VideoMambaPro
1.0.0
Implementación oficial de VideoMambaPro: un salto adelante para Mamba en la comprensión del vídeo 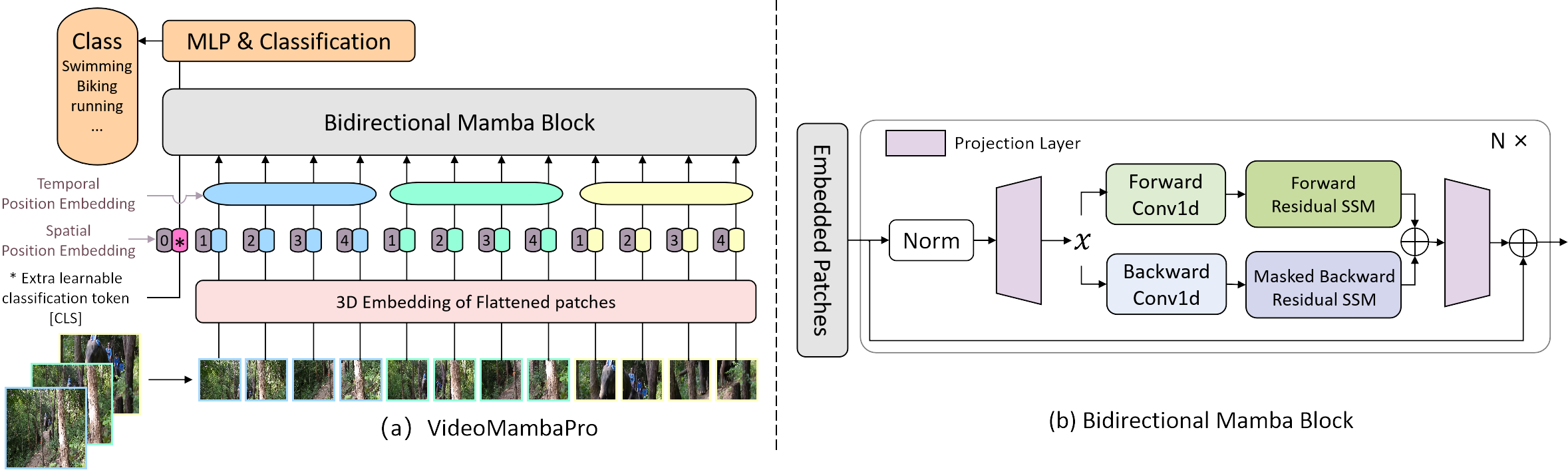
Investigamos similitudes y diferencias entre la autoatención y Mamba desde la perspectiva de este último, y revelamos las limitaciones de Mamba en la tarea de comprensión de videos. Proponemos VideoMambaPro que utiliza VideoMamba como columna vertebral, pero mejora significativamente el rendimiento en la tarea de comprensión del vídeo, reduciendo la brecha con los transformadores.
Los paquetes requeridos están en el archivo requirements.txt y puede ejecutar el siguiente comando para instalar el entorno
conda create -n videomambapro python=3.10
conda activate videomambapro
conda install cudatoolkit==11.8 -c nvidia
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
conda install -c "nvidia/label/cuda-11.8.0" cuda-nvcc
conda install packaging
pip install causal_conv1d==1.4.0 (we recommend to install through .whl file)
pip install mamba-ssm
pip install -r requirements.txt
Leemos y procesamos de la misma manera que VideoMAE, pero con una convención diferente para el formato del archivo de lista de datos.
Preentrenamos el modelo en el conjunto de datos ImageNet-1K, donde el modelo carga un archivo de lista de datos con el siguiente formato:
frame_folder_path etiqueta total_frames
Hay dos implementaciones de nuestro conjunto de datos de ajuste VideoClsDataset y RawFrameClsDataset , que admiten datos de video y datos de fotogramas sin formato, respectivamente. Donde SSV2 usa RawFrameClsDataset de forma predeterminada y el resto de conjuntos de datos usan VideoClsDataset .
VideoClsDataset carga un archivo de lista de datos con el siguiente formato:
etiqueta de ruta_video
mientras que RawFrameClsDataset carga un archivo de lista de datos con el siguiente formato:
frame_folder_path etiqueta total_frames
Por ejemplo, la lista de datos de vídeo y la lista de datos de fotogramas sin formato se muestran a continuación:
# The path prefix 'your_path' can be specified by `--data_root ${PATH_PREFIX}` in scripts when training or inferencing.
# k400 video data validation list
your_path/k400/jf7RDuUTrsQ.mp4 325
your_path/k400/JTlatknwOrY.mp4 233
your_path/k400/NUG7kwJ-614.mp4 103
your_path/k400/y9r115bgfNk.mp4 320
your_path/k400/ZnIDviwA8CE.mp4 244
...
# ssv2 rawframes data validation list
your_path/SomethingV2/frames/74225 62 140
your_path/SomethingV2/frames/116154 51 127
your_path/SomethingV2/frames/198186 47 173
your_path/SomethingV2/frames/137878 29 99
your_path/SomethingV2/frames/151151 31 166
...
Nuestro proyecto se basa en VideoMamba para una comparación justa. Para resolver las limitaciones 1 y 2 en nuestro artículo, cambiamos principalmente la tubería de Mamba aplicando la máscara diagonal durante el SSM hacia atrás y aplicando una conexión residual en el SSM bidireccional. La conexión residual de Ab se realiza en la función selective_scan_ref en mamba/mamba_ssm/ops/selective_scan_interface.py, y la opción clave se encuentra a continuación:
x = u[:, :, 0].unsqueeze(-1).expand(-1, -1, dstate)
x = deltaA[:, :, i] * x + deltaB_u[:, :, i]
La asignación de máscara se realiza mediante la configuración de dos funciones selectivas, a saber, selectiva_scan_ref y selectiva_scan_ref_sub en mamba/mamba_ssm/ops/selective_scan_interface.py. Al calcular la mamba bidireccional, por ejemplo, en bimamba_inner_ref de mamba/mamba_ssm/ops/selective_scan_interface.py, el código clave se encuentra a continuación:
y = selective_scan_fn(x, delta, A, B, C, D, z=z, delta_bias=delta_bias, delta_softplus=True)
y_b = selective_scan_ref_sub(x.flip([-1]), delta.flip([-1]), A_b, B.flip([-1]), C.flip([-1]), D, z.flip([-1]), delta_bias, delta_softplus=True)
y = y + y_b.flip([-1])
Título: https://pan.baidu.com/s/1vJN_XTRct65cDA_0AB259g?pwd=ghqb Texto: ghqb


