GraphGPT: aprendizaje de gráficos con transformadores generativos preentrenados
Este repositorio es la implementación oficial de "GraphGPT: aprendizaje de gráficos con transformadores generativos preentrenados" en PyTorch.
GraphGPT: aprendizaje de gráficos con transformadores generativos preentrenados
Qifang Zhao, Weidong Ren, Tianyu Li, Xiaoxiao Xu, Hong Liu
Actualizar:
13/10/2024
- v0.4.0 lanzado. Consulte
CHANGELOG.md para obtener más detalles. - Lograr SOTA en 3 conjuntos de datos ogb a gran escala:
- PCQM4M-v2 (sin 3D): 0,0802 (SOTA anterior 0,0821)
- ogbl-ppa: 68,76 (SOTA 65,24 anterior)
- ogbl-citation2: 91.15 (SOTA 90.72 anterior)
18/08/2024
- v0.3.1 lanzado. Consulte
CHANGELOG.md para obtener más detalles.
09/07/2024
- v0.3.0 lanzado.
19/03/2024
- v0.2.0 lanzado.
- Implemente
permute_nodes para conjuntos de datos de estilo mapa a nivel de gráfico, a fin de aumentar las variaciones de las rutas eulerianas y obtener resultados mejores y más sólidos. - Agregue
StackedGSTTokenizer para que los tokens semánticos (es decir, atributos de nodo/borde) se puedan apilar junto con los tokens estructurales, y la longitud de la secuencia se reduciría mucho. - códigos de refactorización.
23/01/2024
- v0.1.1, corrige errores del paquete common-io.
03/01/2024
- Liberación inicial de códigos.
Direcciones futuras
Ley de escala: ¿cuál es el límite de escala de los modelos GraphGPT?
- Como sabemos, GPT entrenado con datos de texto puede escalar a cientos de miles de millones de parámetros y seguir mejorando su capacidad.
- Los datos de texto pueden proporcionar billones de tokens, tienen una complejidad muy alta y poseen mucho conocimiento, incluido el conocimiento social y natural.
- Por el contrario, los datos de gráficos sin atributos de nodo/borde contienen solo información de estructura, que es bastante limitada en comparación con los datos de texto. La mayor parte de la información oculta (por ejemplo, grados, recuento de subestructuras, etc.) detrás de la estructura se puede calcular exactamente utilizando paquetes como networkx. Por lo tanto, es posible que la información de la estructura del gráfico no admita el escalamiento del tamaño del modelo hasta miles de millones de parámetros.
- Nuestros experimentos preliminares con varios conjuntos de datos de gráficos a gran escala muestran que podemos escalar GraphGPT hasta más de 400 millones de parámetros mejorando el rendimiento. Pero no podemos mejorar más los resultados. Podría deberse a nuestros experimentos insuficientes. Pero es posible que las limitaciones inherentes de los datos gráficos causaran esto.
- Los conjuntos de datos de gráficos grandes (ya sea un gráfico grande o grandes cantidades de gráficos pequeños) con atributos de nodo/borde podrían proporcionarnos suficiente información para entrenar un modelo GraphGPT grande. Aun así, un conjunto de datos de gráficos puede no ser suficiente y es posible que necesitemos recopilar varios conjuntos de datos de gráficos para entrenar un GraphGPT.
- El problema aquí es cómo definir un tokenizador universal para atributos de borde/nodo de varios conjuntos de datos de gráficos.
Datos gráficos de alta calidad: ¿Cuáles son los datos gráficos de alta calidad para entrenar un GraphGPT para tareas generales?
- Por ejemplo, si queremos entrenar un modelo para todo tipo de tareas de generación y comprensión de moléculas, ¿qué tipo de datos utilizaremos?
- Según nuestra investigación preliminar, agregamos ZINC (4.6M) y CEPDB (2.3M) al entrenamiento previo, no observamos ganancias al ajustar PCQM4M-v2 para la tarea de predicción de brecha homo-lumo. Las posibles razones podrían ser las siguientes:
- #estructura# Los patrones gráficos detrás del gráfico molecular son relativamente simples.
- Los patrones de gráficos como cadenas o anillos de 5/6 nodos son muy comunes.
- En promedio, 2 aristas por nodo, lo que significa que los átomos tienen 2 enlaces en promedio.
- #semántica# Las reglas químicas para construir moléculas orgánicas pequeñas son simples: el átomo de carbono tiene 4 enlaces, el átomo de nitrógeno tiene 3 enlaces, el átomo de oxígeno tiene 2 enlaces y el átomo de hidrógeno tiene 1 enlace, y así sucesivamente. En pocas palabras, siempre que tengamos satisfechos los recuentos de enlaces de los átomos, podremos generar cualquier molécula.
- Las reglas tanto de estructura como de semántica son tan simples que incluso un modelo mediano puede aprender del conjunto de datos de tamaño mediano. Por lo tanto, agregar datos adicionales no ayuda. Entrenamos previamente modelos pequeños/medianos/base/grandes utilizando datos de 3,7 millones de moléculas, y su pérdida es muy cercana, lo que indica ganancias limitadas al ampliar el tamaño del modelo en la etapa previa al entrenamiento.
- En segundo lugar, si queremos entrenar un modelo para cualquier tipo de tarea de comprensión de la estructura gráfica, ¿qué tipo de datos debemos utilizar?
- ¿Utilizaremos datos gráficos reales de redes sociales, redes de citas, etc., o simplemente utilizaremos datos gráficos sintéticos, como gráficos aleatorios de Erdos-Renyi?
- Nuestros experimentos preliminares muestran que el uso de gráficos aleatorios para entrenar previamente GraphGPT es útil para que el modelo comprenda las estructuras de los gráficos, pero es inestable. Sospechamos que está relacionado con las distribuciones de las estructuras gráficas en las etapas previas al entrenamiento y de ajuste fino. Por ejemplo, si tienen una cantidad similar de aristas por nodo, una cantidad similar de nodos, entonces el paradigma de preentrenamiento y ajuste fino funciona bien.
- #Universalidad# Entonces, ¿cómo entrenar un modelo GraphGPT para comprender cualquier estructura gráfica de manera universal?
- Esto se remonta a preguntas anteriores sobre la ley de escala: ¿cuáles son los datos gráficos adecuados y de alta calidad para seguir ampliando GraphGPT para que pueda realizar bien varias tareas gráficas?
Pocos disparos: ¿Puede GraphGPT obtener capacidad de pocos disparos?
- Si es posible, ¿cómo diseñar los datos de entrenamiento para permitir que GraphGPT los aprenda?
- En nuestros experimentos preliminares con el conjunto de datos PCQM4M-v2, se observan no pocas capacidades de aprendizaje de disparos. Pero eso no significa que no pueda hacerlo. Podría deberse a las siguientes razones:
- El modelo no es lo suficientemente grande. Usamos el modelo base con ~100M de parámetros.
- Los datos de entrenamiento no son suficientes. Solo utilizamos 3,7 millones de moléculas, lo que proporciona tokens limitados para el entrenamiento.
- El formato de los datos de entrenamiento no es adecuado para que el modelo obtenga capacidad de pocos disparos.
Descripción general:

Proponemos GraphGPT, un modelo novedoso para el aprendizaje de gráficos mediante transformadores eulerianos de gráficos generativos previos al entrenamiento (GET) autosupervisados. Primero presentamos GET, que consta de una columna vertebral codificadora/decodificadora de transformador básico y una transformación que convierte cada gráfico o subgrafo muestreado en una secuencia de tokens que representan el nodo, el borde y los atributos de forma reversible utilizando la ruta euleriana. Luego, entrenamos previamente el GET con la tarea de predicción del siguiente token (NTP) o la tarea programada de predicción de token enmascarado (SMTP). Por último, ajustamos el modelo con las tareas supervisadas. Este modelo intuitivo pero eficaz logra resultados superiores o cercanos a los métodos de última generación para las tareas a nivel de gráfico, borde y nodo en el conjunto de datos moleculares a gran escala PCQM4Mv2, el conjunto de datos de asociación proteína-proteína ogbl-ppa. , el conjunto de datos de la red de citas ogbl-citation2 y el conjunto de datos ogbn-proteins del Open Graph Benchmark (OGB). Además, el preentrenamiento generativo nos permite entrenar GraphGPT hasta 2B+ parámetros con un rendimiento en constante aumento, lo que está más allá de la capacidad de los GNN y los transformadores de gráficos anteriores.
Graficar a Secuencias
Después de convertir gráficos Eulerizados en secuencias, existen varias formas diferentes de adjuntar atributos de nodos y bordes a las secuencias. A estos métodos los denominamos short , long y prolonged .
Dada la gráfica, primero la Eulerizamos y luego la convertimos en una secuencia equivalente. Y luego, volvemos a indexar los nodos cíclicamente.
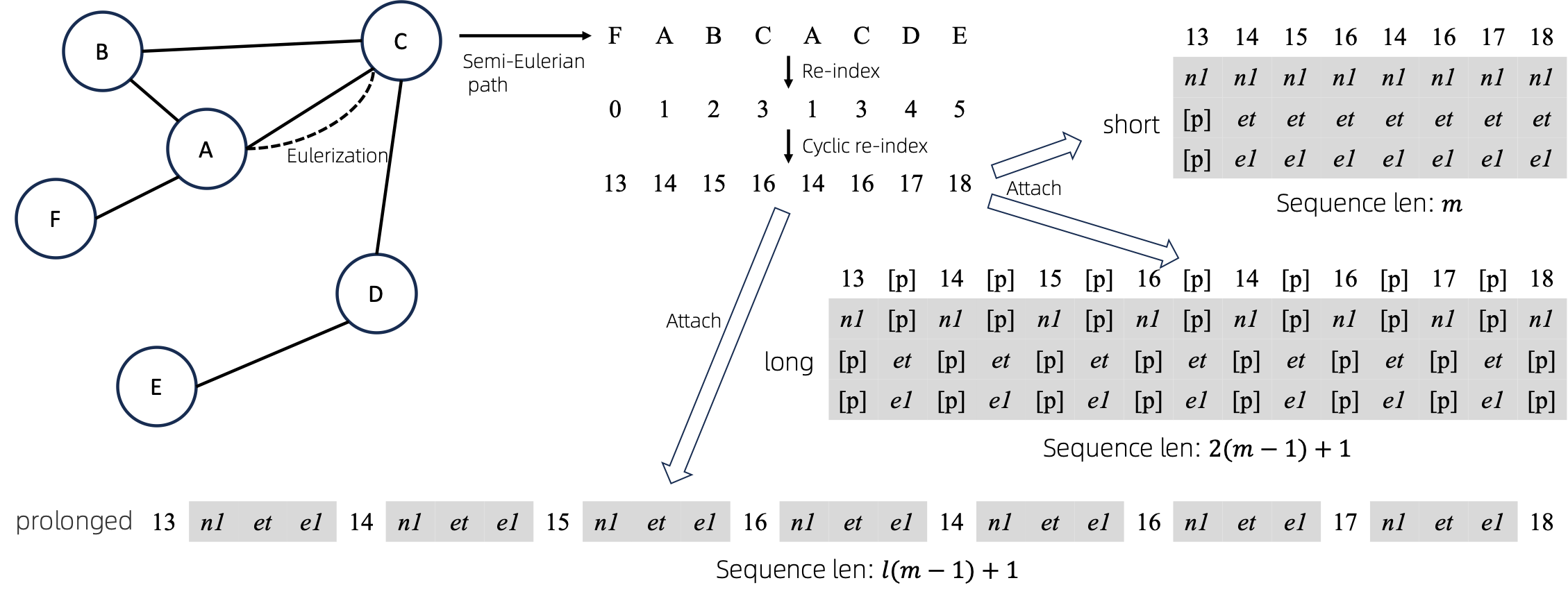
Supongamos que el gráfico tiene atributos de un nodo y atributos de un borde, y luego los métodos short , long y prolong se muestran arriba.
En las figuras anteriores, n1 , n2 y e1 representan los tokens de los atributos de nodo y borde, y [p] representa el token de relleno.
Reindexación cíclica de nodos
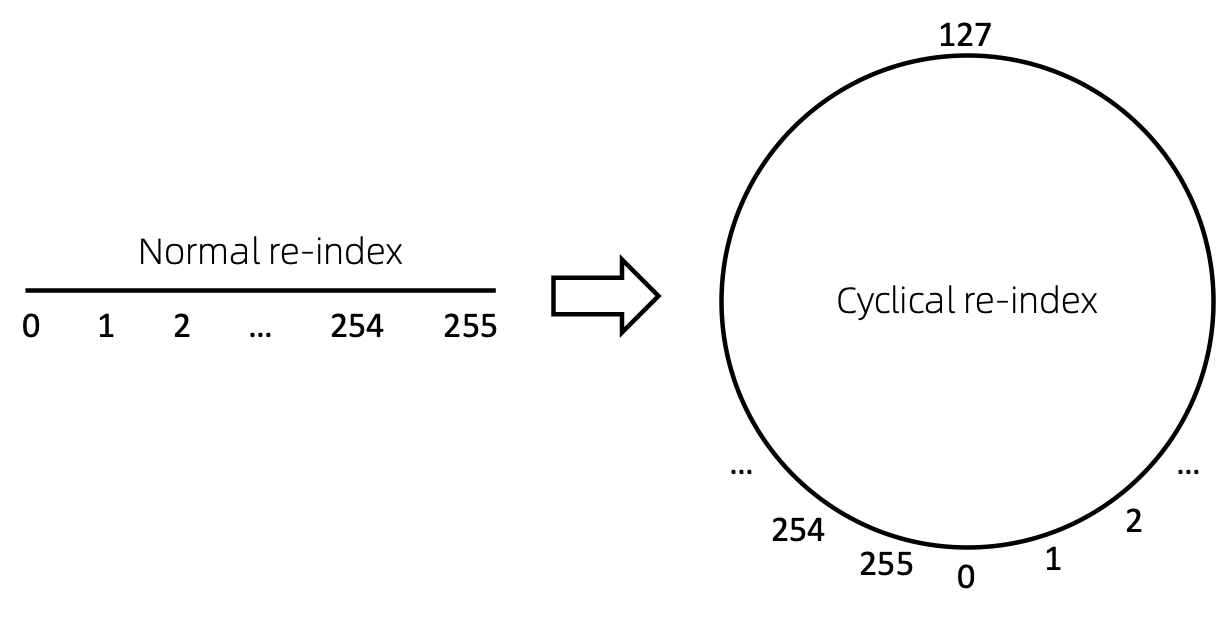
Una forma sencilla de volver a indexar la secuencia de nodos es comenzar con 0 y agregar 1 de forma incremental. De esta manera, los tokens de índices pequeños estarán suficientemente entrenados y los índices grandes no. Para superar esto, proponemos cyclical re-index , que comienza con un número aleatorio en el rango dado, digamos [0, 255] , y se incrementa en 1. Después de alcanzar el límite, por ejemplo, 255 , el siguiente índice de nodo será 0 .
Resultados
Anticuado. Se actualizará pronto.
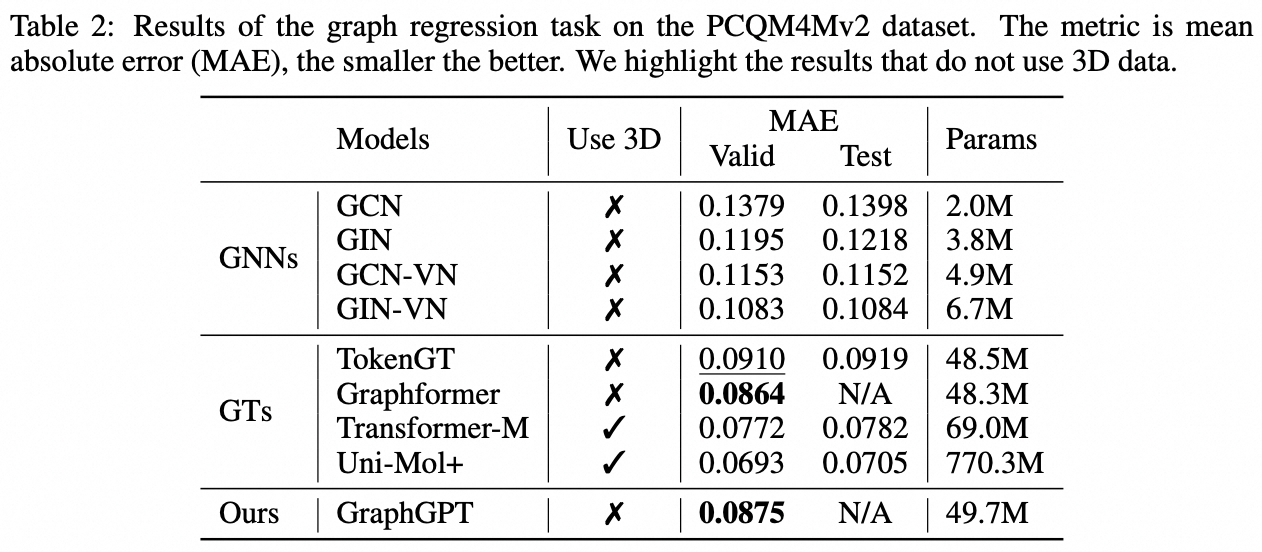
Tarea a nivel de gráfico: conjunto de datos PCQM4M-v2
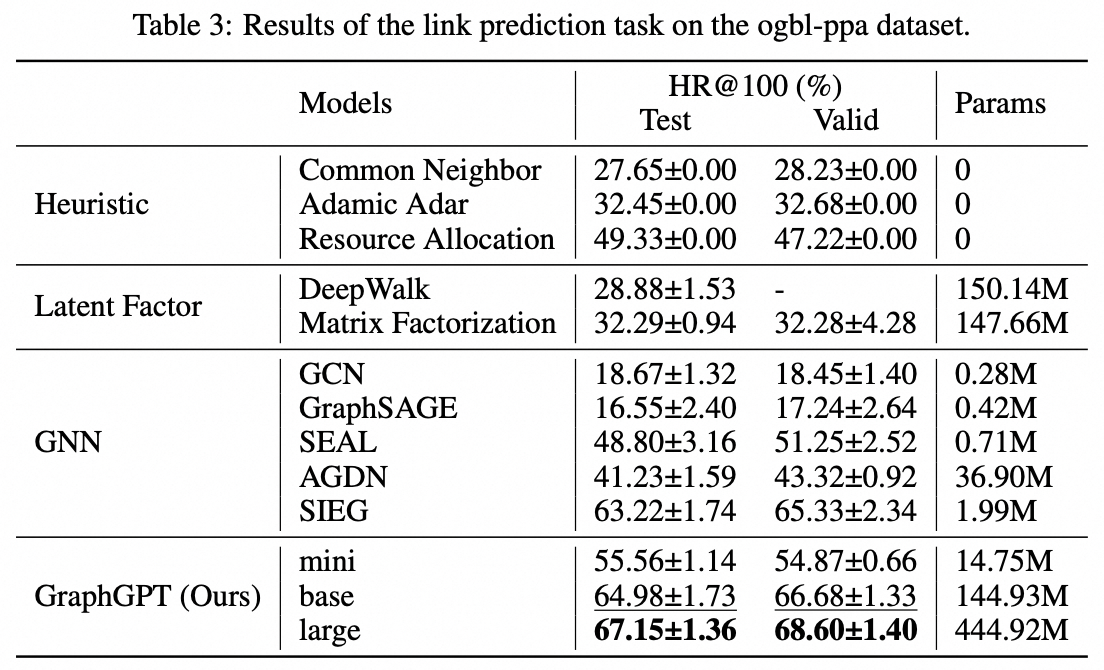
Tarea a nivel de borde: conjunto de datos ogbl-ppa
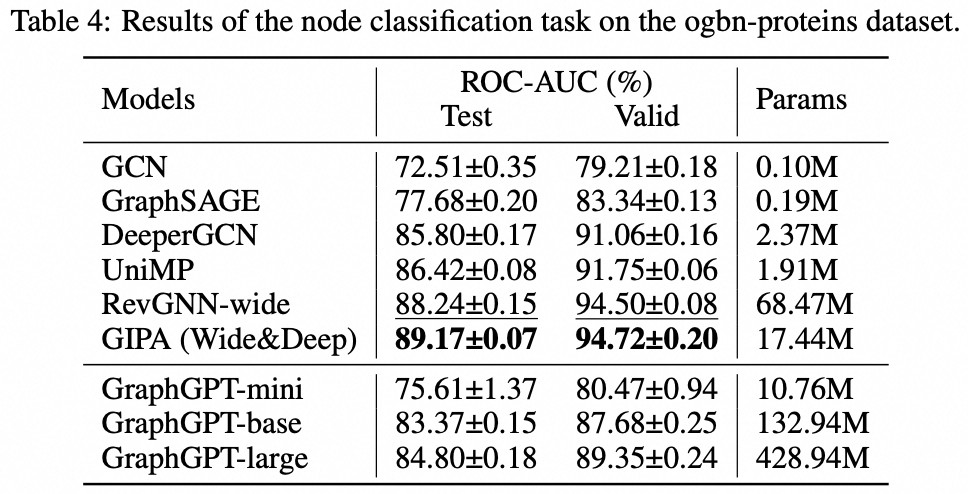
Tarea a nivel de nodo: conjunto de datos de proteínas ogbn
Instalación
git clone https://github.com/alibaba/graph-gpt.git
- Instale las dependencias en requisitos.txt (Usando Anaconda, probado con py38, pytorch-1131 y CUDA-11.7, 11.8 y 12.1 en GPU V100 y A100)
conda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bc
Conjuntos de datos
Los conjuntos de datos se descargan utilizando el paquete Python ogb.
Cuando ejecuta scripts en ./examples , el conjunto de datos se descargará automáticamente.
Sin embargo, el conjunto de datos PCQM4M-v2 es enorme y la descarga y el preprocesamiento pueden resultar problemáticos. Sugerimos cd ./src/utils/ y python dataset_utils.py para descargar y preprocesar el conjunto de datos por separado.
Correr
- Preentrenamiento: modifique los parámetros en
./examples/graph_lvl/pcqm4m_v2_pretrain.sh , por ejemplo, dataset_name , model_name , batch_size , workerCount , etc., y luego ejecute ./examples/graph_lvl/pcqm4m_v2_pretrain.sh para preentrenar el modelo con PCQM4M-v2. conjunto de datos.- Para ejecutar el ejemplo de juguete, ejecute
./examples/toy_examples/reddit_pretrain.sh directamente.
- Ajuste fino: modifique los parámetros en
./examples/graph_lvl/pcqm4m_v2_supervised.sh , por ejemplo, dataset_name , model_name , batch_size , workerCount , pretrain_cpt , etc., y luego ejecute ./examples/graph_lvl/pcqm4m_v2_supervised.sh para ajustar con las tareas posteriores. .- Para ejecutar el ejemplo de juguete, ejecute
./examples/toy_examples/reddit_supervised.sh directamente.
Norma de código
Compromiso previo
- Consulte el sitio web oficial para obtener más detalles.
-
.pre-commit-config.yaml : crea el archivo con el siguiente contenido para Python repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : black
-
pre-commit install : instale la confirmación previa en sus ganchos de git.- La confirmación previa ahora se ejecutará en cada confirmación.
- Cada vez que clones un proyecto usando la confirmación previa, ejecutar
pre-commit install siempre debe ser lo primero que hagas.
-
pre-commit run --all-files : ejecuta todos los enlaces de confirmación previa en un repositorio -
pre-commit autoupdate : actualice sus enlaces a la última versión automáticamente. -
git commit -n : las comprobaciones previas a la confirmación se pueden deshabilitar para una confirmación en particular con el comando
Citación
Si encuentra útil este trabajo, por favor cite los siguientes artículos:
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}Contacto
Qifang Zhao ([email protected])
¡Apreciamos sinceramente sus sugerencias sobre nuestro trabajo!
Licencia
Publicado bajo la licencia MIT (ver LICENSE ):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


