Mientras exploraba la criptografía encontré un vídeo de Khan Academy que despertó mi interés en los defectos del infame cifrado de César.
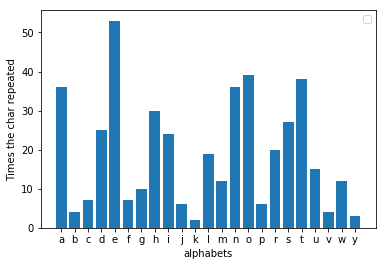
Cada vez que escribes una carta larga o un correo electrónico en inglés, sin querer dejas una huella digital; Si escanea un mensaje que ha escrito y cuenta la frecuencia de cada letra, encontrará un patrón bastante consistente. Lo más probable es que la 'e' sea la letra más recurrente en todo el mensaje. Tomé una fábula aleatoria de Internet para probar esto y el resultado que obtuve fue el que se esperaba de ella. La 'e' era de hecho la letra más popular. Este hecho es válido para cualquier mensaje que sea lo suficientemente largo.
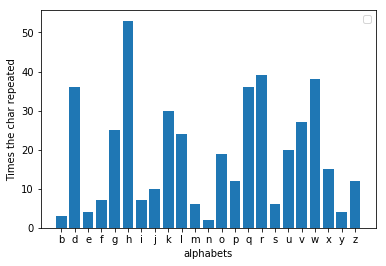
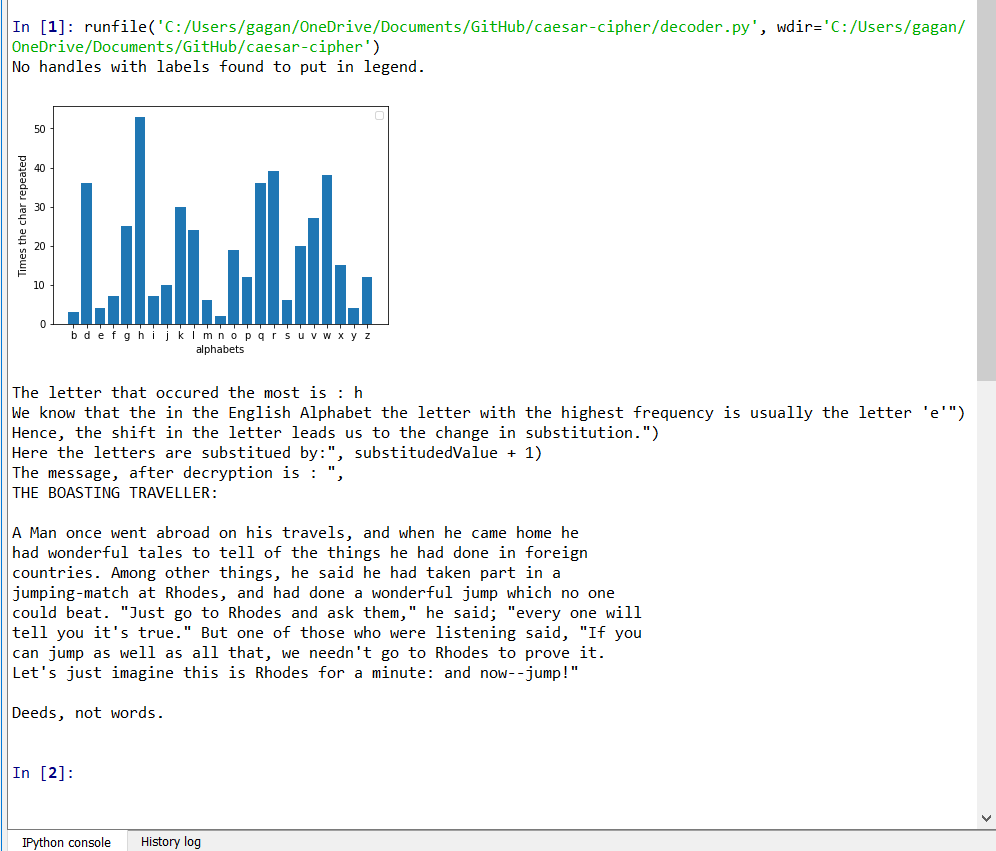
El error que encontró Al-kindi fue que, cuando se analiza la frecuencia del mensaje cifrado, ahora aparece con mayor frecuencia una letra diferente. Si compruebas qué tan lejos se desplaza la letra del tres, podrás encontrar el valor por el que se sustituye el mensaje. Por ejemplo, si 'h' es la letra más popular en el mensaje cifrado, entonces el cambio probablemente fue tres. Ahora, al revertir el cambio, podríamos captar fácilmente el mensaje original. En decoder.py cuando le proporciona un archivo cifrado, descifra el mensaje y lo imprime. Cifré la misma fábula cambiando los alfabetos tres letras y resulta que la 'h' es de hecho la letra más popular aquí.
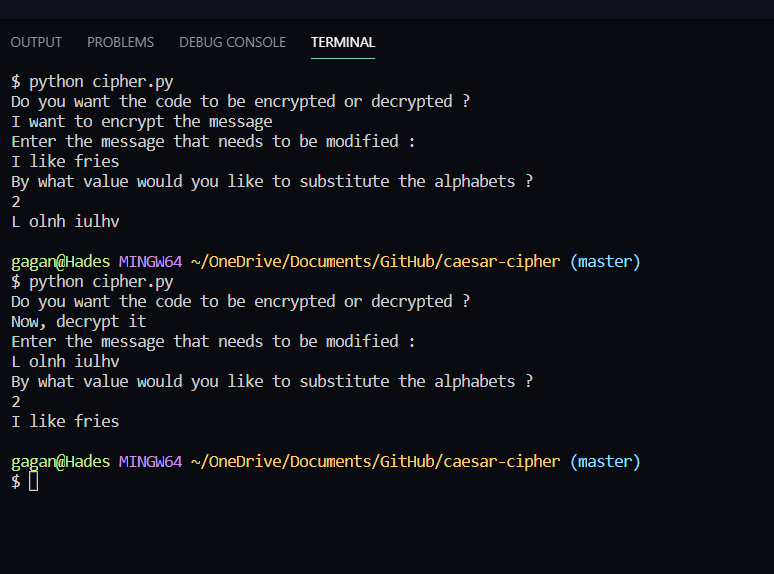
Para reproducir los resultados de mi cifrado y explorarlo con otros mensajes, además de Python debes tener instalado matplotlib.
pip install matplotlibRecuerde : el decodificador funciona según el principio de la lingüística y la estadística, por lo que cuanto más largo sea el mensaje, más preciso será el resultado.
Gagan Devagiri © MIT


