YAYI2
1.0.0

[README] [?HF Repo] [?Versión web]
chino | inglés
[2024.03.28] Todos los modelos y datos se cargan en la Comunidad Magic.
[2023.12.22] Publicamos el informe técnico YAYI 2: Modelos de lenguajes grandes multilingües de código abierto.
YAYI 2 es una nueva generación de modelo de lenguaje grande de código abierto desarrollado por Zhongke Wenge, que incluye versiones Base y Chat, con un tamaño de parámetro de 30B. YAYI2-30B es un modelo de lenguaje grande basado en Transformer, que utiliza un corpus multilingüe de alta calidad de más de 2 billones de tokens para el entrenamiento previo. Para escenarios de aplicación generales y específicos de dominio, utilizamos millones de instrucciones para realizar ajustes y utilizamos métodos de aprendizaje de refuerzo de retroalimentación humana para alinear mejor el modelo con los valores humanos.
El modelo de código abierto esta vez es el modelo base YAYI2-30B. Esperamos promover el desarrollo de la comunidad china de código abierto de grandes modelos previamente capacitados a través del código abierto de los grandes modelos de Yayi y contribuir activamente a ello. A través del código abierto, trabajamos con todos los socios para construir el gran ecosistema de modelos de Yayi.
Para obtener más detalles técnicos, lea nuestro informe técnico YAYI 2: Modelos de lenguajes grandes multilingües de código abierto.
| Nombre del conjunto de datos | tamaño | ¿Identificación del modelo HF? | Descargar dirección | Logotipo del modelo mágico | Descargar dirección |
|---|---|---|---|---|---|
| Datos previos al entrenamiento de YAYI2 | 500G | wenge-research/yayi2_pretrain_data | Descarga del conjunto de datos | wenge-research/yayi2_pretrain_data | Descarga del conjunto de datos |
| Nombre del modelo | longitud del contexto | ¿Identificación del modelo HF? | Descargar dirección | Logotipo del modelo mágico | Descargar dirección |
|---|---|---|---|---|---|
| YAYI2-30B | 4096 | investigación-wengué/yayi2-30b | Descarga del modelo | investigación-wengué/yayi2-30b | Descarga del modelo |
| YAYI2-30B-Chat | 4096 | wenge-research/yayi2-30b-chat | Muy pronto... |
Realizamos evaluaciones de múltiples conjuntos de datos de referencia, incluidos C-Eval, MMLU, CMMLU, AGIEval, GAOKAO-Bench, GSM8K, MATH, BBH, HumanEval y MBPP. Examinamos el desempeño del modelo en la comprensión del lenguaje, el conocimiento de la materia, el razonamiento matemático, el razonamiento lógico y la generación de código. El modelo YAYI 2 demuestra importantes mejoras de rendimiento con respecto a modelos de código abierto de tamaño similar.
| conocimiento de la materia | matemáticas | razonamiento lógico | código | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Modelo | Evaluación C(val) | MMLU | AGIEval | CMMLU | GAOKAO-Banco | GSM8K | MATEMÁTICAS | BBH | evaluación humana | MBPP |
| 5 tiros | 5 tiros | tiro 3/0 | 5 tiros | 0 disparos | 8/4 disparos | 4 tiros | 3 disparos | 0 disparos | 3 disparos | |
| MPT-30B | - | 46,9 | 33,8 | - | - | 15.2 | 3.1 | 38.0 | 25.0 | 32,8 |
| Halcón-40B | - | 55,4 | 37.0 | - | - | 19.6 | 5.5 | 37.1 | 0,6 | 29,8 |
| LLaMA2-34B | - | 62,6 | 43.4 | - | - | 42.2 | 6.2 | 44.1 | 22.6 | 33.0 |
| Baichuan2-13B | 59.0 | 59,5 | 37,4 | 61.3 | 45,6 | 52,6 | 10.1 | 49.0 | 17.1 | 30,8 |
| Qwen-14B | 71,7 | 67,9 | 51,9 | 70.2 | 62,5 | 61,6 | 25.2 | 53,7 | 32.3 | 39,8 |
| PasanteLM-20B | 58,8 | 62.1 | 44,6 | 59.0 | 45,5 | 52,6 | 7.9 | 52,5 | 25.6 | 35,6 |
| Aquila2-34B | 98,5 | 76.0 | 43,8 | 78,5 | 37,8 | 50.0 | 17.8 | 42,5 | 0.0 | 41.0 |
| Yi-34B | 81,8 | 76,3 | 56,5 | 82,6 | 68.3 | 67,6 | 15.9 | 66,4 | 26.2 | 38.2 |
| YAYI2-30B | 80,9 | 80,5 | 62.0 | 84.0 | 64,4 | 71.2 | 14.8 | 54,5 | 53.1 | 45,8 |
Realizamos nuestra evaluación utilizando el código fuente proporcionado por el repositorio OpenCompass Github. Para modelos de comparación, enumeramos los resultados de su evaluación en la lista OpenCompass, al 15 de diciembre de 2023. Para otros modelos que no participaron en la evaluación en la plataforma OpenCompass, incluidos MPT, Falcon y LLaMa 2, adoptamos los resultados informados por LLaMA 2.
Proporcionamos ejemplos simples para ilustrar cómo usar rápidamente YAYI2-30B para realizar inferencias. Este ejemplo se puede ejecutar en un solo A100/A800.
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_envTenga en cuenta que este proyecto requiere Python 3.8 o superior.
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))Cuando visita por primera vez, es necesario descargar y cargar el modelo, lo que puede llevar algún tiempo.
Este proyecto admite el ajuste fino de instrucciones basado en el marco de entrenamiento distribuido Deepspeed. Configure el entorno y ejecute el script correspondiente para iniciar el ajuste fino de parámetros completos o el ajuste fino de LoRA.
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps Formato de datos: consulte data/yayi_train_example.json , que es un archivo JSON estándar. Cada dato consta de "system" y "conversations" "conversations" donde "system" es la información de configuración de roles global y puede ser una cadena vacía. "conversations" son múltiples rondas de diálogo entre personajes humanos y yayi.
Instrucciones de operación: Ejecute el siguiente comando para iniciar el ajuste completo de los parámetros del modelo Yayi. Este comando admite entrenamiento con múltiples máquinas y tarjetas. Se recomienda utilizar una configuración de hardware 16*A100 (80G) o superior.
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True O comience a través de la línea de comando:
bash scripts/start.sh Tenga en cuenta que si necesita utilizar la plantilla ChatML para ajustar las instrucciones, puede cambiar --module training.trainer_yayi2 en el comando a --module training.trainer_chatml ; si necesita personalizar la plantilla de Chat, puede modificarla; el sistema en la plantilla de chat de trainer_chatml.py Definiciones de tokens especiales para los tres roles de usuario y asistente. El siguiente es un ejemplo de una plantilla de ChatML. Si se utiliza esta plantilla o una plantilla personalizada durante el entrenamiento, también debe ser coherente durante la inferencia.
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh En la etapa de preentrenamiento, no solo utilizamos datos de Internet para entrenar la capacidad lingüística del modelo, sino que también agregamos datos seleccionados generales y datos de dominio para mejorar las habilidades profesionales del modelo. La distribución de datos es la siguiente: 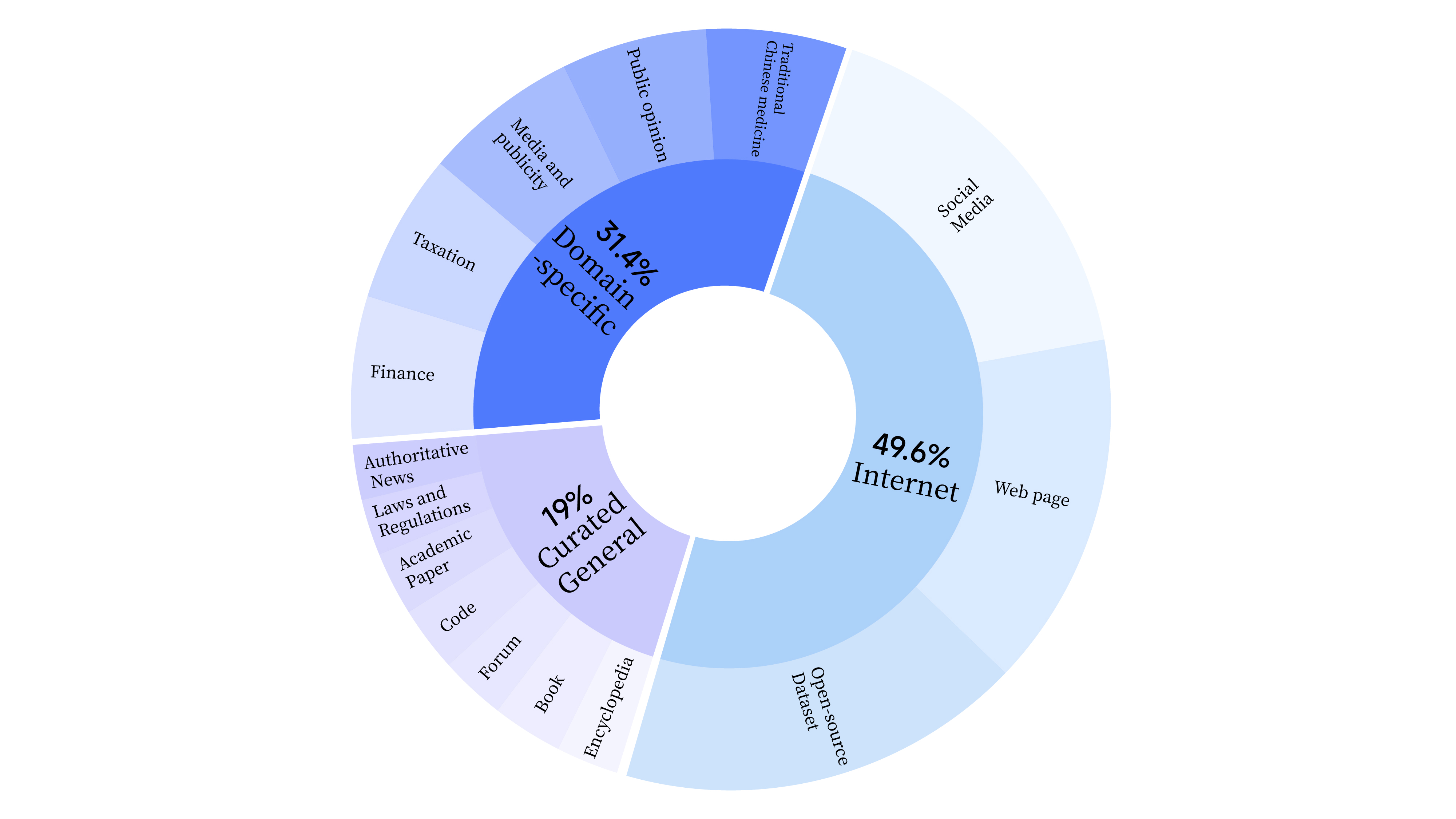
Hemos creado un conjunto de canales de procesamiento de datos para mejorar la calidad de los datos en todos los aspectos, incluidos cuatro módulos: estandarización, limpieza heurística, deduplicación multinivel y filtrado de toxicidad. Recopilamos un total de 240 TB de datos sin procesar y solo quedaron 10,6 TB de datos de alta calidad después del preprocesamiento. El proceso general es el siguiente: 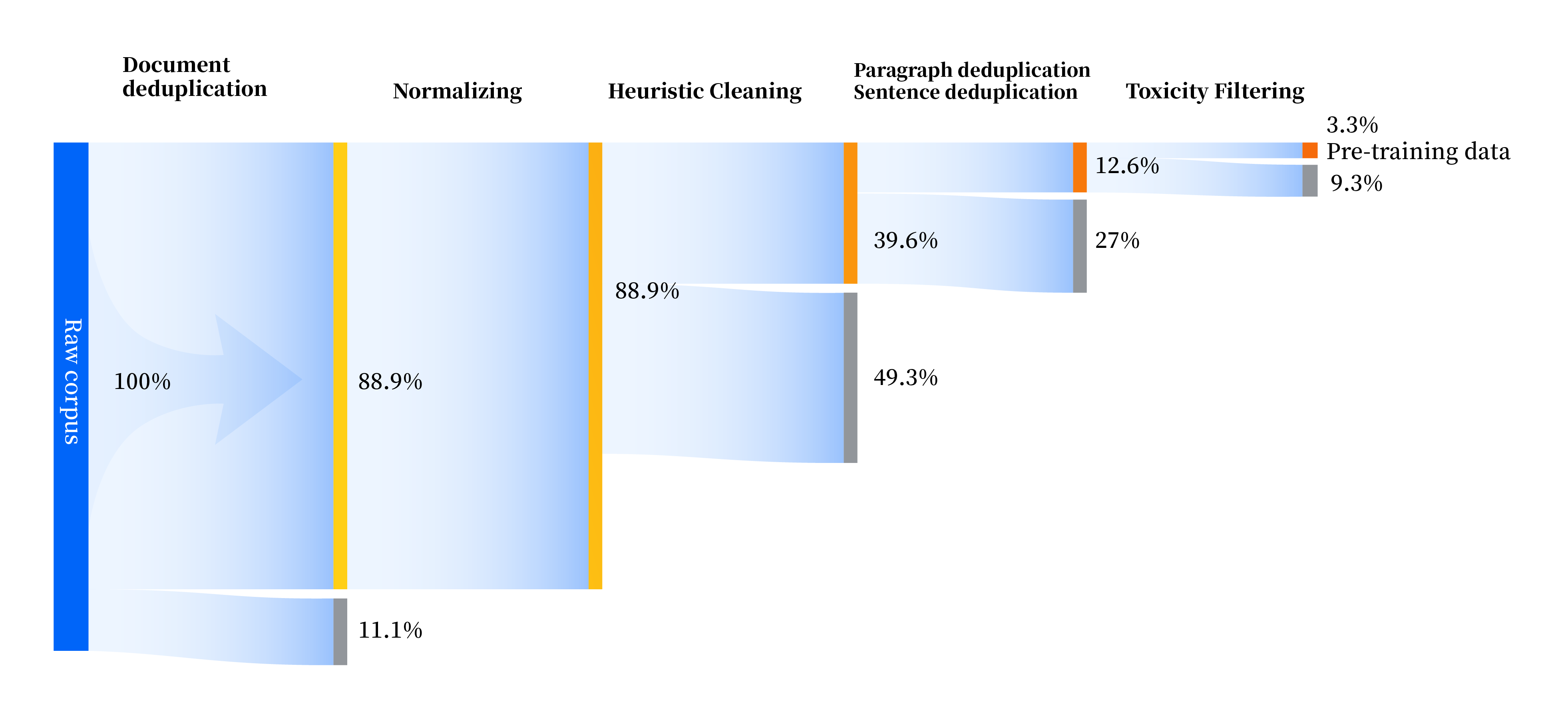

La curva de pérdidas del modelo YAYI 2 se muestra en la siguiente figura: 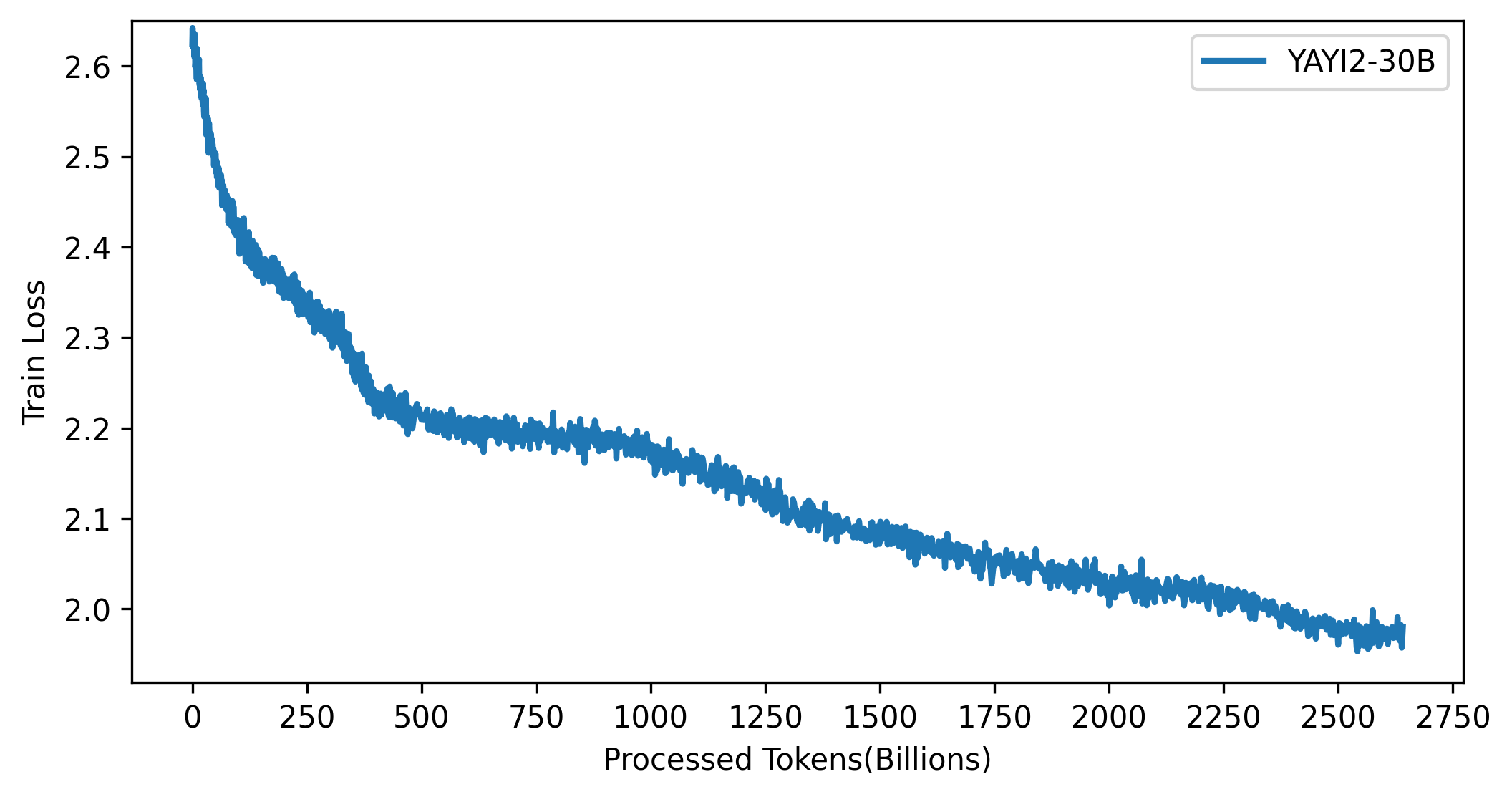
El código de este proyecto es de código abierto de acuerdo con el protocolo Apache-2.0. El uso del modelo YAYI 2 y los datos por parte de la comunidad deben cumplir con el "Acuerdo de licencia comunitaria del modelo Yayi YAYI 2". Si necesita utilizar los modelos de la serie YAYI 2 o sus derivados con fines comerciales, complete la "Información de registro comercial del modelo YAYI 2" y envíela a [email protected]. Le responderemos dentro de los 3 días hábiles posteriores a la recepción del correo electrónico. La revisión se realizará diariamente. Después de pasar la revisión, recibirá una licencia comercial. Cumpla estrictamente con el contenido relevante del "Acuerdo de licencia comercial del modelo YAYI 2" durante el uso.
Si utiliza nuestro modelo en su trabajo, cite nuestro artículo:
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


