Adding Private Data to LLMs
1.0.0
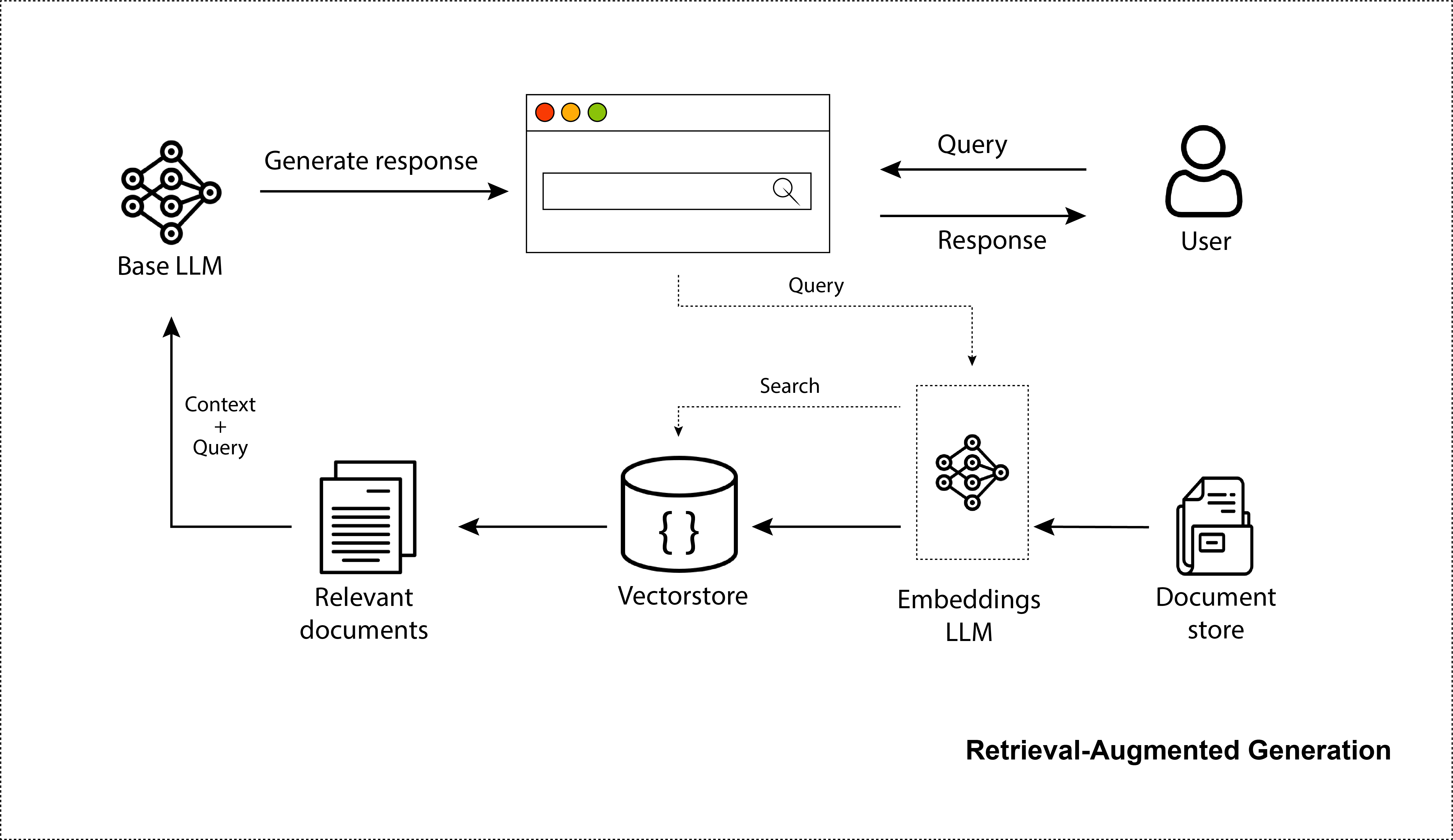
Los LLM han sorprendido al mundo con su capacidad para crear imágenes, códigos y diálogos realistas. Sin duda, ChatGPT ha conquistado el mundo. Millones lo están usando. Pero si bien es excelente para el conocimiento de propósito general, solo conoce la información con la que fue entrenado, que son datos de Internet disponibles generalmente antes de 2021. Carece de conocimiento de sus datos privados y permanece desinformado sobre las fuentes de datos recientes. Así, para mejorarlos en ese sentido, podemos proporcionarles información que recuperamos de un paso de búsqueda. Esto los hace más objetivos y les da una mejor capacidad para proporcionar al modelo información actualizada, sin la necesidad de volver a entrenar estos modelos masivos. Esto es precisamente lo que es un sistema LLM de recuperación aumentada o generación aumentada de recuperación (RAG). De hecho, este repositorio describirá con precisión la creación de un sistema RAG y aclarará los pasos de optimización involucrados.
TRAPO
Pila de tecnología
Instalación
Enlaces útiles
Contacto
LangChain
LlamaIndex
Azure abierto AI
Gradio
Clonar el repositorio de Github
clon de git https://github.com/zekaouinoureddine/Adding-Private-Data-to-LLMs.git
Requisitos CD al directorio del proyecto y asegúrese de tener Python 3 instalado, junto con las dependencias necesarias.
cd Agregar-datos-privados-a-LLM instalación de pip -r requisitos.txt
Ejecute la aplicación Gradio
trapo de Python.py
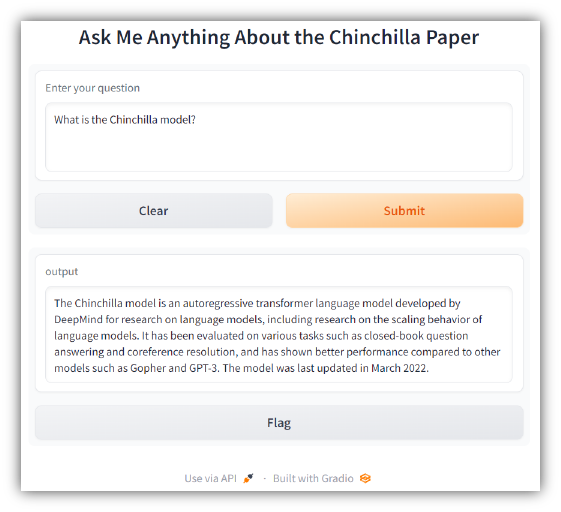
Visite http://127.0.0.1:7860 en su máquina para probar la aplicación. Deberías ver algo como lo siguiente:
| Blog | Plataforma | Idioma | Computadora portátil |
|---|---|---|---|
| Pregunte a sus propios datos | Blog Hiberus | ES | |
| Pregunte a sus propios datos | Medio | ES | |
| Pregunte a sus páginas web | Blog Hiberus | ES | |
| Pregunte a sus páginas web | Medio | ES |
Si te gusta dale un , luego sígueme en:
LinkedIn: Nour Eddine ZEKAOUI
Gorjeo: @NZekaoui
Volver a la cima


