BentoML
v1.3.14

? Cree API de inferencia de modelos y sistemas de servicio multimodelo con cualquier modelo de IA personalizado o de código abierto. ¡Únete a nuestra comunidad Slack!

BentoML es una biblioteca de Python para crear sistemas de servicio en línea optimizados para aplicaciones de IA e inferencia de modelos.
Instalar BentoML:
# Requires Python≥3.9
pip install -U bentoml
Defina las API en un archivo service.py .
from __future__ import annotations
import bentoml
@ bentoml . service (
resources = { "cpu" : "4" }
)
class Summarization :
def __init__ ( self ) -> None :
import torch
from transformers import pipeline
device = "cuda" if torch . cuda . is_available () else "cpu"
self . pipeline = pipeline ( 'summarization' , device = device )
@ bentoml . api ( batchable = True )
def summarize ( self , texts : list [ str ]) -> list [ str ]:
results = self . pipeline ( texts )
return [ item [ 'summary_text' ] for item in results ]Ejecute el código de servicio localmente (serviendo en http://localhost:3000 de forma predeterminada):
pip install torch transformers # additional dependencies for local run
bentoml serve service.py:SummarizationAhora puedes ejecutar la inferencia desde tu navegador en http://localhost:3000 o con un script de Python:
import bentoml
with bentoml . SyncHTTPClient ( 'http://localhost:3000' ) as client :
summarized_text : str = client . summarize ([ bentoml . __doc__ ])[ 0 ]
print ( f"Result: { summarized_text } " ) Para implementar su código de servicio BentoML, primero cree un archivo bentofile.yaml para definir sus dependencias y entornos. Encuentre la lista completa de opciones de bentofile aquí.
service : ' service:Summarization ' # Entry service import path
include :
- ' *.py ' # Include all .py files in current directory
python :
packages : # Python dependencies to include
- torch
- transformers
docker :
python_version : " 3.11 "Luego, elija una de las siguientes formas de implementación:
Ejecute bentoml build para empaquetar el código, los modelos y las configuraciones de dependencia necesarios en un Bento, el artefacto implementable estandarizado en BentoML:
bentoml buildAsegúrese de que Docker se esté ejecutando. Genere una imagen de contenedor Docker para su implementación:
bentoml containerize summarization:latestEjecute la imagen generada:
docker run --rm -p 3000:3000 summarization:latestBentoCloud proporciona infraestructura informática para una adopción GenAI rápida y confiable. Ayuda a acelerar su proceso de desarrollo de BentoML aprovechando los recursos informáticos de la nube y simplificando la forma de implementar, escalar y operar BentoML en producción.
Regístrese en BentoCloud para obtener acceso personal; para casos de uso empresarial, comuníquese con nuestro equipo.
# After signup, run the following command to create an API token:
bentoml cloud login
# Deploy from current directory:
bentoml deploy . 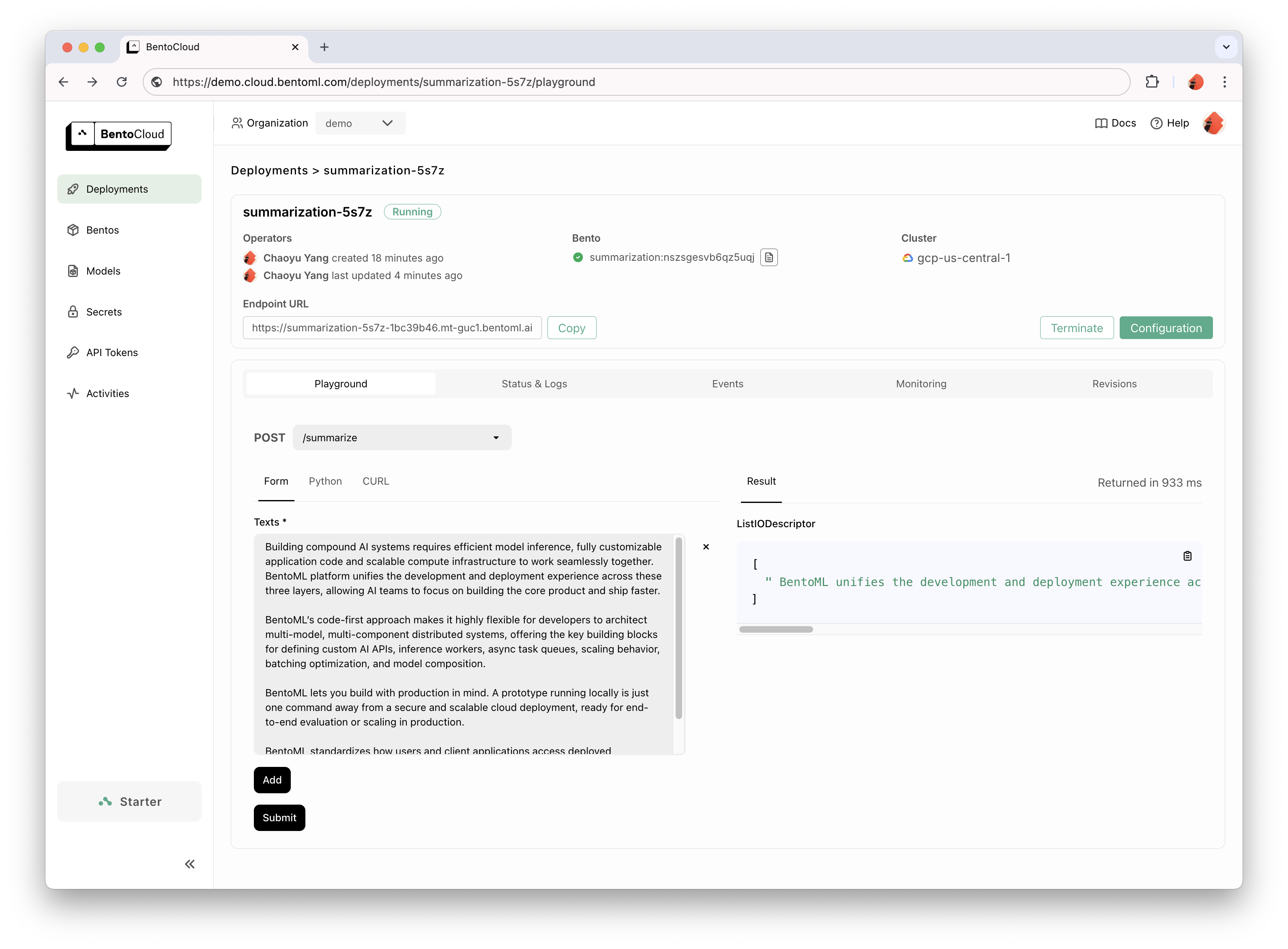
Para obtener explicaciones detalladas, lea el ejemplo de Hola mundo.
Consulte la lista completa para obtener más códigos de muestra y uso.
Consulte Documentación para obtener más tutoriales y guías.
Participe y únase a nuestra comunidad Slack, donde miles de ingenieros de IA/ML se ayudan entre sí, contribuyen al proyecto y hablan sobre la creación de productos de IA.
Para informar un error o sugerir una solicitud de función, utilice Problemas de GitHub.
Hay muchas maneras de contribuir al proyecto:
#bentoml-contributors aquí.¡Gracias a todos nuestros increíbles contribuyentes!
El marco BentoML recopila datos de uso anónimos que ayudan a nuestra comunidad a mejorar el producto. Sólo se informan las llamadas API internas de BentoML. Esto excluye cualquier información confidencial, como código de usuario, datos de modelo, nombres de modelo o seguimientos de pila. Aquí está el código utilizado para el seguimiento del uso. Puede optar por no recibir seguimiento de uso mediante la opción CLI --do-not-track :
bentoml [command] --do-not-trackO configurando la variable de entorno:
export BENTOML_DO_NOT_TRACK=TrueLicencia Apache 2.0


