VisualGLM 6B
1.0.0
? HF Repo • ⚒️ SwissArmyTransformer (sábado) • ?
• ? [CogView@NeurIPS 21] [GitHub] • ?
Únase a nosotros en Slack y WeChat
[2023.10] Bienvenido a prestar atención a CogVLM (https://github.com/THUDM/CogVLM), un modelo de diálogo multimodal de nueva generación de Zhipu AI. Adopta la nueva arquitectura de expertos visuales y obtuvo el primer lugar en 10. Tareas multimodales clásicas autorizadas. El modelo inglés actual de código abierto CogVLM-17B se basará en el modelo chino de código abierto GLM.
VisualGLM-6B es un modelo de lenguaje de diálogo multimodal de código abierto que admite imágenes, chino e inglés . El modelo de lenguaje se basa en ChatGLM-6B con 6,2 mil millones de parámetros y la parte de imagen construye un puente entre el modelo visual y el modelo. modelo de lenguaje a través del entrenamiento de BLIP2-Qformer, con un modelo total que comprende 7.8 mil millones de parámetros. Haga clic aquí para ver la versión en inglés.
VisualGLM-6B es un modelo de lenguaje de diálogo multimodal de código abierto que admite imágenes, chino e inglés . El modelo de lenguaje se basa en ChatGLM-6B y tiene 6,2 mil millones de parámetros. La parte de la imagen construye un puente entre el modelo visual y el modelo de lenguaje. Al entrenar BLIP2-Qformer, el modelo general tiene un total de 7.800 millones de parámetros.
VisualGLM-6B se basa en 30 millones de pares de imágenes y texto en chino de alta calidad del conjunto de datos CogView y está preentrenado con 300 millones de pares de imágenes y texto en inglés proyectados. Los pesos de chino e inglés son los mismos. Este método de entrenamiento alinea mejor la información visual con el espacio semántico de ChatGLM; en la etapa de ajuste posterior, el modelo se entrena con datos visuales largos de preguntas y respuestas para generar respuestas que se ajusten a las preferencias humanas.
VisualGLM-6B está entrenado por la biblioteca SwissArmyTransformer ( sat para abreviar), que es una biblioteca de herramientas que admite la modificación y el entrenamiento flexibles de Transformer, y admite métodos eficientes de ajuste fino de parámetros como Lora y P-tuning. Este proyecto proporciona una interfaz Huggingface que se adapta a los hábitos del usuario y también proporciona una interfaz basada en sat.
Combinado con la tecnología de cuantificación de modelos, los usuarios pueden implementarla localmente en tarjetas gráficas de consumo (el mínimo requerido es 6,3G de memoria de video en el nivel de cuantificación INT4).
El modelo de código abierto VisualGLM-6B tiene como objetivo promover el desarrollo de tecnología de modelos grandes junto con la comunidad de código abierto. Se ruega a los desarrolladores y a todos que respeten el acuerdo de código abierto y no utilicen este modelo, código y derivados de código abierto. este proyecto de código abierto para cualquier propósito que pueda causar daño al país y a la sociedad. Usos nocivos y cualquier servicio que no haya sido evaluado y documentado en materia de seguridad. Actualmente, este proyecto no ha desarrollado oficialmente ninguna aplicación basada en VisualGLM-6B, incluidos sitios web, aplicaciones de Android, aplicaciones de Apple iOS, aplicaciones de Windows, etc.
Dado que VisualGLM-6B todavía se encuentra en la versión v1, actualmente se sabe que tiene bastantes limitaciones , como problemas de factibilidad de la descripción de la imagen/alucinación del modelo, captura insuficiente de información detallada de la imagen y algunas limitaciones de los modelos de lenguaje. Aunque el modelo se esfuerza por garantizar el cumplimiento y la precisión de los datos en todas las etapas del entrenamiento, debido a la pequeña escala del modelo VisualGLM-6B y al hecho de que el modelo se ve afectado por factores probabilísticos y aleatorios, no se puede garantizar la precisión del contenido de salida. , y el modelo es fácilmente engañoso (consulte la sección Limitaciones para obtener más detalles). En versiones posteriores de VisualGLM, se harán esfuerzos para optimizar dichos problemas. Este proyecto no asume ningún riesgo ni responsabilidad que surja de los riesgos para la seguridad de los datos y la opinión pública causados por modelos y códigos de fuente abierta, o cualquier modelo que sea engañado, abusado, difundido o explotado indebidamente.
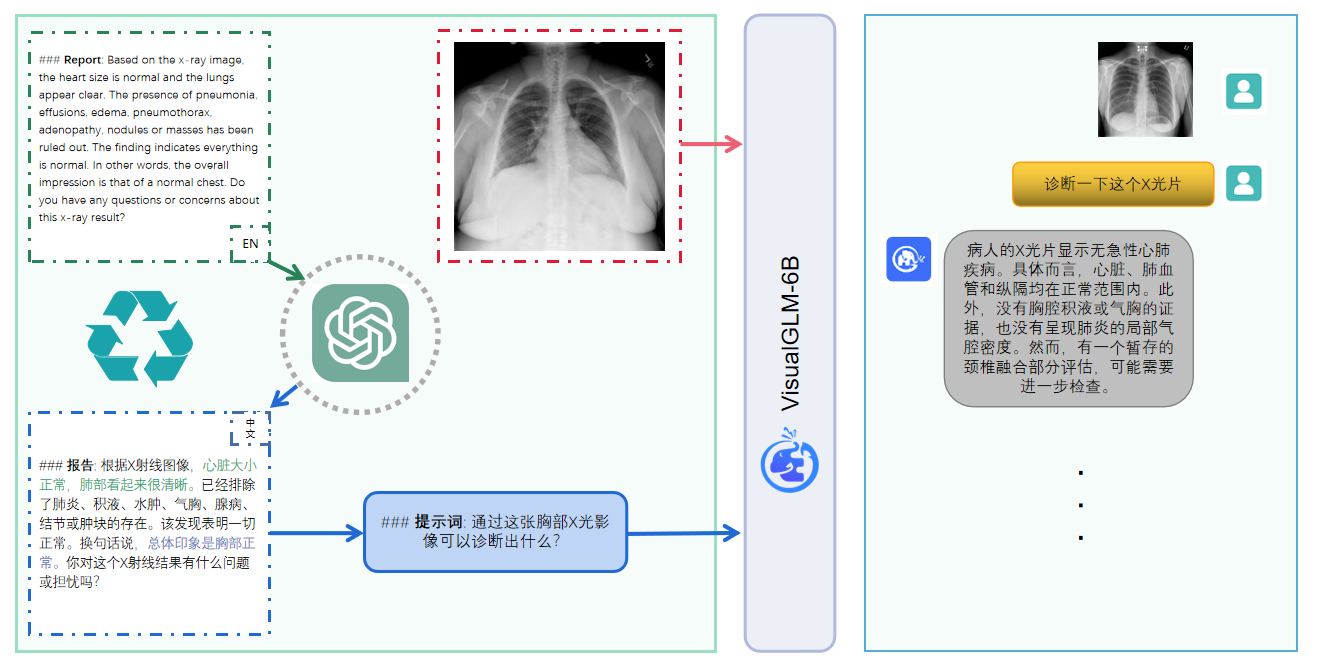
VisualGLM-6B puede realizar preguntas y respuestas relacionadas con conocimientos de descripción de imágenes. 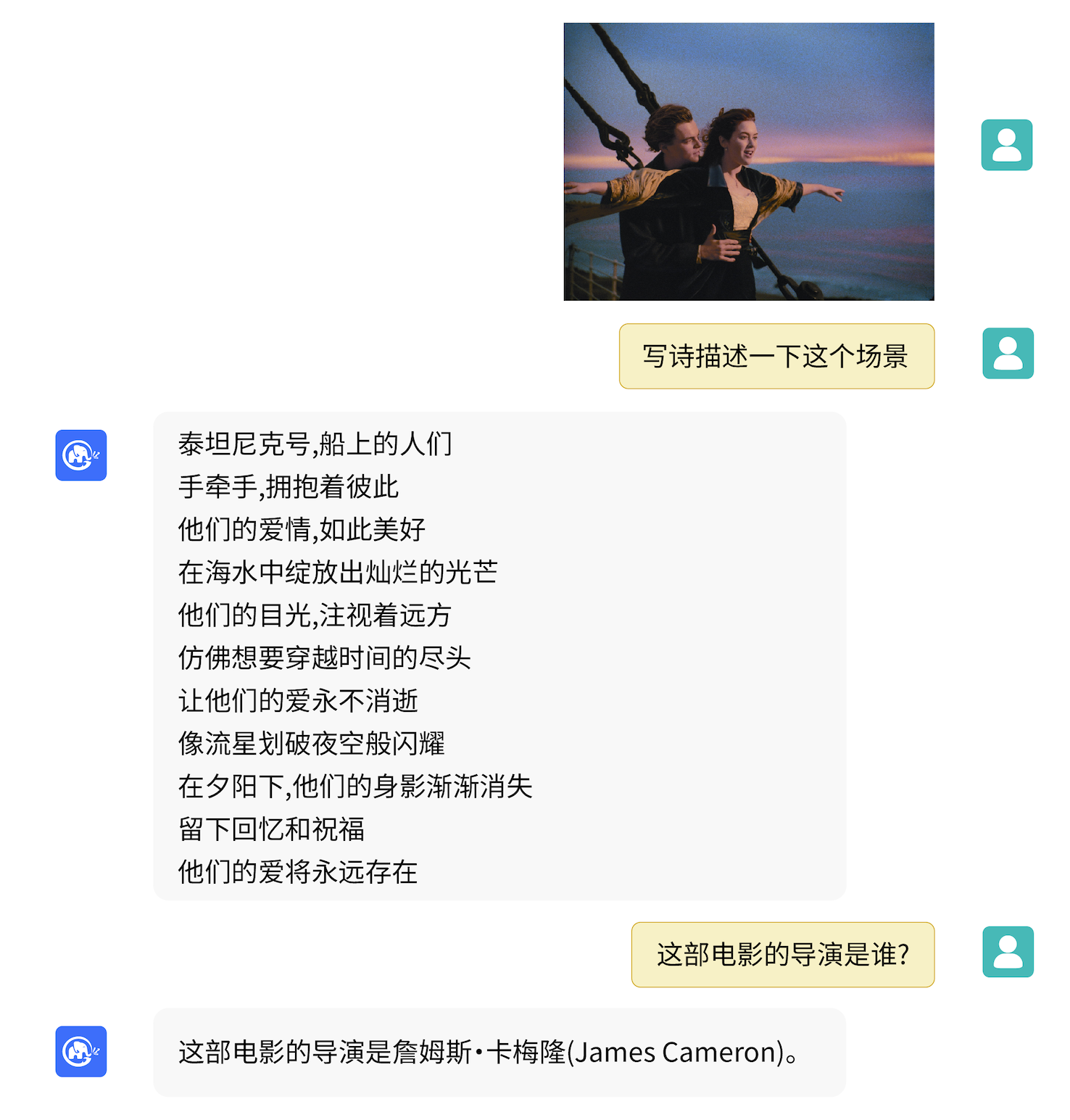



Utilice pip para instalar dependencias
pip install -i https://pypi.org/simple -r requirements.txt
# 国内请使用aliyun镜像,TUNA等镜像同步最近出现问题,命令如下
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
En este momento, deepspeed (que admite el entrenamiento de la biblioteca sat ) se instalará de forma predeterminada. Esta biblioteca no es necesaria para la inferencia de modelos. Al mismo tiempo, algunos entornos de Windows encontrarán problemas al instalar esta biblioteca. Si queremos omitir la instalación deepspeed , podemos cambiar el comando a
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements_wo_ds.txt
pip install -i https://mirrors.aliyun.com/pypi/simple/ --no-deps "SwissArmyTransformer>=0.4.4"
Si usa la biblioteca de transformadores Huggingface para llamar al modelo ( ¡también necesita instalar el paquete de dependencia anterior! ), puede pasar el siguiente código (donde la ruta de la imagen es la ruta local):
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True )
model = AutoModel . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True ). half (). cuda ()
image_path = "your image path"
response , history = model . chat ( tokenizer , image_path , "描述这张图片。" , history = [])
print ( response )
response , history = model . chat ( tokenizer , image_path , "这张图片可能是在什么场所拍摄的?" , history = history )
print ( response ) El código anterior descargará automáticamente la implementación del modelo y los parámetros de transformers . La implementación completa del modelo se puede encontrar en Hugging Face Hub. Si tarda en descargar los parámetros del modelo desde Hugging Face Hub, puede descargar manualmente el archivo de parámetros del modelo desde aquí y cargar el modelo localmente. Para conocer métodos específicos, consulte Carga del modelo desde local. Para obtener información sobre cuantificación, inferencia de CPU, aceleración de backend de Mac MPS, etc. según el modelo de biblioteca de transformadores, consulte la implementación de bajo costo de ChatGLM-6B.
Si usa la biblioteca SwissArmyTransformer para llamar al modelo, el método es similar. Puede usar la variable de entorno SAT_HOME para determinar la ubicación de descarga del modelo. En este directorio de almacén:
import argparse
from transformers import AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "THUDM/chatglm-6b" , trust_remote_code = True )
from model import chat , VisualGLMModel
model , model_args = VisualGLMModel . from_pretrained ( 'visualglm-6b' , args = argparse . Namespace ( fp16 = True , skip_init = True ))
from sat . model . mixins import CachedAutoregressiveMixin
model . add_mixin ( 'auto-regressive' , CachedAutoregressiveMixin ())
image_path = "your image path or URL"
response , history , cache_image = chat ( image_path , model , tokenizer , "描述这张图片。" , history = [])
print ( response )
response , history , cache_image = chat ( None , model , tokenizer , "这张图片可能是在什么场所拍摄的?" , history = history , image = cache_image )
print ( response ) También se puede realizar fácilmente un ajuste eficiente de los parámetros utilizando la biblioteca sat .
Las tareas multimodales están ampliamente distribuidas y son de muchos tipos, y la formación previa a menudo no puede cubrirlo todo. Aquí proporcionamos un ejemplo de un pequeño ajuste de muestra, utilizando 20 imágenes anotadas para mejorar la capacidad del modelo para responder preguntas "de fondo".
Descomprima fewshot-data.zip y ejecute el siguiente comando:
bash finetune/finetune_visualglm.sh
Actualmente, se admiten tres métodos de ajuste fino:
--layer_range y --lora_rank se pueden ajustar de acuerdo con el escenario y el volumen de datos específicos.bash finetune/finetune_visualglm_qlora.sh . QLoRA cuantifica la capa lineal de ChatGLM con 4 bits y solo requiere 9,8 GB de memoria de video para el ajuste fino.--use_lora con --use_ptuning , pero no se recomienda a menos que el escenario de aplicación del modelo sea muy fijo.Después del entrenamiento, puede utilizar el siguiente comando para realizar inferencias:
python cli_demo.py --from_pretrained your_checkpoint_path --prompt_zh 这张图片的背景里有什么内容?
Antes del ajuste fino:
欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/2p.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:人们总是被生活琐事所困扰,无法摆脱束缚.
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/meme.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是一张狗的图片,它躺在木地板上。
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/passport.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是一台电脑键盘和两张护照。
用户:clear
请输入图像路径或URL(回车进入纯文本对话):
Después del ajuste fino:
欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/2p.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是雨天,
用户:描述一下这张图片。
VisualGLM-6B:这张图片描绘了雨天的情景,雨水淅淅沥沥地落在地面上。人们穿着雨衣或雨伞,走在雨中,似乎在寻找着什么.
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/meme.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是木质地板。
用户:什么颜色的地板
VisualGLM-6B:这张图片的背景是蓝色的。
用户:描述一下这张图片。
VisualGLM-6B:这张图片描绘了一只棕色的小狗躺在蓝色的木质地板上。
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/passport.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是电脑键盘。
用户:描述一下这张图片。
VisualGLM-6B:这张图片的特点是电脑键盘和护照。
用户:有几张护照
VisualGLM-6B:两张护照。
用户:clear
请输入图像路径或URL(回车进入纯文本对话):
Si desea fusionar los parámetros de la parte LoRA con los pesos originales, puede llamar merge_lora() , por ejemplo:
from finetune_visualglm import FineTuneVisualGLMModel
import argparse
model , args = FineTuneVisualGLMModel . from_pretrained ( 'checkpoints/finetune-visualglm-6b-05-19-07-36' ,
args = argparse . Namespace (
fp16 = True ,
skip_init = True ,
use_gpu_initialization = True ,
device = 'cuda' ,
))
model . get_mixin ( 'lora' ). merge_lora ()
args . layer_range = []
args . save = 'merge_lora'
args . mode = 'inference'
from sat . training . model_io import save_checkpoint
save_checkpoint ( 1 , model , None , None , args ) El ajuste fino requiere la instalación de la biblioteca deepspeed . Actualmente, este proceso solo es compatible con sistemas Linux en un futuro próximo.
python cli_demo.py El programa descargará automáticamente el modelo sat y llevará a cabo una conversación interactiva en la línea de comando. Ingrese las instrucciones y presione Entrar para generar una respuesta. Ingrese borrar para borrar el historial de conversaciones.
 El programa proporciona los siguientes hiperparámetros para controlar el proceso de generación y la precisión de la cuantificación:
El programa proporciona los siguientes hiperparámetros para controlar el proceso de generación y la precisión de la cuantificación:
usage: cli_demo.py [-h] [--max_length MAX_LENGTH] [--top_p TOP_P] [--top_k TOP_K] [--temperature TEMPERATURE] [--english] [--quant {8,4}]
optional arguments:
-h, --help show this help message and exit
--max_length MAX_LENGTH
max length of the total sequence
--top_p TOP_P top p for nucleus sampling
--top_k TOP_K top k for top k sampling
--temperature TEMPERATURE
temperature for sampling
--english only output English
--quant {8,4} quantization bits
Cabe señalar que durante el entrenamiento, las palabras clave para los pares de preguntas y respuestas en inglés son Q: A: :, mientras que las indicaciones en chino son问:答: Las indicaciones en chino se utilizan en la demostración web, por lo que las respuestas en inglés serán peores. y mezclado con chino si es necesario. Para responder en inglés, utilice la opción --english en cli_demo.py .
También proporcionamos una herramienta de línea de comando con efecto de máquina de escribir heredada de ChatGLM-6B . Esta herramienta utiliza el modelo Huggingface:
python cli_demo_hf.pyTambién admitimos la implementación de múltiples tarjetas en paralelo: (debe actualizar la última versión de sat. Si descargó checkpoint antes, también debe eliminarlo manualmente y descargarlo nuevamente)
torchrun --nnode 1 --nproc-per-node 2 cli_demo_mp.py
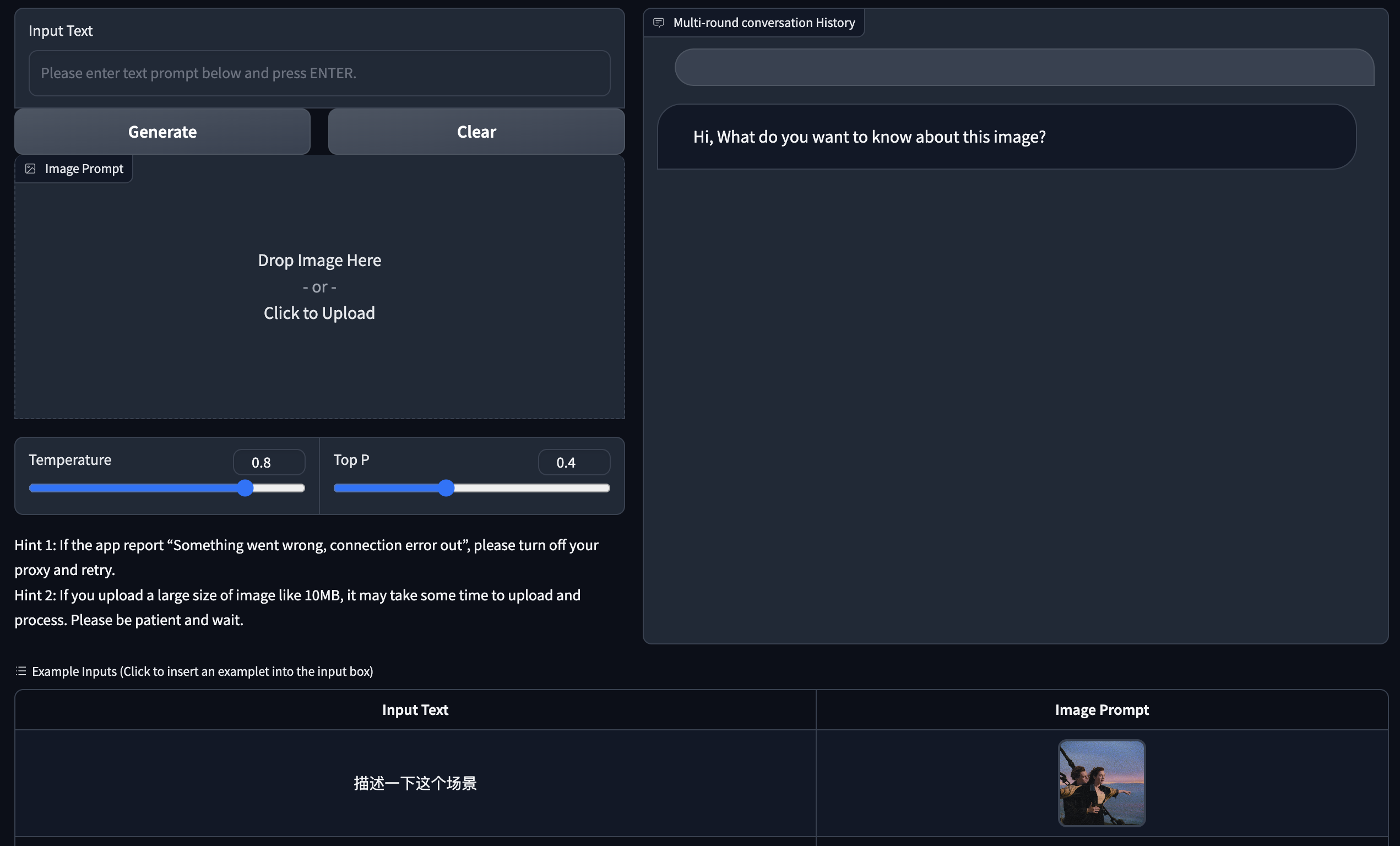
Proporcionamos una versión web de demostración basada en Gradio. Primero instale Gradio: pip install gradio . Luego descargue e ingrese a este almacén para ejecutar web_demo.py :
git clone https://github.com/THUDM/VisualGLM-6B
cd VisualGLM-6B
python web_demo.py
El programa descargará automáticamente el modelo sat, ejecutará un servidor web y generará la dirección. Abra la dirección de salida en un navegador para usarla.
También proporcionamos una herramienta de versión web con efecto de máquina de escribir heredada de ChatGLM-6B . Esta herramienta utiliza el modelo Huggingface y se ejecutará en el puerto :8080 después del inicio:
python web_demo_hf.py Ambas demostraciones de la versión web aceptan el parámetro de línea de comando --share para generar enlaces públicos de gradio y aceptan --quant 4 y --quant 8 para usar cuantificación de 4 bits/cuantización de 8 bits respectivamente para reducir el uso de memoria de video.
Primero, debe instalar dependencias adicionales pip install fastapi uvicorn y luego ejecutar api.py en el almacén:
python api.py El programa descargará automáticamente el modelo sat, que se implementa en el puerto local 8080 de forma predeterminada y se llama mediante el método POST. El siguiente es un ejemplo del uso de curl para realizar solicitudes. En términos generales, también puede usar el método de código para realizar POST.
echo " { " image " : " $( base64 path/to/example.jpg ) " , " text " : "描述这张图片" , " history " :[]} " > temp.json
curl -X POST -H " Content-Type: application/json " -d @temp.json http://127.0.0.1:8080El valor de retorno obtenido es
{
"response":"这张图片展现了一只可爱的卡通羊驼,它站在一个透明的背景上。这只羊驼长着一张毛茸茸的耳朵和一双大大的眼睛,它的身体是白色的,带有棕色斑点。",
"history":[('描述这张图片', '这张图片展现了一只可爱的卡通羊驼,它站在一个透明的背景上。这只羊驼长着一张毛茸茸的耳朵和一双大大的眼睛,它的身体是白色的,带有棕色斑点。')],
"status":200,
"time":"2023-05-16 20:20:10"
}
También proporcionamos api_hf.py que utiliza el modelo Huggingface. El uso es coherente con la API del modelo sat.
python api_hf.pyEn la implementación de Huggingface, el modelo se carga con precisión FP16 de forma predeterminada y ejecutar el código anterior requiere aproximadamente 15 GB de memoria de video. Si su GPU tiene memoria limitada, puede intentar cargar el modelo en modo cuantificado. Cómo usarlo:
# 按需修改,目前只支持 4/8 bit 量化。下面将只量化ChatGLM,ViT 量化时误差较大
model = AutoModel . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True ). quantize ( 8 ). half (). cuda () En la implementación sat, primero debe pasar el parámetro para cambiar la ubicación de carga a cpu y luego realizar la cuantificación. El método es el siguiente; consulte cli_demo.py para obtener más detalles:
from sat . quantization . kernels import quantize
quantize ( model , args . quant ). cuda ()
# 只需要 7GB 显存即可推理Este proyecto está en la versión V1. Los parámetros y el volumen de cálculo de los modelos visuales y de lenguaje son relativamente pequeños. Hemos resumido las principales direcciones de mejora de la siguiente manera:
El código de este repositorio es de código abierto según el acuerdo Apache-2.0. El uso de los pesos del modelo VisualGLM-6B debe cumplir con la Licencia del Modelo.
Si encuentra útil nuestro trabajo, considere citar los siguientes artículos
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}
@article{ding2021cogview,
title={Cogview: Mastering text-to-image generation via transformers},
author={Ding, Ming and Yang, Zhuoyi and Hong, Wenyi and Zheng, Wendi and Zhou, Chang and Yin, Da and Lin, Junyang and Zou, Xu and Shao, Zhou and Yang, Hongxia and others},
journal={Advances in Neural Information Processing Systems},
volume={34},
pages={19822--19835},
year={2021}
}
El conjunto de datos en la fase de ajuste de instrucciones de VisualGLM-6B contiene parte de los datos gráficos y de texto en inglés de los proyectos MiniGPT-4 y LLAVA, así como muchos conjuntos de datos de trabajo intermodales clásicos. Les agradecemos sinceramente su colaboración. contribuciones.


