fastsag
1.0.0
Esta es una implementación de PyTorch/GPU del documento FastSAG de IJCAI 2024: hacia una generación rápida de acompañamiento de canto no autorregresivo. La página de demostración se puede encontrar en demo.
@article{chen2024fastsag,
title={FastSAG: Towards Fast Non-Autoregressive Singing Accompaniment Generation},
author={Chen, Jianyi and Xue, Wei and Tan, Xu and Ye, Zhen and Liu, Qifeng and Guo, Yike},
journal={arXiv preprint arXiv:2405.07682},
year={2024}
}Descarga este código:
git clone https://github.com/chenjianyi/fastsag/ cd fastsag
Descargue el punto de control fastsag desde aquí y coloque todos los pesos en fastsag/weights
Los puntos de control de BigvGAN se pueden descargar desde BigvGAN. Los puntos de control que utilizamos son "bigvgan_24khz_100band". Actualizo BigvGAN a BigvGAN-v2 y los puntos de control se descargarán automáticamente.
Los puntos de control previamente entrenados por MERT se descargarían automáticamente desde huggingface. Asegúrese de que su servidor pueda acceder a huggingface.
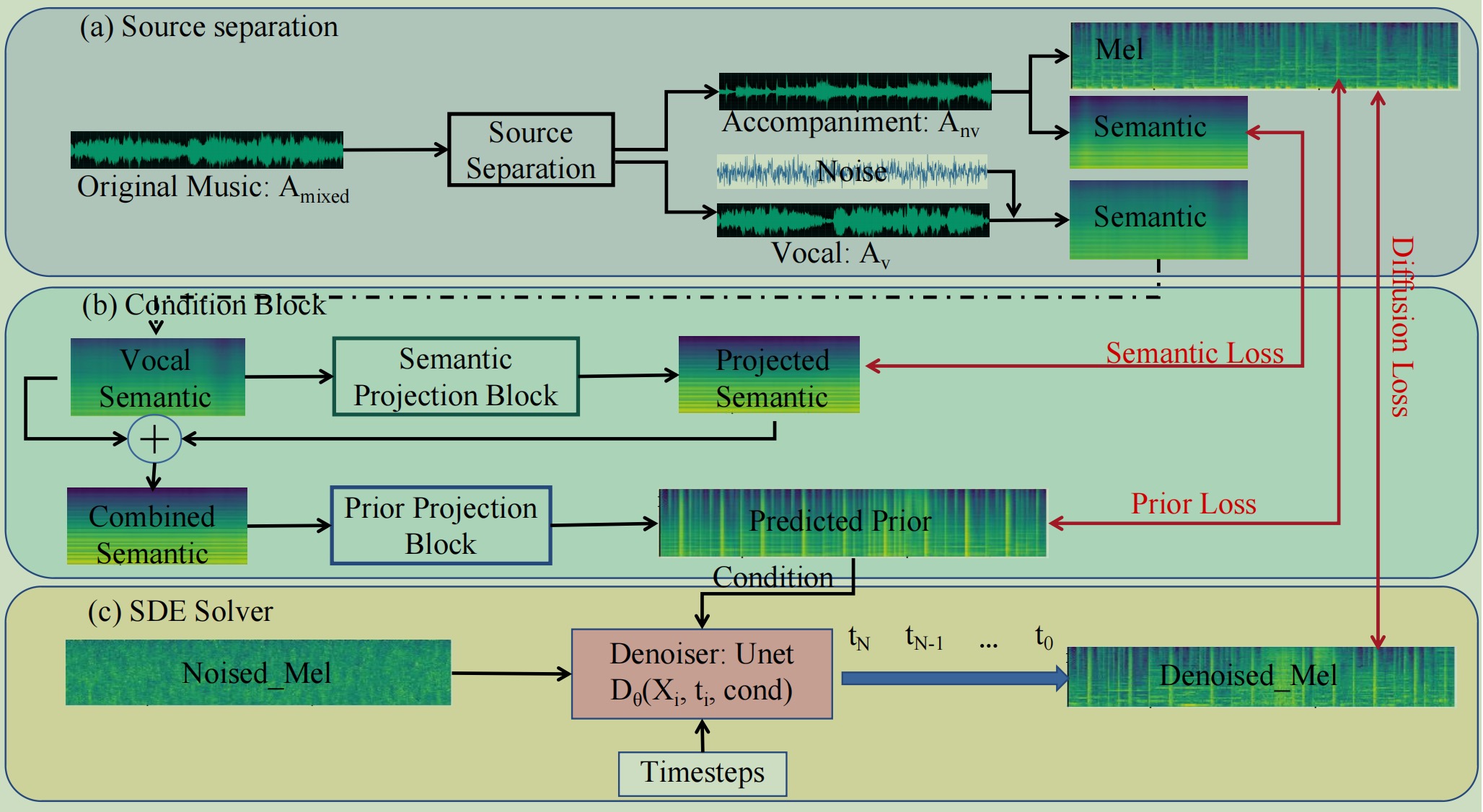
Separación de fuentes:
cd preprocessing python3 demucs_processing.py # you may need to change root_dir and out_dir in this file
Recorte a decenas y filtrado de clips destacados.
python3 clip_to_10s.py # change src_root and des_root for your dataset
cd ../sde_diffusion python3 train.py --data_dir YOUR_TRAIN_DATA --data_dir_testset YOUR_TEST_DATA --results_folder RESULTS
python3 generate.py --ckpt TRAINED_MODEL --data_dir DATA_DIR --result_dir OUTPUT
Graduado-TTS.
CoMoDiscurso


