marqo ecommerce embeddings
1.0.0
En este trabajo, presentamos dos modelos de integración de última generación para productos de comercio electrónico: Marqo-Ecommerce-B y Marqo-Ecommerce-L.
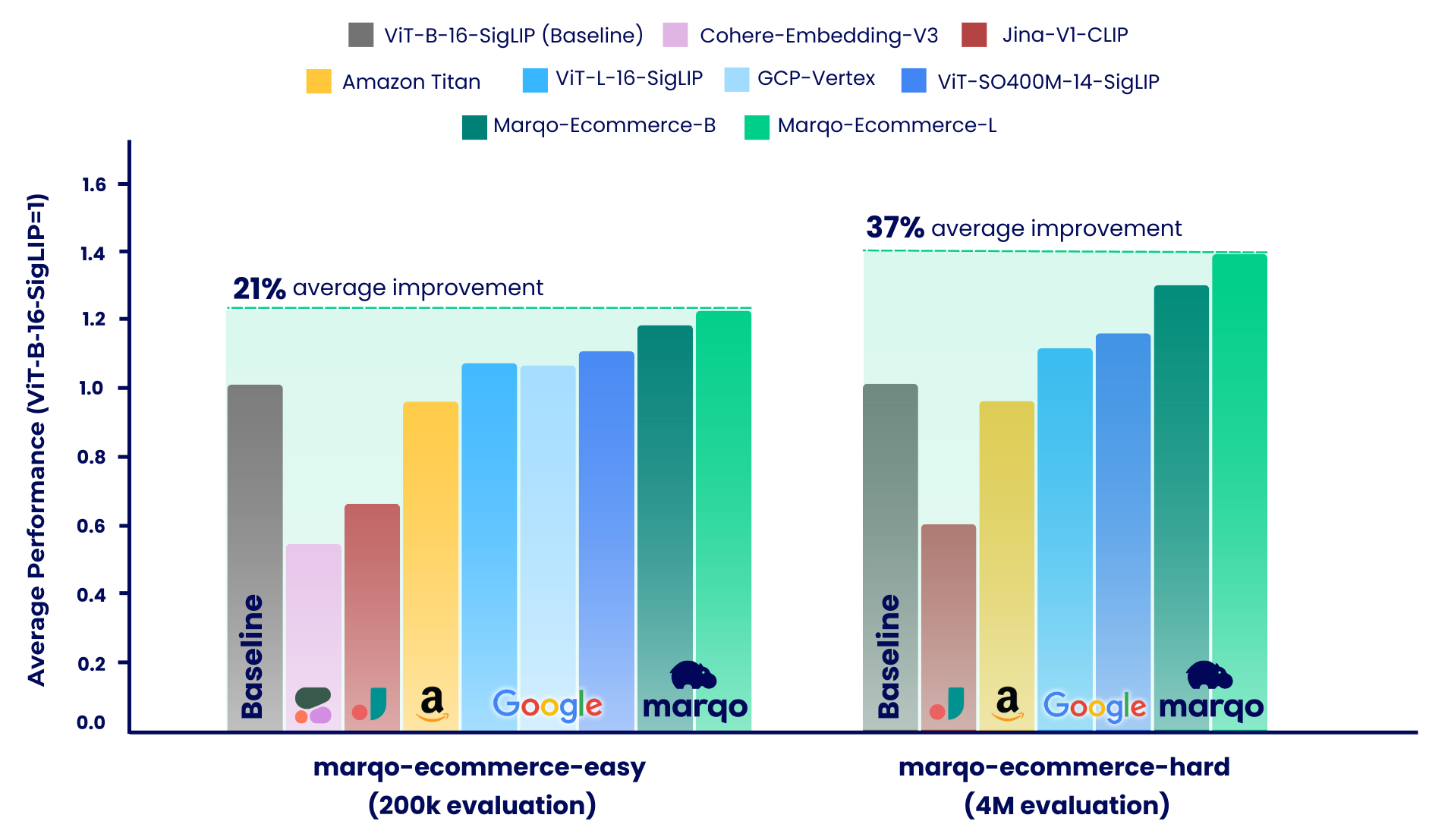
Los resultados de la evaluación comparativa muestran que los modelos Marqo-Ecommerce superaron consistentemente a todos los demás modelos en varias métricas. Específicamente, marqo-ecommerce-L logró una mejora promedio del 17,6% en MRR y del 20,5% en nDCG@10 en comparación con el mejor modelo de código abierto actual, ViT-SO400M-14-SigLIP en las tres tareas de marqo-ecommerce-hard conjunto de datos marqo-ecommerce-hard . En comparación con el mejor modelo privado, Amazon-Titan-Multimodal , vimos una mejora promedio del 38,9 % en MRR y del 45,1 % en nDCG@10 en las tres tareas, y del 35,9 % en recuperación en las tareas de texto a imagen en el conjunto de datos marqo-ecommerce-hard .
A continuación se pueden encontrar más resultados de evaluación comparativa.
Contenido publicado :
| Modelo de incrustación | #Parámetros (m) | Dimensión | AbrazosCara | Descargar .pt | Inferencia de texto por lote único (A10g) | Inferencia de imágenes de un solo lote (A10g) |
|---|---|---|---|---|---|---|
| Marqo-Ecommerce-B | 203 | 768 | Marqo/marqo-ecommerce-integraciones-B | enlace | 5,1 ms | 5,7 ms |
| Marqo-Ecommerce-L | 652 | 1024 | Marqo/marqo-ecommerce-integraciones-L | enlace | 10,3 ms | 11,0 ms |
Para cargar los modelos en OpenCLIP, consulte a continuación. Los modelos se alojan en Hugging Face y se cargan mediante OpenCLIP. También puedes encontrar este código dentro de run_models.py .
pip install open_clip_torch
from PIL import Image
import open_clip
import requests
import torch
# Specify model from Hugging Face Hub
model_name = 'hf-hub:Marqo/marqo-ecommerce-embeddings-L'
model , preprocess_train , preprocess_val = open_clip . create_model_and_transforms ( model_name )
tokenizer = open_clip . get_tokenizer ( model_name )
# Preprocess the image and tokenize text inputs
# Load an example image from a URL
img = Image . open ( requests . get ( 'https://raw.githubusercontent.com/marqo-ai/marqo-ecommerce-embeddings/refs/heads/main/images/dining-chairs.png' , stream = True ). raw )
image = preprocess_val ( img ). unsqueeze ( 0 )
text = tokenizer ([ "dining chairs" , "a laptop" , "toothbrushes" ])
# Perform inference
with torch . no_grad (), torch . cuda . amp . autocast ():
image_features = model . encode_image ( image , normalize = True )
text_features = model . encode_text ( text , normalize = True )
# Calculate similarity probabilities
text_probs = ( 100.0 * image_features @ text_features . T ). softmax ( dim = - 1 )
# Display the label probabilities
print ( "Label probs:" , text_probs )
# [1.0000e+00, 8.3131e-12, 5.2173e-12]Para cargar los modelos en Transformers, consulte a continuación. Los modelos están alojados en Hugging Face y cargados mediante Transformers.
from transformers import AutoModel , AutoProcessor
import torch
from PIL import Image
import requests
model_name = 'Marqo/marqo-ecommerce-embeddings-L'
# model_name = 'Marqo/marqo-ecommerce-embeddings-B'
model = AutoModel . from_pretrained ( model_name , trust_remote_code = True )
processor = AutoProcessor . from_pretrained ( model_name , trust_remote_code = True )
img = Image . open ( requests . get ( 'https://raw.githubusercontent.com/marqo-ai/marqo-ecommerce-embeddings/refs/heads/main/images/dining-chairs.png' , stream = True ). raw ). convert ( "RGB" )
image = [ img ]
text = [ "dining chairs" , "a laptop" , "toothbrushes" ]
processed = processor ( text = text , images = image , padding = 'max_length' , return_tensors = "pt" )
processor . image_processor . do_rescale = False
with torch . no_grad ():
image_features = model . get_image_features ( processed [ 'pixel_values' ], normalize = True )
text_features = model . get_text_features ( processed [ 'input_ids' ], normalize = True )
text_probs = ( 100 * image_features @ text_features . T ). softmax ( dim = - 1 )
print ( text_probs )
# [1.0000e+00, 8.3131e-12, 5.2173e-12] Para la evaluación se utiliza el Aprendizaje Contrastivo Generalizado (GCL). El siguiente código también se puede encontrar en scripts .
git clone https://github.com/marqo-ai/GCL
Instale los paquetes requeridos por GCL.
1. Recuperación de imágenes de GoogleShopping-Text2.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/gs-title2image
mkdir -p $outdir
hfdataset=Marqo/google-shopping-general-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['title']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
2. Recuperación de imágenes de GoogleShopping-Categoría2.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/gs-cat2image
mkdir -p $outdir
hfdataset=Marqo/google-shopping-general-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['query']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
3. Recuperación de imágenes de AmazonProducts-Category2.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/ap-title2image
mkdir -p $outdir
hfdataset=Marqo/amazon-products-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['title']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
Nuestro proceso de evaluación comparativa se dividió en dos regímenes distintos, cada uno de los cuales utilizó diferentes conjuntos de datos de listados de productos de comercio electrónico: marqo-ecommerce-hard y marqo-ecommerce-easy. Ambos conjuntos de datos contenían imágenes y texto de productos y solo diferían en tamaño. El conjunto de datos "fácil" es aproximadamente entre 10 y 30 veces más pequeño (200 000 frente a 4 millones de productos) y está diseñado para adaptarse a modelos de velocidad limitada, específicamente Cohere-Embeddings-v3 y GCP-Vertex (con límites de 0,66 rps y 2 rps respectivamente). El conjunto de datos "duros" representa el verdadero desafío, ya que contiene cuatro millones de listados de productos de comercio electrónico y es más representativo de escenarios de búsqueda de comercio electrónico del mundo real.
Dentro de ambos escenarios, los modelos se compararon con tres tareas diferentes:
Marqo-Ecommerce-Hard analiza la evaluación integral realizada utilizando el conjunto completo de 4 millones de datos, destacando el sólido desempeño de nuestros modelos en un contexto del mundo real.
Recuperación de imágenes de GoogleShopping-Text2.
| Modelo de incrustación | mapa | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,682 | 0,878 | 0,683 | 0,726 |
| Marqo-Ecommerce-B | 0.623 | 0.832 | 0,624 | 0,668 |
| ViT-SO400M-14-SigLip | 0.573 | 0.763 | 0.574 | 0.613 |
| ViT-L-16-SigLip | 0.540 | 0,722 | 0.540 | 0,577 |
| ViT-B-16-SigLip | 0,476 | 0.660 | 0,477 | 0.513 |
| Amazon-Titan-MultiModal | 0,475 | 0,648 | 0,475 | 0.509 |
| Jina-V1-CLIP | 0,285 | 0.402 | 0,285 | 0.306 |
Recuperación de imágenes de GoogleShopping-Category2.
| Modelo de incrustación | mapa | p@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0.463 | 0,652 | 0.822 | 0,666 |
| Marqo-Ecommerce-B | 0.423 | 0,629 | 0.810 | 0,644 |
| ViT-SO400M-14-SigLip | 0.352 | 0.516 | 0.707 | 0.529 |
| ViT-L-16-SigLip | 0.324 | 0,497 | 0,687 | 0.509 |
| ViT-B-16-SigLip | 0,277 | 0,458 | 0.660 | 0.473 |
| Amazon-Titan-MultiModal | 0.246 | 0,429 | 0,642 | 0.446 |
| Jina-V1-CLIP | 0,123 | 0.275 | 0.504 | 0,294 |
AmazonProducts-Text2Recuperación de imágenes.
| Modelo de incrustación | mapa | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,658 | 0,854 | 0.663 | 0.703 |
| Marqo-Ecommerce-B | 0,592 | 0,795 | 0,597 | 0,637 |
| ViT-SO400M-14-SigLip | 0.560 | 0,742 | 0.564 | 0,599 |
| ViT-L-16-SigLip | 0.544 | 0,715 | 0.548 | 0.580 |
| ViT-B-16-SigLip | 0.480 | 0.650 | 0,484 | 0.515 |
| Amazon-Titan-MultiModal | 0.456 | 0,627 | 0,457 | 0,491 |
| Jina-V1-CLIP | 0.265 | 0,378 | 0.266 | 0,285 |
Como se mencionó, nuestro proceso de evaluación comparativa se dividió en dos escenarios distintos: marqo-ecommerce-hard y marqo-ecommerce-easy. Esta sección cubre este último, que presenta un corpus entre 10 y 30 veces más pequeño y fue diseñado para adaptarse a modelos de velocidad limitada. Analizaremos la evaluación integral realizada utilizando los 200.000 productos completos en los dos conjuntos de datos. Además de los modelos ya evaluados anteriormente, estos puntos de referencia también incluyen Cohere-embedding-v3 y GCP-Vertex.
Recuperación de imágenes de GoogleShopping-Text2.
| Modelo de incrustación | mapa | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,879 | 0.971 | 0,879 | 0.901 |
| Marqo-Ecommerce-B | 0,842 | 0.961 | 0.842 | 0,871 |
| ViT-SO400M-14-SigLip | 0,792 | 0.935 | 0,792 | 0,825 |
| GCP-Vértice | 0.740 | 0.910 | 0.740 | 0,779 |
| ViT-L-16-SigLip | 0,754 | 0.907 | 0,754 | 0,789 |
| ViT-B-16-SigLip | 0.701 | 0.870 | 0.701 | 0,739 |
| Amazon-Titan-MultiModal | 0,694 | 0,868 | 0,693 | 0.733 |
| Jina-V1-CLIP | 0.480 | 0,638 | 0.480 | 0.511 |
| Cohere-incrustación-v3 | 0.358 | 0.515 | 0.358 | 0,389 |
Recuperación de imágenes de GoogleShopping-Category2.
| Modelo de incrustación | mapa | p@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0.515 | 0.358 | 0,764 | 0.590 |
| Marqo-Ecommerce-B | 0,479 | 0.336 | 0.744 | 0.558 |
| ViT-SO400M-14-SigLip | 0.423 | 0.302 | 0,644 | 0,487 |
| GCP-Vértice | 0.417 | 0,298 | 0,636 | 0.481 |
| ViT-L-16-SigLip | 0,392 | 0.281 | 0,627 | 0,458 |
| ViT-B-16-SigLip | 0.347 | 0.252 | 0.594 | 0.414 |
| Amazon-Titan-MultiModal | 0.308 | 0.231 | 0.558 | 0,377 |
| Jina-V1-CLIP | 0,175 | 0,122 | 0.369 | 0.229 |
| Cohere-incrustación-v3 | 0,136 | 0.110 | 0.315 | 0,178 |
AmazonProducts-Text2Recuperación de imágenes.
| Modelo de incrustación | mapa | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,92 | 0.978 | 0.928 | 0.940 |
| Marqo-Ecommerce-B | 0,897 | 0.967 | 0,897 | 0.914 |
| ViT-SO400M-14-SigLip | 0.860 | 0.954 | 0.860 | 0,882 |
| ViT-L-16-SigLip | 0.842 | 0.940 | 0.842 | 0.865 |
| GCP-Vértice | 0.808 | 0.933 | 0.808 | 0,837 |
| ViT-B-16-SigLip | 0,797 | 0.917 | 0,797 | 0,825 |
| Amazon-Titan-MultiModal | 0,762 | 0,889 | 0.763 | 0,791 |
| Jina-V1-CLIP | 0.530 | 0,699 | 0.530 | 0.565 |
| Cohere-incrustación-v3 | 0.433 | 0,597 | 0.433 | 0.465 |
@software{zhu2024marqoecommembed_2024,
author = {Tianyu Zhu and and Jesse Clark},
month = oct,
title = {{Marqo Ecommerce Embeddings - Foundation Model for Product Embeddings}},
url = {https://github.com/marqo-ai/marqo-ecommerce-embeddings/},
version = {1.0.0},
year = {2024}
}


