Esta guía lo ayudará a ensamblar y probar una versión preliminar para desarrolladores del producto RHEL AI.
¡Bienvenido a la vista previa para desarrolladores de IA de Red Hat Enterprise Linux! Esta guía está destinada a presentarle las capacidades de RHEL AI Developer Preview. Al igual que con otras vistas previas para desarrolladores, espere cambios en estos flujos de trabajo, automatización y simplificación adicionales, así como una ampliación de capacidades, versiones de soporte de hardware y software, mejoras de rendimiento (y otras optimizaciones) antes de GA.
RHEL AI es un producto de código abierto que incluye:
Nota
RHEL AI está dirigido a plataformas de servidores y estaciones de trabajo con GPU discretas. Para computadoras portátiles, utilice InstructLab ascendente.
Aquí hay una lista de servidores validados por los ingenieros de Red Hat para funcionar con RHEL AI Developer Preview. Anticipamos que los sistemas recientes certificados para ejecutar RHEL 9, con GPU de centro de datos recientes, como las que se enumeran a continuación, funcionarán con esta versión preliminar para desarrolladores.
| Proveedor/especificaciones de GPU | Vista previa para desarrolladores de IA de RHEL |
|---|---|
| Dell (4) NVIDIA H100 | Sí |
Instancias IBM GX3 | Sí |
| Lenovo (8) AMD MI300x | Sí |
| Instancias AWS p4 y p5 (NVIDIA) | En curso |
| Intel | En curso |
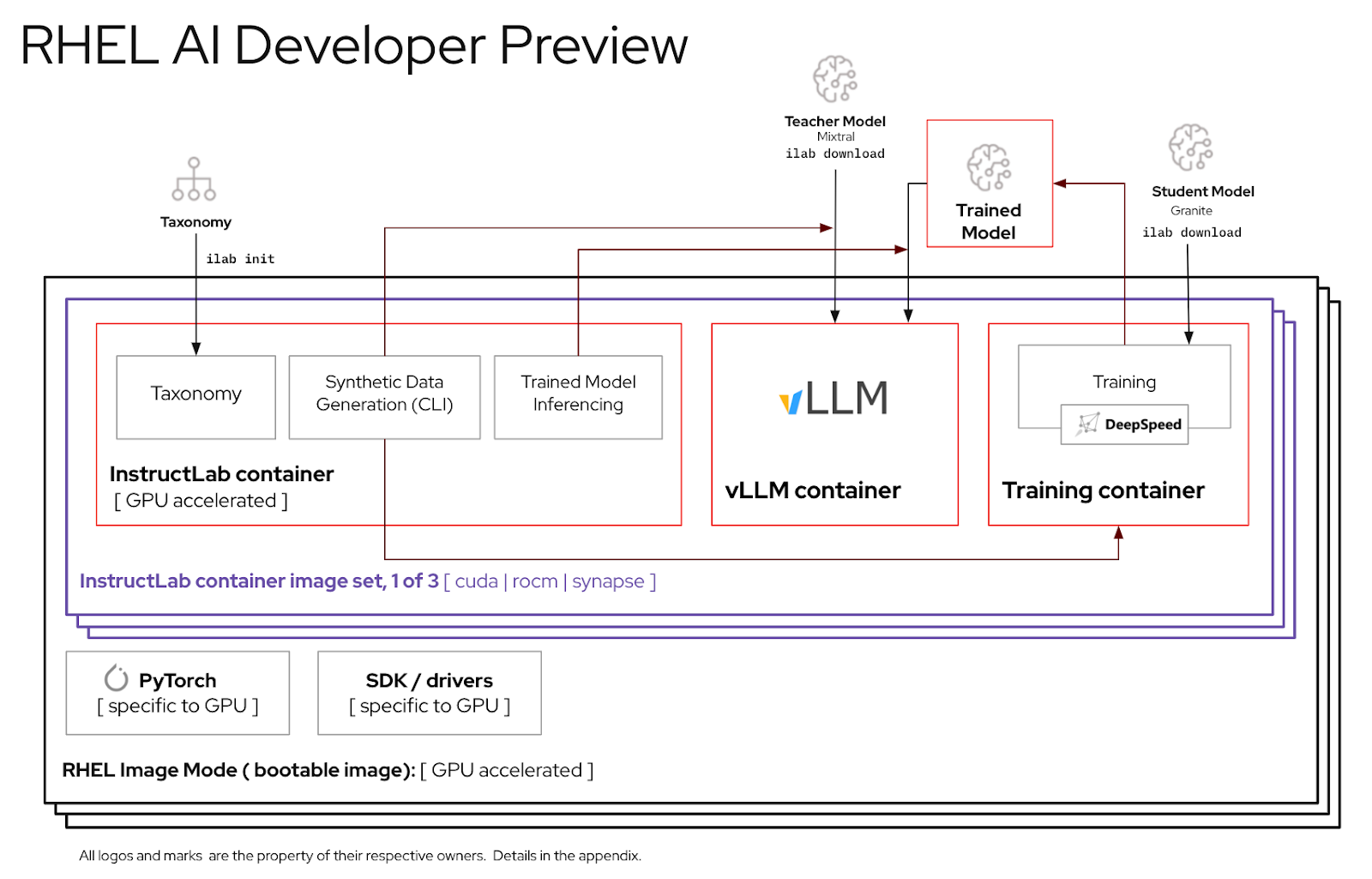
Para obtener la mejor experiencia al utilizar el período de vista previa para desarrolladores de RHEL AI, hemos incluido un árbol de taxonomía podado dentro del contenedor de InstructLab. Esto permitirá validar la capacitación para completarla en un período de tiempo razonable en un solo servidor.
Fórmula: una sola GPU puede entrenar ~250 muestras por minuto. Si tiene 8 GPU y 10 000 muestras, espere que tarde
Al final de este ejercicio, tendrás:
bootc es un sistema operativo transaccional local que aprovisiona y actualiza utilizando imágenes de contenedor OCI/Docker. bootc es el componente clave en una misión más amplia de contenedores de arranque.
El modelo de contenedor Docker original que utiliza "capas" para modelar aplicaciones ha tenido un gran éxito. Este proyecto tiene como objetivo aplicar la misma técnica para sistemas host de arranque: utilizando contenedores OCI/Docker estándar como formato de transporte y entrega para actualizaciones del sistema operativo base.
La imagen del contenedor incluye un kernel de Linux (por ejemplo, /usr/lib/modules ), que se utiliza para arrancar. En tiempo de ejecución en un sistema de destino, el espacio de usuario base no se ejecuta en un contenedor de forma predeterminada. Por ejemplo, suponiendo que systemd esté en uso, systemd actúa como pid1 como de costumbre; no hay ningún proceso "externo".
En el siguiente ejemplo, el contenedor bootc tiene la etiqueta Node Base Image :
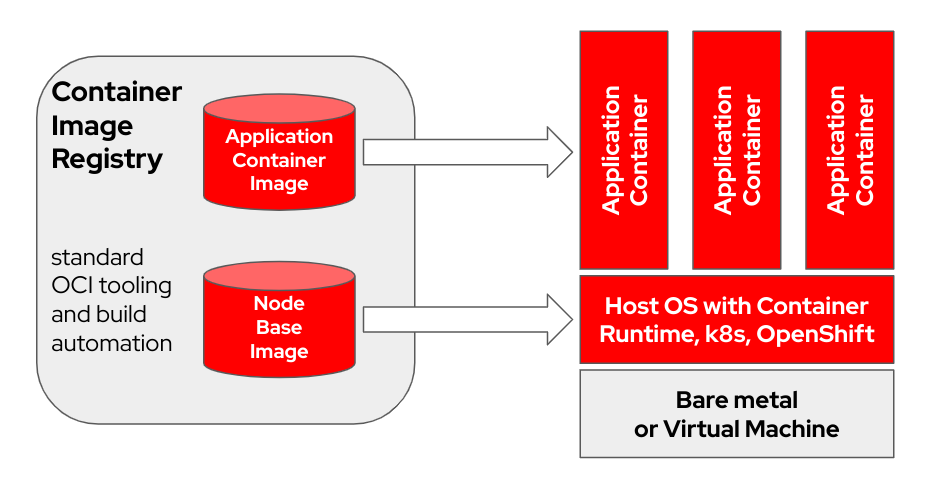
Dependiendo del hardware del host de compilación y de la velocidad de la conexión a Internet, la creación y carga de imágenes de contenedores puede tardar hasta 2 horas.
m5.xlarge usando almacenamiento GP3)quay.io u otro registro de imágenes. Registre el host (¿Cómo registrar y suscribir un sistema RHEL al Portal del cliente de Red Hat utilizando Red Hat Subscription-Manager?)
sudo subscription-manager register --username < username > --password < password >Instalar los paquetes necesarios
sudo dnf install git make podman buildah lorax -yClonar el repositorio git de RHEL AI Developer Preview
git clone https://github.com/RedHatOfficial/rhelai-dev-preview Autentíquese en el registro de Red Hat (Autenticación de Registro de Contenedores de Red Hat) utilizando su cuenta redhat.com .
podman login registry.redhat.io --username < username > --password < password >
podman login --get-login registry.redhat.io
Your_login_here Asegúrese de tener una clave SSH en el host de compilación. Esto se utiliza durante la creación de la imagen del kit de herramientas del controlador. (Uso de ssh-keygen y uso compartido para autenticación basada en claves en Linux | Habilite Sysadmin)
RHEL AI incluye un conjunto de Makefiles para facilitar la creación de imágenes del contenedor. Dependiendo del hardware del host de compilación y de la velocidad de la conexión a Internet, esto podría tardar hasta una hora.
Cree la imagen del contenedor NVIDIA de InstructLab.
make instruct-nvidia Cree la imagen del contenedor vllm .
make vllm Cree la imagen del contenedor deepspeed .
make deepspeed Por último, cree la imagen del contenedor bootc RHEL AI NVIDIA. Este es el contenedor "de arranque" del modo Imagen de RHEL. Incorporamos las 3 imágenes de arriba en este contenedor.
make nvidia FROM=registry.redhat.io/rhel9/rhel-bootc:9.4 REGISTRY= < your-registry > REGISTRY_ORG= < your-org-name > La imagen resultante tiene la etiqueta ${REGISTRY}/${REGISTRY_ORG}/nvidia-bootc:latest . Para obtener más variables y ejemplos, consulte la capacitación/README.
Envíe la imagen resultante a su registro. En el siguiente paso, consultará esta URL dentro de un archivo kickstart.
podman push ${REGISTRY} / ${REGISTRY_ORG} /nvidia-bootc:latest
e.g. podman push quay.io/ < your-user-name > /nvidia-bootc.latestEn este punto, tiene una imagen de contenedor de arranque de RHEL AI lista para instalarse en un host físico o virtual.
Anaconda es el instalador de Red Hat Enterprise Linux y está integrado en todas las imágenes ISO descargables de RHEL. El método principal para automatizar la instalación de RHEL es mediante scripts llamados Kickstart. Para obtener más información sobre Anaconda y Kickstart, lea estos documentos.
Con RHEL 9.4 se introdujo un comando kickstart reciente llamado ostreecontainer . Usamos ostreecontainer para aprovisionar el contenedor de arranque nvidia-bootc que acaba de enviar a su registro a través de la red.
A continuación se muestra un ejemplo de un archivo kickstart. Cópielo en un archivo llamado rhelai-dev-preview-bootc.ks y personalícelo para su entorno:
# text
## customize this for your target system
# network --bootproto=dhcp --device=link --activate
## Basic partitioning
## customize this for your target system
# clearpart --all --initlabel --disklabel=gpt
# reqpart --add-boot
# part / --grow --fstype xfs
# ostreecontainer --url quay.io/<your-user-name>/nvidia-bootc:latest
# firewall --disabled
# services --enabled=sshd
## optionally add a user
# user --name=cloud-user --groups=wheel --plaintext --password
# sshkey --username cloud-user "ssh-ed25519 AAAAC3Nza....."
## if desired, inject an SSH key for root
# rootpw --iscrypted locked
# sshkey --username root "ssh-ed25519 AAAAC3Nza..."
# reboot
Descargue el “ISO de arranque” de RHEL 9.4 y use el comando mkksiso para incrustar el kickstart en el ISO de arranque de RHEL.
mkksiso rhelai-dev-preview-bootc.ks rhel-9.4-x86_64-boot.iso rhelai-dev-preview-bootc-ks.isoEn este punto deberías tener:
nvidia-bootc:latest : una imagen de contenedor de arranque compatible con GPU NVIDIArhelai-dev-preview-bootc.ks : un archivo kickstart personalizado para aprovisionar RHEL desde su registro de contenedor a su sistema de destino.rhelai-dev-preview-bootc-ks.iso : un ISO RHEL 9.4 de arranque con kickstart integrado. Inicie su sistema de destino utilizando el archivo rhelai-dev-preview-bootc-ks.iso . anaconda extraerá la imagen nvidia-bootc:latest de su registro y aprovisionará RHEL de acuerdo con su archivo kickstart.
Alternativa : el archivo kickstart se puede entregar a través de HTTP. En la instalación a través de la línea de comando del kernel y un servidor HTTP externo, agregue inst.ks=http(s)://kickstart/url/rhelai-dev-preview-bootc.ks
Antes de utilizar el entorno RHEL AI, debe descargar dos modelos, cada uno de ellos adaptado a una función clave en el proceso de ajuste de alta fidelidad. Granite se utiliza como modelo de estudiante y es responsable de facilitar el entrenamiento de un nuevo modo afinado. Mixtral se utiliza como modelo docente y es responsable de ayudar en la fase de generación del proceso LAB, donde las habilidades y el conocimiento se utilizan en conjunto para producir un rico conjunto de datos de capacitación.
Settings .Access Tokens . Haga clic en el botón New token y proporcione un nombre. El nuevo token solo requiere el uso de permisos Read , ya que solo se usa para recuperar modelos. En esta pantalla, podrá generar el contenido del token y guardar y copiar el texto para autenticarse. 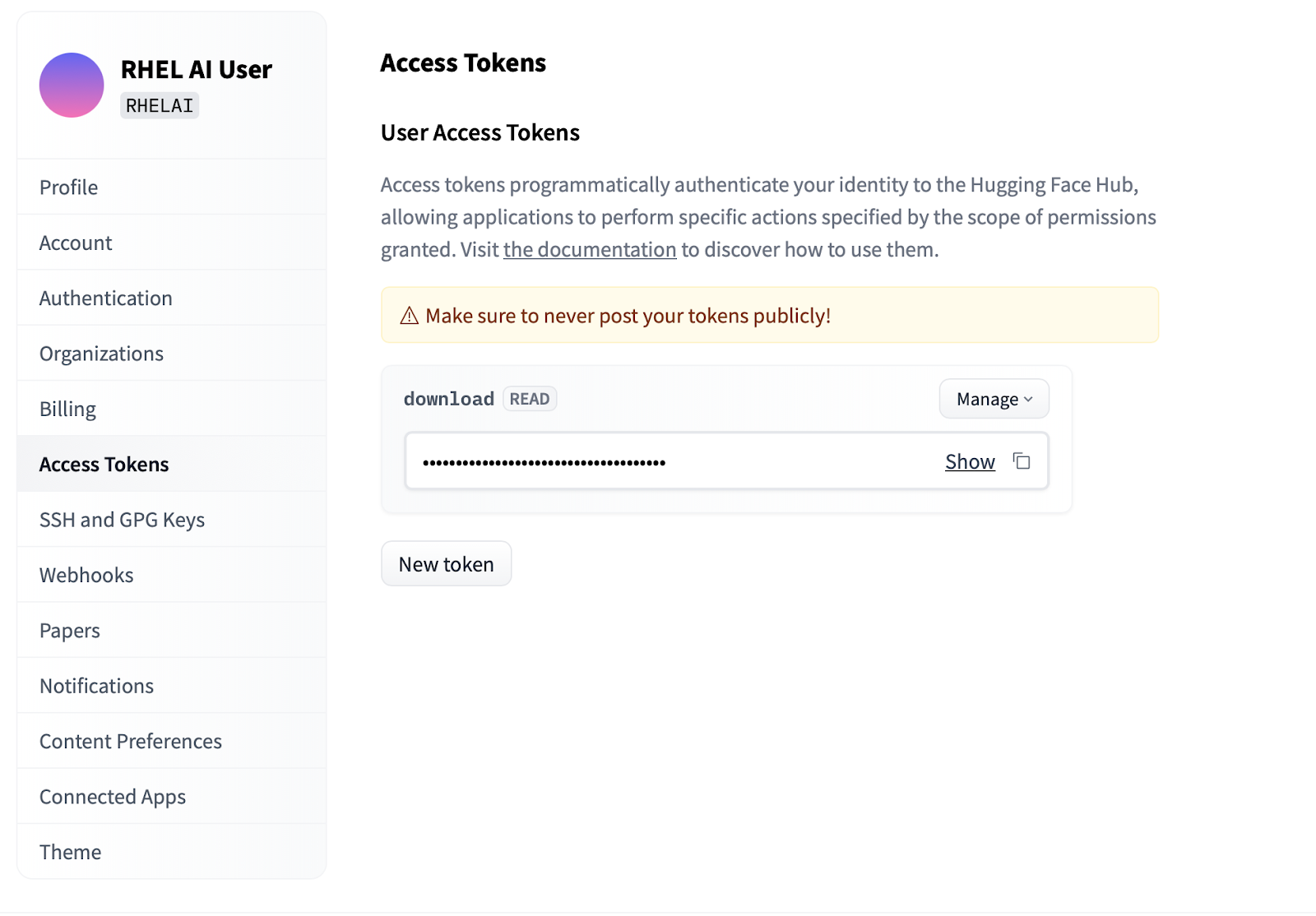
La interfaz de línea de comandos ilab que forma parte del proyecto InstructLab se centra en ejecutar modelos cuantificados livianos en dispositivos informáticos personales como computadoras portátiles. Por el contrario, RHEL AI permite el uso de entrenamiento de alta fidelidad utilizando modelos de total precisión. Para mayor familiaridad, el comando y los parámetros reflejan los del comando ilab de InstructLab; sin embargo, la implementación del respaldo es muy diferente.
En RHEL AI, el comando
ilabes un contenedor que actúa como interfaz para una arquitectura de contenedor incluida previamente en el sistema RHEL AI.
ilabEl primer paso es crear un nuevo directorio de trabajo para su proyecto. Todo será relativo a este directorio de trabajo. Contendrá sus modelos, registros y datos de entrenamiento.
mkdir my-project
cd my-project El primer comando ilab que ejecutará configura el entorno base, incluida la descarga del repositorio de taxonomía si lo desea. Esto será necesario para pasos posteriores, por lo que se recomienda hacerlo.
ilab initDefina una variable de entorno utilizando el token HF que creó en la sección anterior en Tokens de acceso.
export HF_TOKEN= < paste token value here > A continuación, descargue el modelo base de IBM Granite. Importante: No descargue las versiones “laboratorio” del modelo. El modelo con base de granito es más eficaz cuando se realiza un entrenamiento de alta fidelidad.
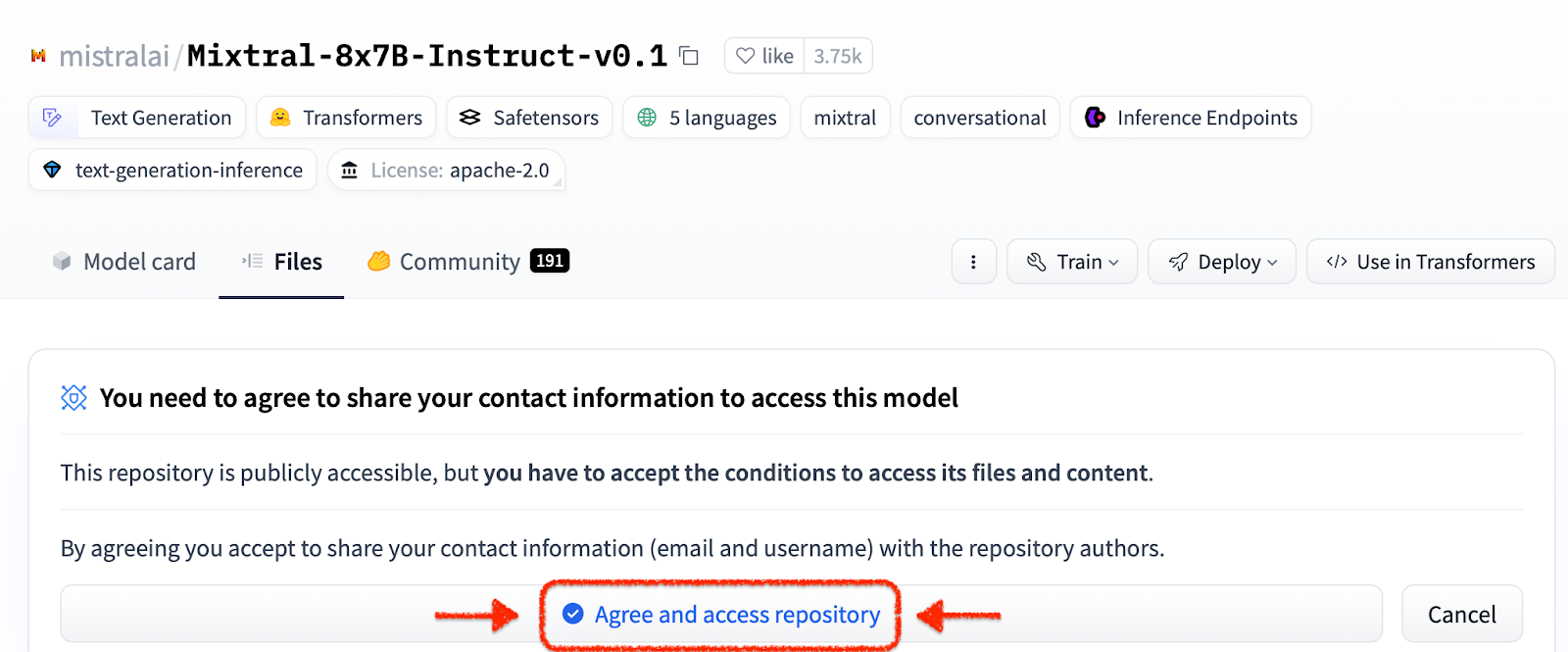
ilab download --repository ibm/granite-7b-baseSigue el mismo proceso para descargar el modelo Mixtral.
ilab download --repository mistralai/Mixtral-8x7B-Instruct-v0.1Ahora que ha inicializado su proyecto y descargado sus primeros modelos, observe la estructura de directorios de su proyecto.
my-project/
├─ models/
├─ generated/
├─ taxonomy/
├─ training/
├─ training_output/
├─ cache/
| Carpeta | Objetivo |
|---|---|
| modelos | Contiene todos los modelos de lenguaje, incluida la salida guardada de los que genera con RHEL AI |
| generado | Salida de datos generados desde la fase de generación, basada en modificaciones al repositorio de taxonomía. |
| taxonomía | Datos de habilidades o conocimientos utilizados por el método LAB para generar datos sintéticos para la capacitación |
| capacitación | Datos de semillas convertidos para facilitar el proceso de capacitación. |
| salida_entrenamiento | Todos los resultados transitorios del proceso de capacitación, incluidos registros y puntos de control de muestra en vuelo. |
| cache | Un caché interno utilizado por los datos del modelo. |
El siguiente paso es aportar nuevos conocimientos o habilidades al repositorio de taxonomía. Consulte la documentación de InstructLab para obtener más información y ejemplos de cómo hacer esto. También tenemos una serie de ejercicios de laboratorio aquí.
Con los datos de taxonomía adicionales agregados, ahora es posible generar nuevos datos sintéticos para eventualmente entrenar un nuevo modelo. Sin embargo, antes de que pueda comenzar la generación, primero es necesario iniciar un modelo docente para ayudar al generador a construir nuevos datos. En una sesión de terminal separada, ejecute el comando "servir" y espere a que se complete el inicio de VLLM. Tenga en cuenta que este proceso puede tardar varios minutos en completarse.
ilab serve
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit) Ahora que VLLM está funcionando en modo profesor, el proceso de generación se puede iniciar utilizando el comando ilab generate. Este proceso tardará algún tiempo en completarse y generará continuamente la cantidad total de instrucciones generadas a medida que se actualiza. El valor predeterminado es 5000 instrucciones, pero puede ajustarlo con la opción --num-instructions .
ilab generate Q> How do cytokines influence the outcome of certain diseases involving tonsils?
A> The outcome of infectious, autoimmune, or malignant diseases affecting tonsils may be influenced by the overall balance of production profiles of pro-inflammatory and anti-inflammatory cytokines. Determining cytokine profiles in tonsil studies is essential for understanding the causes and underlying mechanisms of these disorders.
35%|████████████████████████████████████████▉
Además de los datos actuales impresos en la pantalla durante la generación, se registra una salida completa en la carpeta generada. Antes de la capacitación, se recomienda revisar este resultado para verificar que cumpla con las expectativas. Si no es satisfactorio, intente modificar o crear nuevos ejemplos en la taxonomía y vuelva a ejecutar.
less generated/generated_Mixtral * .jsonUna vez que los datos generados sean satisfactorios, se puede comenzar el proceso de capacitación. Aunque primero cierre la instancia de VLLM en la sesión del terminal que se inició para la generación.
CTRL+C
INFO: Application shutdown complete.
INFO: Finished server process [1]
Es posible que reciba una excepción Python KeyboardInterrupt y un seguimiento de la pila. Esto se puede ignorar con seguridad.
Con VLLM detenido y los nuevos datos generados, el proceso de capacitación se puede iniciar usando el comando ilab train . De forma predeterminada, el proceso de capacitación guarda un punto de control del modelo después de cada 4999 muestras. Puede ajustar esto usando el parámetro --num-samples . Además, el entrenamiento se ejecuta de forma predeterminada durante 10 épocas, que también se pueden ajustar con el parámetro --num-epochs . Generalmente, más épocas son mejores, pero después de cierto punto, más épocas provocarán un sobreajuste. Por lo general, se recomienda permanecer dentro de 10 épocas o menos y observar diferentes puntos de muestra para encontrar el mejor resultado.
ilab train --num-epochs 9 RunningAvgSamplesPerSec=149.4829861942806, CurrSamplesPerSec=161.99957513920629, MemAllocated=22.45GB, MaxMemAllocated=29.08GB
throughput: 161.84935045724643 samples/s, lr: 1.3454545454545455e-05, loss: 0.840185821056366 cuda_mem_allocated: 22.45188570022583 GB cuda_malloc_retries: 0 num_loss_counted_tokens: 8061.0 batch_size: 96.0 total loss: 0.8581467866897583
Epoch 1: 100%|█████████████████████████████████████████████████████████| 84/84 [01:09<00:00, 1.20it/s]
total length: 2527 num samples 15 - rank: 6 max len: 187 min len: 149
Una vez que se haya completado el proceso de capacitación, las entradas del nuevo modelo se almacenarán en el directorio de modelos y las ubicaciones se imprimirán en la terminal.
Generated model in /root/workspace/models/tuned-0504-0051:
.
./samples_4992
./samples_9984
./samples_14976
./samples_19968
./samples_24960
./samples_29952
./samples_34944
./samples_39936
./samples_44928
./samples_49920
Se puede usar el mismo comando ilab serve para servir el nuevo modelo pasando la opción –model con el nombre y la muestra.
ilab serve --model tuned-0504-0051/samples_49920 Después de que VLLM haya comenzado con el nuevo modelo, se puede iniciar una sesión de chat creando una nueva sesión de terminal y pasando el mismo parámetro --model al chat (tenga en cuenta que si esto no coincide, recibirá un mensaje de error 404). Hágale una pregunta relacionada con sus contribuciones a la taxonomía.
ilab chat --model tuned-0504-0051/samples_49920╭─────────────────────────────── system ────────────────────────────────╮
│ Welcome to InstructLab Chat w/ │
│ /INSTRUCTLAB/MODELS/TUNED-0504-0051/SAMPLES_49920 (type /h for help) │
╰───────────────────────────────────────────────────────────────────────╯
>>> What are tonsils ?
╭────────── /instructlab/models/tuned-0504-0051/samples_49920 ──────────╮
│ │
│ Tonsils are a type of mucosal lymphatic tissue found in the │
│ aerodigestive tracts of various mammals, including humans. In the │
│ human body, the tonsils play a crucial role in protecting the body │
│ from infections, particularly those caused by bacteria and viruses. │
╰─────────────────────────────────────────────── elapsed 0.469 seconds ─╯Para salir de la sesión, escriba
exit
¡Eso es todo! El propósito de una Vista previa para desarrolladores es hacer llegar algo a nuestros usuarios para obtener comentarios tempranos. Nos damos cuenta de que puede haber errores. Y apreciamos su tiempo y esfuerzo si ha llegado hasta aquí. Es probable que tenga algunos problemas o necesite solucionarlos. Le recomendamos que presente informes de errores, solicitudes de funciones y nos haga preguntas. Consulte la información de contacto a continuación para saber cómo hacerlo. ¡Gracias!
$ sudo subscription-manager config --rhsm.manage_repos=1nvidia-smi para asegurarse de que los controladores funcionen y puedan ver las GPUnvtop (disponible en EPEL) para ver si se están utilizando las GPU (algunas rutas de código tienen respaldo de CPU, lo cual no queremos aquí)make prune fuera del subdirectorio de entrenamiento. Esto limpiará los artefactos de construcción antiguos.--no-cache al proceso de compilación. make nvidia-bootc CONTAINER_TOOL_EXTRA_ARGS= " --no-cache "TMPDIR : make < platform > TMPDIR=/path/to/tmp

