Copulas
v0.12.0 - 2024-11-12
Este repositorio es parte del Proyecto Synthetic Data Vault, un proyecto de DataCebo.

Copulas es una biblioteca de Python para modelar distribuciones multivariadas y tomar muestras de ellas utilizando funciones de cópula. Dada una tabla de datos numéricos, use Copulas para aprender la distribución y generar nuevos datos sintéticos siguiendo las mismas propiedades estadísticas.
Características clave:
Modelar datos multivariados. Elija entre una variedad de distribuciones y cópulas univariadas, incluidas las cópulas de Arquímedes, las cópulas gaussianas y las cópulas Vine.
Compare visualmente datos reales y sintéticos después de construir su modelo. Las visualizaciones están disponibles como histogramas 1D, diagramas de dispersión 2D y diagramas de dispersión 3D.
Acceda y manipule los parámetros aprendidos. Con acceso completo a las partes internas del modelo, configure o ajuste los parámetros a su elección.
Instale la biblioteca Copulas usando pip o conda.
pip install copulasconda install -c conda-forge copulasComience a utilizar un conjunto de datos de demostración. Este conjunto de datos contiene 3 columnas numéricas.
from copulas . datasets import sample_trivariate_xyz
real_data = sample_trivariate_xyz ()
real_data . head ()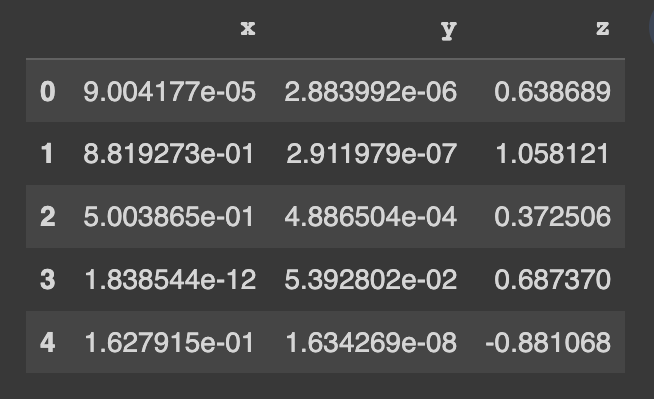
Modele los datos usando una cópula y utilícelos para crear datos sintéticos. La biblioteca de Cópulas ofrece muchas opciones, incluidas Cópulas gaussianas, Cópulas de vid y Cópulas de Arquímedes.
from copulas . multivariate import GaussianMultivariate
copula = GaussianMultivariate ()
copula . fit ( real_data )
synthetic_data = copula . sample ( len ( real_data ))Visualice los datos reales y sintéticos uno al lado del otro. Hagamos esto en 3D para ver nuestro conjunto de datos completo.
from copulas . visualization import compare_3d
compare_3d ( real_data , synthetic_data )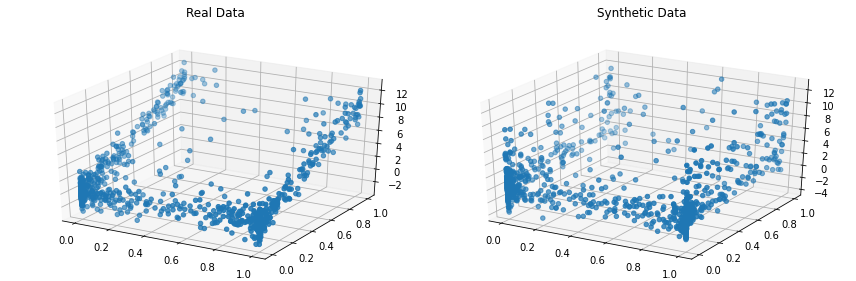
Haga clic a continuación para ejecutar el código usted mismo en un Colab Notebook y descubrir nuevas funciones.
Obtenga más información sobre la biblioteca Copulas en nuestro sitio de documentación.
¿Preguntas o problemas? Únase a nuestro canal de Slack para discutir más sobre Cópulas y datos sintéticos. Si encuentra un error o tiene una solicitud de función, también puede abrir un problema en nuestro GitHub.
¿Interesado en contribuir a Cópulas? Lea nuestra Guía de contribuciones para comenzar.
El proyecto de código abierto Copulas comenzó en el Data to AI Lab del MIT en 2018. ¡Gracias a nuestro equipo de colaboradores que han construido y mantenido la biblioteca a lo largo de los años!
Ver colaboradores

El proyecto Synthetic Data Vault se creó por primera vez en el Data to AI Lab del MIT en 2016. Después de 4 años de investigación y tracción con la empresa, creamos DataCebo en 2020 con el objetivo de hacer crecer el proyecto. Hoy, DataCebo es el orgulloso desarrollador de SDV, el ecosistema más grande para la generación y evaluación de datos sintéticos. Es el hogar de múltiples bibliotecas que admiten datos sintéticos, que incluyen:
Comience a utilizar el paquete SDV: una solución totalmente integrada y su ventanilla única para datos sintéticos. O utilice las bibliotecas independientes para necesidades específicas.


