QuillGPT
1.0.0

QuillGPT es una implementación del bloque decodificador GPT basada en la arquitectura del artículo Attention is All You Need de Vaswani et. Alabama. implementado en PyTorch. Además, este repositorio contiene dos modelos previamente entrenados (Shakespearean GPT y Harpoon GPT) junto con sus pesos entrenados. Para facilitar la experimentación y la implementación, se proporciona Streamlit Playground para la exploración interactiva de estos modelos y el microservicio FastAPI implementado con contenedorización Docker para una implementación escalable. También encontrará scripts de Python para entrenar nuevos modelos GPT y realizar inferencias sobre ellos, junto con cuadernos que muestran los modelos entrenados. Para facilitar la codificación y decodificación de texto, se implementa un tokenizador simple. ¡Explore QuillGPT para utilizar estas herramientas y mejorar sus proyectos de procesamiento del lenguaje natural!
Hay dos modelos y pesos previamente entrenados incluidos en este repositorio.
| Característica | GPT de Shakespeare | Arpón GPT |
|---|---|---|
| Parámetros | 10,7 millones | 226 millones |
| Pesos | Pesos | Pesos |
| Configuración del modelo | configuración | configuración |
| Datos de entrenamiento | Texto de obras de Shakespeare (input.txt) | Texto aleatorio de libros (corpus.txt) |
| Tipo de incrustación | Incrustaciones de personajes | Incrustaciones de personajes |
| Cuaderno de entrenamiento | Computadora portátil | Computadora portátil |
| Hardware | Nvidia T4 | Nvidia A100 |
| Pérdida de capacitación y validación | 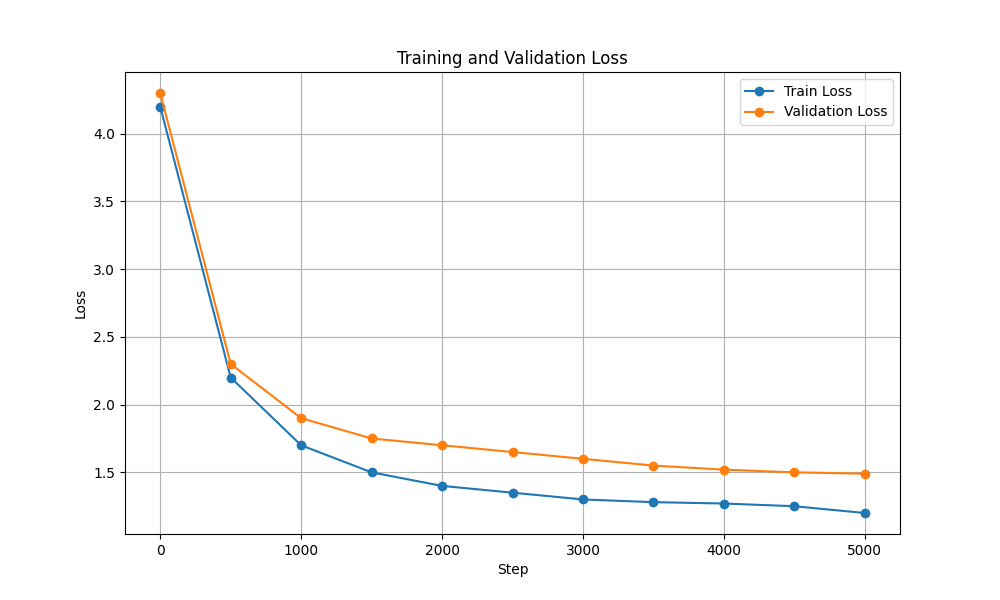 | 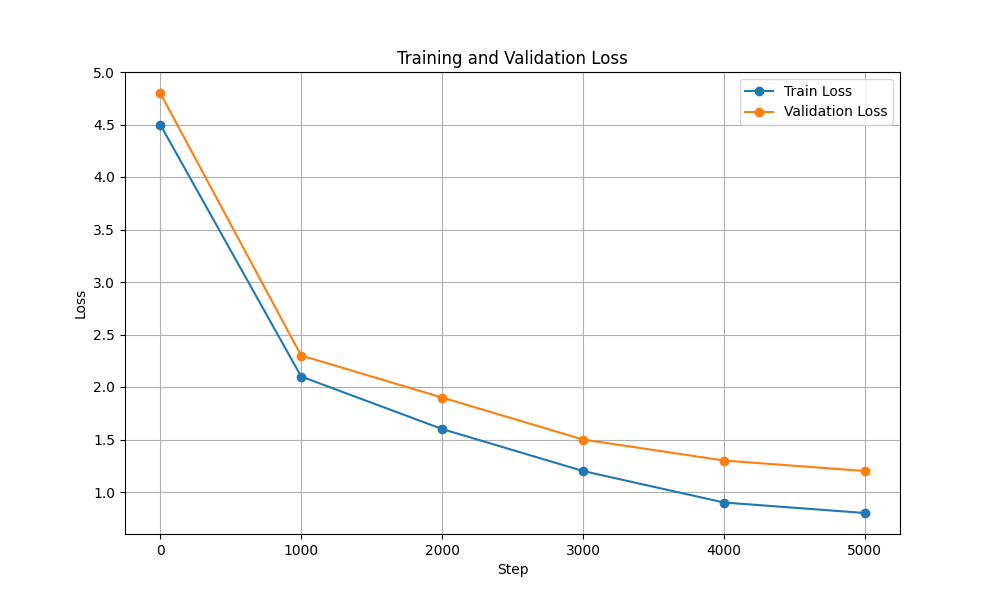 |
Para ejecutar los scripts de entrenamiento e inferencia, siga estos pasos:
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txt¡Asegúrate de descargar los pesos para Harpoon GPT desde aquí antes de continuar!
Está alojado en Streamlit Cloud Service. Puedes visitarlo a través del enlace aquí.
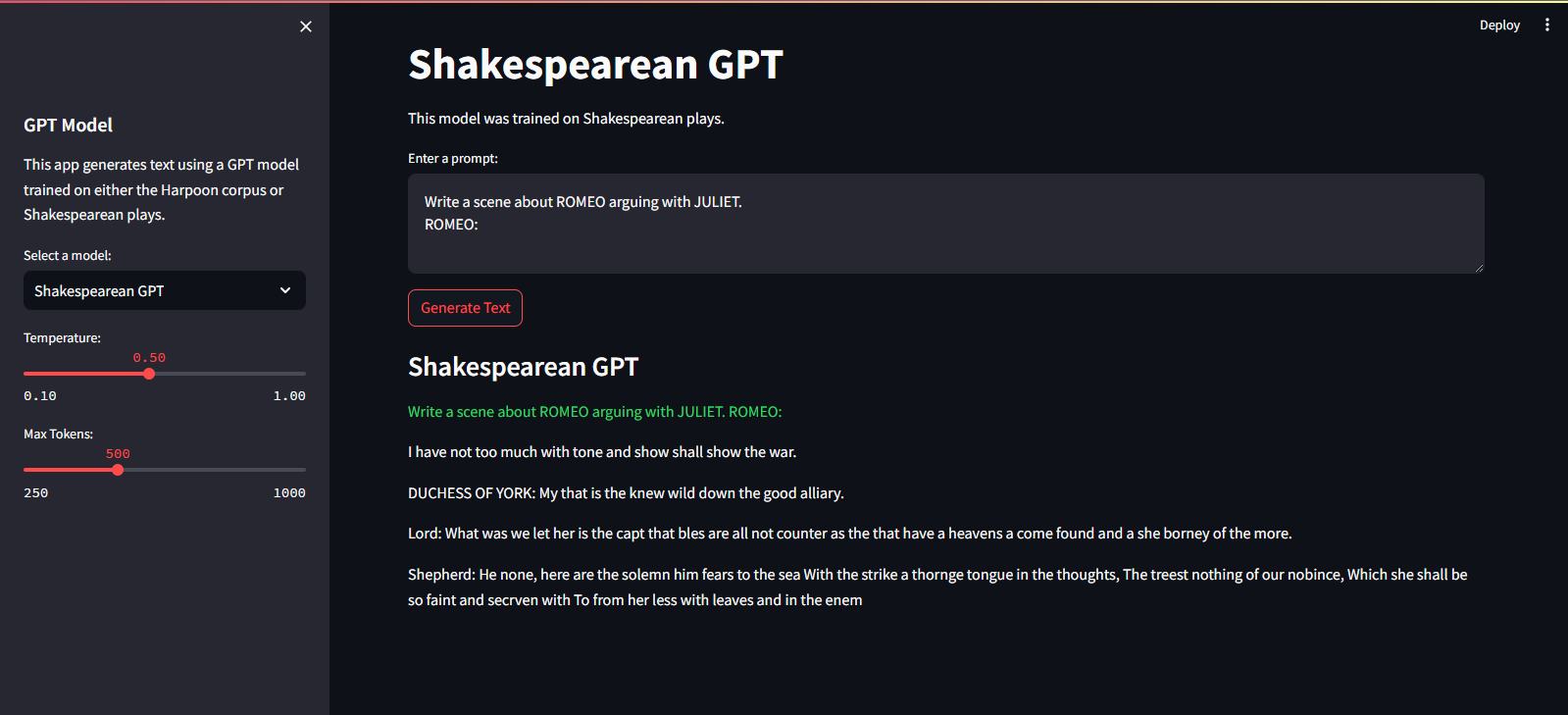
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devPara entrenar el modelo GPT, siga estos pasos:
Preparar datos. Coloque todos los datos de texto en un solo archivo .txt y guárdelo.
Escriba las configuraciones para el transformador y guarde el archivo.
Por ejemplo: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
Entrene el modelo usando scripts/train_gpt.py
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (Puede cambiar config_path , data_path y output_dir según sus requisitos).
output_dir especificado en el comando.Después del entrenamiento, puede utilizar el modelo GPT entrenado para generar texto. A continuación se muestra un ejemplo del uso del modelo entrenado para la inferencia:
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 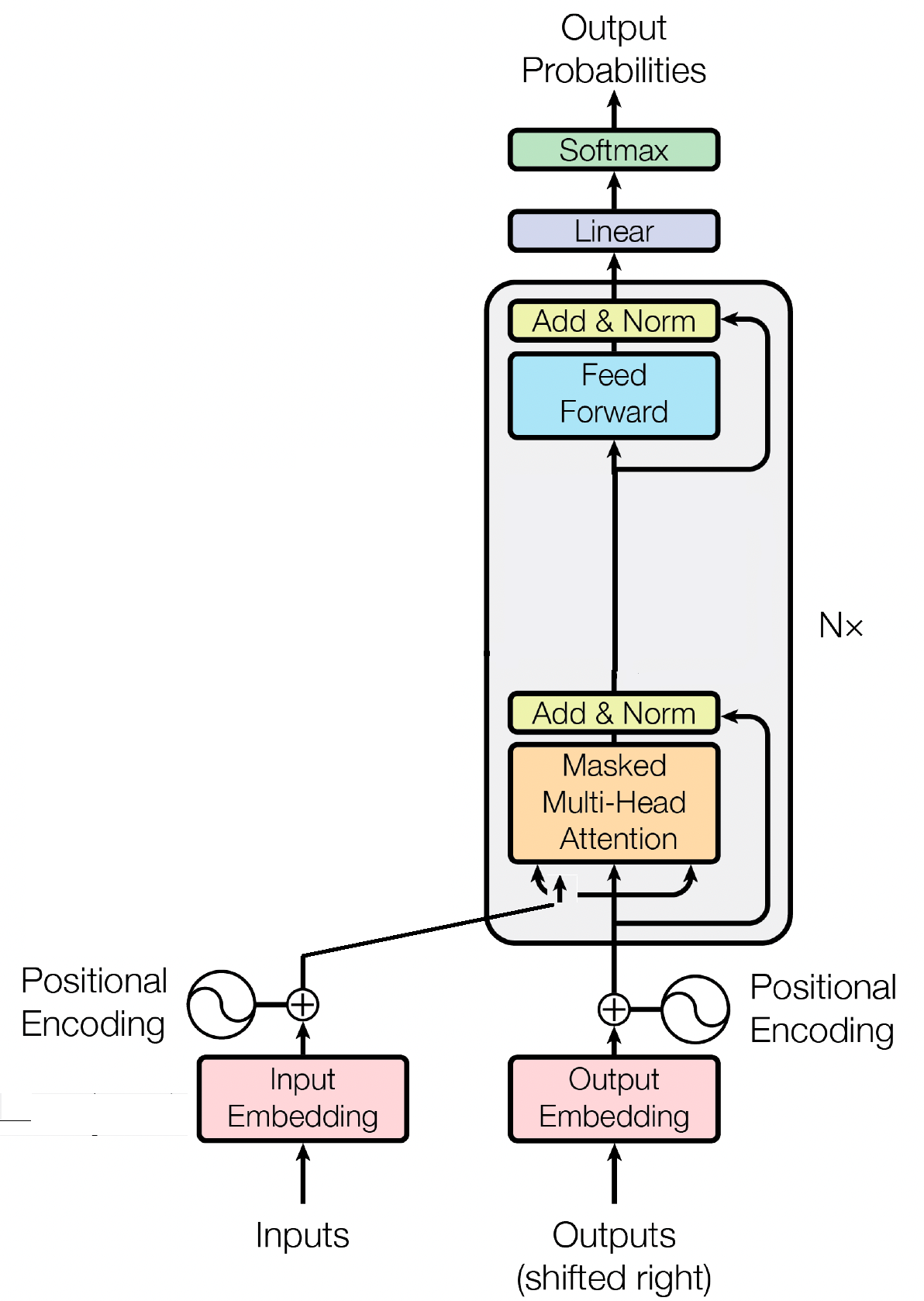
El bloque decodificador es un componente crucial del modelo GPT (Transformador generativo preentrenado), es donde GPT realmente genera el texto. Aprovecha el mecanismo de autoatención para procesar secuencias de entrada y generar resultados coherentes. Cada bloque decodificador consta de varias capas, incluidas capas de autoatención, redes neuronales de retroalimentación y normalización de capas. Las capas de autoatención permiten al modelo sopesar la importancia de diferentes palabras en una secuencia, capturando el contexto y las dependencias independientemente de sus posiciones. Esto permite que el modelo GPT genere texto contextualmente relevante.
Las incorporaciones de entrada desempeñan un papel crucial en modelos basados en transformadores como GPT al transformar tokens de entrada en representaciones numéricas significativas. Estas incrustaciones sirven como entrada inicial para el modelo, capturando información semántica sobre las palabras en la secuencia. El proceso implica mapear cada token en la secuencia de entrada a un espacio vectorial de alta dimensión, donde tokens similares se colocan más cerca unos de otros. Esto permite que el modelo comprenda las relaciones entre diferentes palabras y aprenda eficazmente de los datos de entrada. Las incrustaciones de entrada luego se introducen en las capas posteriores del modelo para su posterior procesamiento.
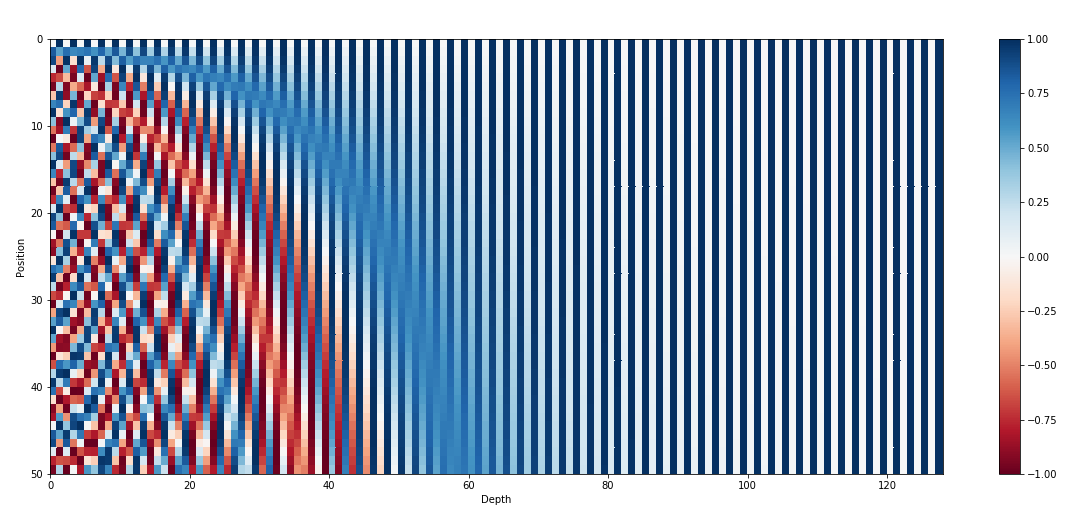
Además de las incorporaciones de entrada, las incorporaciones posicionales son otro componente vital de las arquitecturas de transformadores como GPT. Dado que los transformadores carecen de información inherente sobre el orden de los tokens en una secuencia, se introducen incorporaciones posicionales para proporcionar información posicional al modelo. Estas incrustaciones codifican la posición de cada token dentro de la secuencia, lo que permite que el modelo distinga entre tokens según sus posiciones. Al incorporar incrustaciones posicionales, los transformadores como GPT pueden capturar de manera efectiva la naturaleza secuencial de los datos y generar resultados coherentes que mantengan el orden correcto de las palabras en el texto generado.

La autoatención, un mecanismo fundamental en modelos basados en transformadores como GPT, opera asignando puntuaciones de importancia a diferentes palabras en una secuencia. Este proceso implica tres pasos clave: calcular puntuaciones de atención, aplicar softmax para obtener ponderaciones de atención y, finalmente, combinar estas ponderaciones con las incrustaciones de entrada para generar representaciones informadas contextualmente. En esencia, la autoatención permite que el modelo se centre más en palabras relevantes y reste importancia a las menos importantes, lo que facilita el aprendizaje eficaz de las dependencias contextuales dentro de los datos de entrada. Este mecanismo es fundamental para capturar dependencias de largo alcance y matices contextuales, lo que permite que los modelos de transformadores generen largas secuencias de texto.
MIT © Shrirang Mahajan
¡No dudes en enviar solicitudes de extracción, crear problemas o correr la voz!
¡Apóyame simplemente destacando este repositorio!


