición de conocimientos generalmente afecta las predicciones de un amplio conjunto de entradas que están estrechamente asociadas con el ejemplo de edición, llamado alcance de edición .
Una edición exitosa debería ajustar el comportamiento del modelo dentro del alcance de la edición sin dejar de tener entradas no relacionadas:
Reliability : la tasa de éxito de la edición con un descriptor de edición determinado.Generalization : la tasa de éxito de la edición dentro del alcance de la edición.Locality : si la salida del modelo cambia después de editar entradas no relacionadasPortability : la tasa de éxito de la edición para razonamiento/aplicación (un salto, sinónimo, generalización lógica)Efficiency : consumo de tiempo y memoria. EasyEdit es un paquete de Python para editar modelos de lenguajes grandes (LLM) como GPT-J , Llama , GPT-NEO , GPT2 , T5 (modelos de soporte de 1B a 65B ), cuyo objetivo es alterar el comportamiento de los LLM de manera eficiente dentro de un dominio específico sin afectar negativamente el rendimiento de otras entradas. Está diseñado para ser fácil de usar y fácil de ampliar.
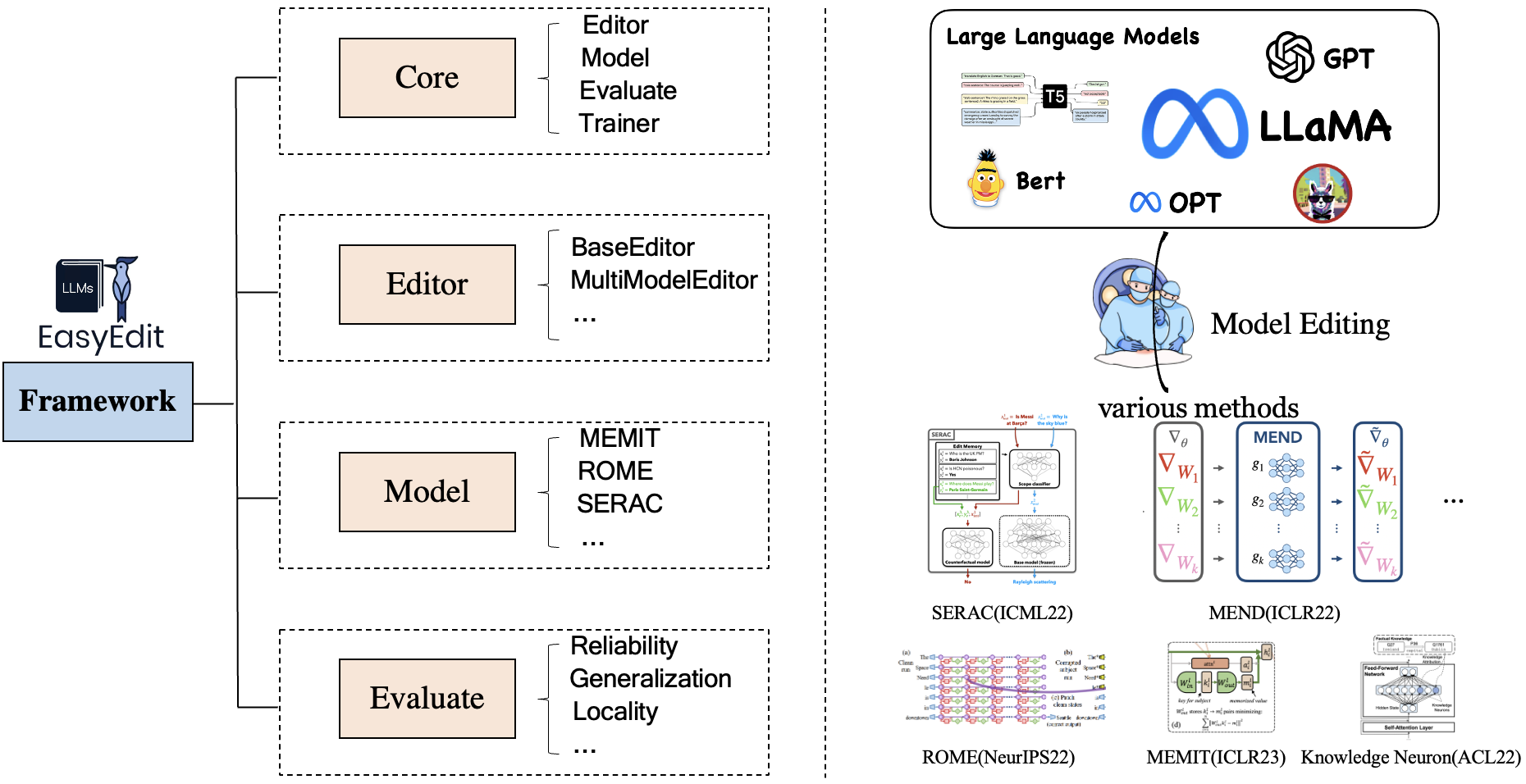
EasyEdit contiene un marco unificado para Editor , Método y Evaluación , que representan respectivamente el escenario de edición, la técnica de edición y el método de evaluación.
Cada escenario de edición de conocimiento consta de tres componentes:
Editor : como BaseEditor (editor de generación y conocimiento factual ) para LM, MultiModalEditor ( conocimiento multimodal ).Method : la técnica de edición de conocimientos específica utilizada (como ROME , MEND , ...).Evaluate : métricas para evaluar el rendimiento de la edición de conocimientos.Reliability , Generalization , Locality , PortabilityLas técnicas de edición de conocimientos admitidas actualmente son las siguientes:
Nota 1: Debido a la compatibilidad limitada de este kit de herramientas, algunos métodos de edición de conocimientos, incluidos T-Patcher, KE y CaliNet, no son compatibles.
Nota 2: De manera similar, el método MALMEN solo se admite parcialmente por las mismas razones y se seguirá mejorando.
Puede elegir diferentes métodos de edición según sus necesidades específicas.
| Método | T5 | GPT-2 | GPT-J | GPT-NEO | Llama | Baichuan | ChatGLM | PasanteLM | Qwen | Mistral |
|---|---|---|---|---|---|---|---|---|---|---|
| PIE | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| adalora | ✅ | ✅ | ||||||||
| SERAC | ✅ | ✅ | ✅ | ✅ | ||||||
| IKE | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| REMIENDO | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| kn | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| ROMA | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| r-ROMA | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| MEMITAR | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| HORMIGA | ✅ | ✅ | ✅ | |||||||
| GRACIA | ✅ | ✅ | ✅ | |||||||
| MELO | ✅ | |||||||||
| PMET | ✅ | ✅ | ||||||||
| Instruir | ✅ | ✅ | ||||||||
| DINM | ✅ | ✅ | ✅ | |||||||
| INTELIGENTE | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| Alfa | ✅ | ✅ | ✅ |
❗️❗️ Si tiene intención de utilizar Mistral, actualice la biblioteca
transformersa la versión 4.34.0 manualmente. Puede utilizar el siguiente código:pip install transformers==4.34.0.
| Trabajar | Descripción | Camino |
|---|---|---|
| Instruir | InstructEdit: edición de conocimientos basada en instrucciones para modelos de lenguaje grandes | Inicio rápido |
| DINM | Desintoxicación de modelos de lenguaje grandes mediante la edición de conocimientos | Inicio rápido |
| INTELIGENTE | WISE: Repensar la memoria del conocimiento para la edición permanente de modelos de lenguaje grandes | Inicio rápido |
| Concepto | Edición de conocimientos conceptuales para modelos de lenguaje grandes | Inicio rápido |
| MM | ¿Podemos editar modelos de lenguajes grandes multimodales? | Inicio rápido |
| Personalidad | Edición de personalidad para modelos de lenguaje grandes | Inicio rápido |
| INMEDIATO | Métodos de edición de conocimientos basados en PROMPT | Inicio rápido |
Punto de referencia: KnowEdit [Cara abrazada][WiseModel][ModelScope]
❗️❗️ Cabe señalar que KnowEdit se construye reorganizando y ampliando los conjuntos de datos existentes, incluidos WikiBio , ZsRE , WikiData Counterfact , WikiData Recent , convsent y Sanitation , para realizar una evaluación integral para la edición de conocimientos. Un agradecimiento especial a los creadores y mantenedores de esos conjuntos de datos.
Tenga en cuenta que Counterfact y WikiData Counterfact no son el mismo conjunto de datos.
| Tarea | Inserción de Conocimiento | Modificación del conocimiento | Borrado de conocimientos | |||
|---|---|---|---|---|---|---|
| Conjuntos de datos | Wiki reciente | ZsRE | WikiBio | Contrafacto de WikiData | Consentimiento | Saneamiento |
| Tipo | Hecho | Respuesta a preguntas | Alucinación | Contrafacto | Sentimiento | Información no deseada |
| # Tren | 570 | 10.000 | 592 | 1.455 | 14.390 | 80 |
| # Prueba | 1.266 | 1301 | 1.392 | 885 | 800 | 80 |
Proporcionamos secuencias de comandos detalladas para que el usuario utilice KnowEdit fácilmente; consulte los ejemplos.
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| conjunto de datos | AbrazosCara | Modelo sabio | ModeloScope | Descripción |
|---|---|---|---|---|
| CKnow | [Cara abrazada] | [Modelo sabio] | [Modelo alcance] | conjunto de datos para editar el conocimiento chino |
CKnowEdit es un conjunto de datos en chino de alta calidad para la edición de conocimientos que se caracteriza en gran medida por el idioma chino, y todos los datos provienen de bases de conocimientos chinas. Está meticulosamente diseñado para discernir más profundamente los matices y desafíos inherentes a la comprensión del idioma chino por parte de los LLM actuales, proporcionando un recurso sólido para perfeccionar el conocimiento específico del chino dentro de los LLM.
Las descripciones de los campos para los datos en CKnowEdit son las siguientes:
"prompt" : query inputed to the model ( str )
"target_old" : the incorrect response previously generated by the model ( str )
"target_new" : the accurate answer of the prompt ( str )
"portability_prompt" : new prompts related to the target knowledge ( list or None )
"portability_answer" : accurate answers corresponding to the portability_prompt ( list or None )
"locality_prompt" : new prompts unrelated to the target knowledge ( list or None )
"locality_answer" : accurate answers corresponding to the locality_prompt ( list or None )
"rephrase" : alternative ways to phrase the original prompt ( list ) CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| conjunto de datos | Google Drive | BaiduNetDisk | Descripción |
|---|---|---|---|
| ZsRE más | [GoogleDrive] | [BaiduNetDisk] | Conjunto de datos de respuesta a preguntas mediante reformulación de preguntas |
| Contrafacto más | [GoogleDrive] | [BaiduNetDisk] | Conjunto de datos de contrafacto mediante reemplazo de entidad |
Proporcionamos conjuntos de datos zsre y Counterfact para verificar la efectividad de la edición de conocimientos. Puedes descargarlos aquí. [Google Drive], [BaiduNetDisk].
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouse| conjunto de datos | Google Drive | Conjunto de datos de HuggingFace | Descripción |
|---|---|---|---|
| Concepto | [GoogleDrive] | [Conjunto de datos de HuggingFace] | conjunto de datos para editar conocimientos conceptuales |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
Métricas de evaluación específicas del concepto
Instance Change : capturar las complejidades de estos cambios a nivel de instanciaConcept Consistency : la similitud semántica de la definición del concepto generado. | conjunto de datos | Google Drive | BaiduNetDisk | Descripción |
|---|---|---|---|
| E-IC | [GoogleDrive] | [BaiduNetDisk] | conjunto de datos para editar subtítulos de imágenes |
| E-VQA | [GoogleDrive] | [BaiduNetDisk] | conjunto de datos para editar Visual Question Answering |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| conjunto de datos | Conjunto de datos de HuggingFace | Descripción |
|---|---|---|
| Seguro | [Conjunto de datos de HuggingFace] | conjunto de datos para desintoxicar los LLM |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
Métricas de evaluación específicas desintoxicantes
Defense Duccess (DS) : la tasa de éxito de la desintoxicación del LLM editado para la entrada del adversario (mensaje de ataque + pregunta dañina), que se utiliza para modificar el LLM.Defense Generalization (DG) : la tasa de éxito de la desintoxicación del LLM editado para entradas maliciosas fuera del dominio.General Performance : los efectos secundarios del desempeño de tareas no relacionadas. | Método | Descripción | GPT-2 | Llama |
|---|---|---|---|
| IKE | Aprendizaje en contexto (ICL) Editar | [Colab-gpt2] | [Colab-llama] |
| ROMA | Localizar y luego editar neuronas | [Colab-gpt2] | [Colab-llama] |
| MEMITAR | Localizar y luego editar neuronas | [Colab-gpt2] | [Colab-llama] |
Nota: utilice Python 3.9+ para EasyEdit. Para comenzar, simplemente instale conda y ejecute:
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txtTodos nuestros resultados se basan en la configuración predeterminada.
| llama-2-7B | chatglm2 | gpt-j-6b | gpt-xl | |
|---|---|---|---|---|
| PIE | 60GB | 58GB | 55GB | 7GB |
| SERAC | 42GB | 32GB | 31GB | 10GB |
| IKE | 52GB | 38GB | 38GB | 10GB |
| REMIENDO | 46GB | 37GB | 37GB | 13GB |
| kn | 42GB | 39GB | 40GB | 12GB |
| ROMA | 31GB | 29GB | 27GB | 10GB |
| MEMITAR | 33GB | 31GB | 31GB | 11GB |
| adalora | 29GB | 24GB | 25GB | 8GB |
| GRACIA | 27GB | 23GB | 6GB | |
| INTELIGENTE | 34GB | 27GB | 7GB |
Edite modelos de lenguaje grandes (LLM) en aproximadamente 5 segundos
El siguiente ejemplo le muestra cómo realizar la edición con EasyEdit. Se pueden encontrar más ejemplos y tutoriales en ejemplos.
BaseEditores la clase para la edición de conocimientos de modalidad lingüística. Puede elegir el método de edición adecuado según sus necesidades específicas.
Con la modularidad y flexibilidad de EasyEdit , puedes usarlo fácilmente para editar modelos.
Paso 1: Defina un PLM como el objeto a editar. Elija el PLM que desea editar. EasyEdit admite modelos parciales ( T5 , GPTJ , GPT-NEO , LlaMA hasta ahora) recuperables en HuggingFace. El directorio del archivo de configuración correspondiente es hparams/YUOR_METHOD/YOUR_MODEL.YAML , como hparams/MEND/gpt2-xl.yaml , establezca el model_name correspondiente para seleccionar el objeto para la edición de conocimientos.
model_name : gpt2-xl
model_class : GPT2LMHeadModel
tokenizer_class : GPT2Tokenizer
tokenizer_name : gpt2-xl
model_parallel : false # true for multi-GPU editingPaso 2: elija el método de edición de conocimientos adecuado
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams . from_hparams ( './hparams/MEND/gpt2-xl' )Paso 3: proporcione el descriptor de edición y el destino de edición
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?' ,
'Which family does Ramalinaceae belong to' ,
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = [ 'Illinois Institute of Technology' , 'Lecanorales' , 'defender' ]
## edit target: expected output
target_new = [ 'University of Michigan' , 'Lamiinae' , 'winger' ] Paso 4: combínelos en un BaseEditor EasyEdit proporciona una forma simple y unificada de iniciar Editor , como huggingface: from_hparams .
## Construct Language Model Editor
editor = BaseEditor . from_hparams ( hparams )Paso 5: Proporcione los datos para la evaluación. Tenga en cuenta que los datos de portabilidad y localidad son opcionales (establecidos en Ninguno solo para la evaluación básica de la tasa de éxito de la edición). El formato de datos para ambos es un dictado ; para cada dimensión de medición, debe proporcionar el mensaje correspondiente y su verdad fundamental correspondiente. A continuación se muestra un ejemplo de los datos:
locality_inputs = {
'neighborhood' :{
'prompt' : [ 'Joseph Fischhof, the' , 'Larry Bird is a professional' , 'In Forssa, they understand' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
},
'distracting' : {
'prompt' : [ 'Ray Charles, the violin Hauschka plays the instrument' , 'Grant Hill is a professional soccer Magic Johnson is a professional' , 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
}
}En el ejemplo anterior, evaluamos el rendimiento de los métodos de edición sobre "vecindario" y "distracción".
Paso 6: Edición y evaluación ¡Listo! Podemos realizar edición y evaluación para que su modelo sea editado. La función edit devolverá una serie de métricas relacionadas con el proceso de edición, así como los pesos del modelo modificado. [ sequential_edit=True para edición continua]
metrics , edited_model , _ = editor . edit (
prompts = prompts ,
ground_truth = ground_truth ,
target_new = target_new ,
locality_inputs = locality_inputs ,
sequential_edit = False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelLa longitud máxima de entrada para EasyEdit es 512. Si se excede esta longitud, aparecerá el error "Error CUDA: se activó la afirmación del lado del dispositivo". Puedes modificar la longitud máxima en el siguiente archivo:LINK
Paso 7: Revertir En la edición secuencial, si no está satisfecho con el resultado de una de sus ediciones y no desea perder sus ediciones anteriores, puede usar la función de revertir para deshacer su edición anterior. Actualmente, solo admitimos el método GRACE. Todo lo que necesitas hacer es una sola línea de código, usando edit_key para revertir tu edición.
editor.rolllback('edit_key')
En EasyEdit, utilizamos de forma predeterminada target_new como edit_key
Especificamos las métricas de retorno en formato dict , incluidas las evaluaciones de predicción del modelo antes y después de la edición. Para cada edición, incluirá las siguientes métricas:
rewrite_acc rephrase_acc locality portablility 

