mengzi retrieval lm
1.0.0
En Langboat Technology, nos centramos en mejorar los modelos previamente entrenados para hacerlos más ligeros y satisfacer las necesidades reales de la industria. Un enfoque basado en la recuperación (como RETRO, REALM y RAG) es crucial para lograr este objetivo.
Este repositorio es una implementación experimental del modelo de lenguaje de recuperación mejorada. Actualmente, solo admite la adaptación de recuperación en GPT-Neo.
Bifurcamos Huggingface Transformers y lm-evaluación-arnés para agregar soporte de recuperación. La parte de indexación se implementa como un servidor HTTP para desacoplar mejor la recuperación y el entrenamiento.
La mayor parte de la implementación del modelo se copia de RETRO-pytorch y GPT-Neo. Usamos transformers-cli para agregar un nuevo modelo llamado Re_gptForCausalLM basado en GPT-Neo y luego agregarle una parte de recuperación.
Cargamos el modelo instalado en EleutherAI/gpt-neo-125M usando la biblioteca de recuperación 200G.
Puede inicializar un modelo como este:
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )Y evalúe el modelo así:
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1Calculamos la similitud utilizando la incrustación de Sentencia_Transformers como representación de texto. Puede inicializar un modelo Sentence-BERT de esta manera:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )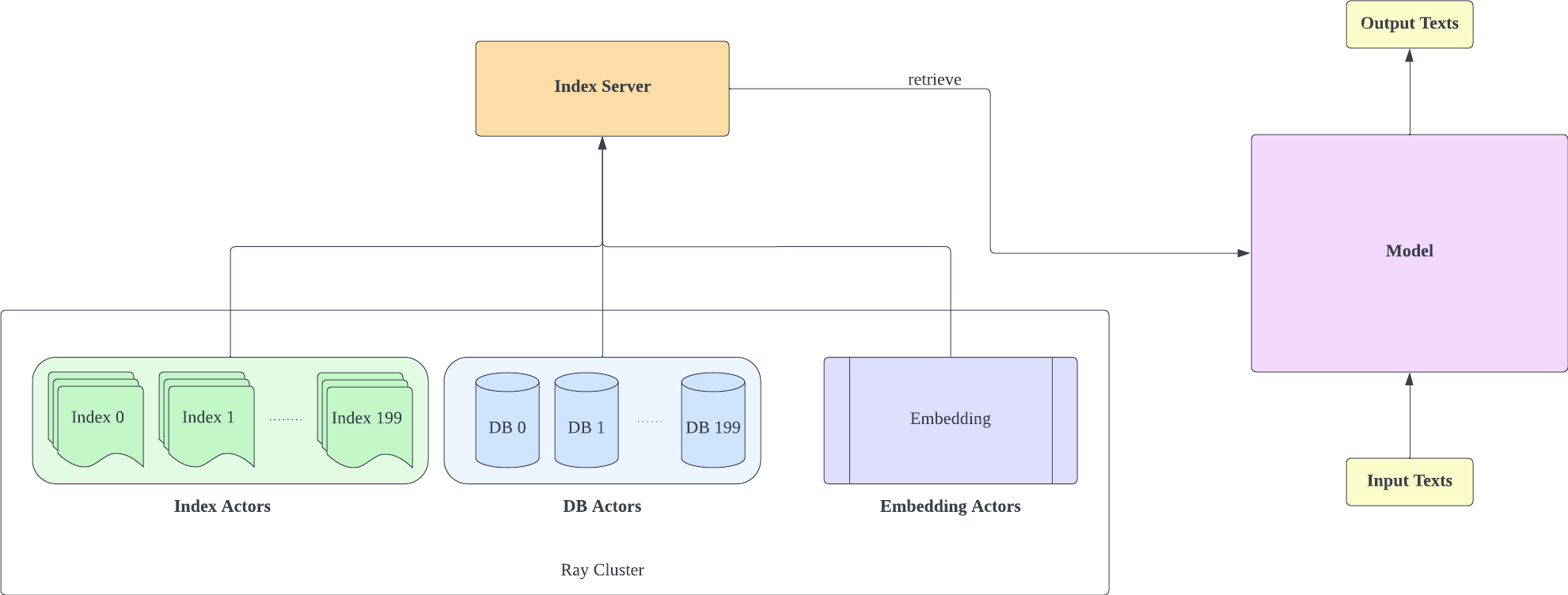
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " Usando IVF1024PQ48 como fábrica de índices faiss, cargamos el índice y la base de datos en el centro de modelos de huggingface, que se puede descargar usando el siguiente comando.
En download_index_db.py, puede especificar la cantidad de índices y bases de datos que desea descargar.
python -u download_index_db.py --num 200Puede descargar manualmente el modelo instalado desde aquí: https://huggingface.co/Langboat/ReGPT-125M-200G
El servidor de índice se basa en FastAPI y Ray. Con Ray's Actor, las tareas computacionalmente intensivas se encapsulan de forma asincrónica, lo que nos permite utilizar de manera eficiente los recursos de CPU y GPU con una sola instancia de servidor FastAPI. Puede inicializar un servidor de índices de esta manera:
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- Tenga en cuenta que el recuento de fragmentos de configuración IVF1024PQ48.json debe coincidir con el número de índices descargados. Puede ver el número de índice descargado actualmente en db_path
- Esta configuración se probó en el A100-40G, por lo que si tiene una GPU diferente, le recomendamos ajustarla a su hardware.
- Después de implementar el servidor de índice, debe modificar request_server en lm-evaluación-harness/config.json y train/config.json.
- Puede reducir encoder_actor_count en config_IVF1024PQ48.json para reducir los recursos de memoria necesarios.
· db_path: la ubicación de descarga de la base de datos desde huggingface. "../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966" es un ejemplo.
Este comando descargará la base de datos y los datos del índice de huggingface.
Cambie la carpeta de índice en el archivo de configuración (config IVF1024PQ48) para que apunte a la ruta de la carpeta de índice y envíe las instantáneas de la carpeta de la base de datos como la ruta de base de datos al script api.py.
Detenga el servidor de índice con el siguiente comando
ray stop
- Tenga en cuenta que debe mantener el servidor de índice habilitado durante el entrenamiento, la evaluación y la inferencia.
Utilice train/train.py para implementar la capacitación; train/config.json se puede modificar para cambiar los parámetros de entrenamiento.
Puede inicializar el entrenamiento de esta manera:
cd train
python -u train.py
- Dado que el servidor de índice necesita utilizar recursos de memoria, es mejor implementar el servidor de índice y el entrenamiento del modelo en diferentes GPU.
Utilice train/inference.py como inferencia para determinar la pérdida de un texto y su perplejidad.
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- Test_data.json y train_data.json en la carpeta de datos son formatos de archivo actualmente admitidos; puede modificar sus datos a este formato.
Utilice lm-evaluación-arnés como método de evaluación
Establecimos el seq_len del lm-evaluación-arnés en 1025 como configuración inicial para la comparación de modelos porque el seq_len de nuestro entrenamiento de modelos es 1025.
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path: la ruta del modelo adecuado
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1Los resultados de la evaluación son los siguientes.
| modelo | wikitexto palabra_perplejidad |
|---|---|
| EleutherAI/gpt-neo-125M | 35.8774 |
| Lancha/ReGPT-125M-200G | 22.115 |
| EleutherAI/gpt-neo-1.3B | 17.6979 |
| Lancha/ReGPT-125M-400G | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

