self instruct
1.0.0
Este repositorio contiene código y datos para el documento Self-Instruct, un método para alinear modelos de lenguaje previamente entrenados con instrucciones.
Self-Instruct es un marco que ayuda a los modelos de lenguaje a mejorar su capacidad para seguir instrucciones en lenguaje natural. Para ello, utiliza las propias generaciones del modelo para crear una gran colección de datos educativos. Con Self-Instruct, es posible mejorar las capacidades de seguimiento de instrucciones de los modelos de lenguaje sin depender de anotaciones manuales extensas.
En los últimos años, ha habido un interés creciente en la construcción de modelos que puedan seguir instrucciones en lenguaje natural para realizar una amplia gama de tareas. Estos modelos, conocidos como modelos de lenguaje "sintonizados con instrucciones", han demostrado la capacidad de generalizar a nuevas tareas. Sin embargo, su desempeño depende en gran medida de la calidad y cantidad de los datos de instrucción escritos por humanos utilizados para entrenarlos, que pueden ser limitados en diversidad y creatividad. Para superar estas limitaciones, es importante desarrollar enfoques alternativos para supervisar modelos ajustados a instrucciones y mejorar sus capacidades de seguimiento de instrucciones.
El proceso de autoinstrucción es un algoritmo de arranque iterativo que comienza con un conjunto inicial de instrucciones escritas manualmente y las utiliza para solicitar al modelo de lenguaje que genere nuevas instrucciones y las correspondientes instancias de entrada y salida. Luego, estas generaciones se filtran para eliminar las de baja calidad o similares, y los datos resultantes se agregan nuevamente al grupo de tareas. Este proceso se puede repetir varias veces, lo que da como resultado una gran colección de datos de instrucción que se pueden utilizar para ajustar el modelo de lenguaje para seguir las instrucciones de manera más efectiva.
Aquí hay una descripción general de la autoinstrucción:
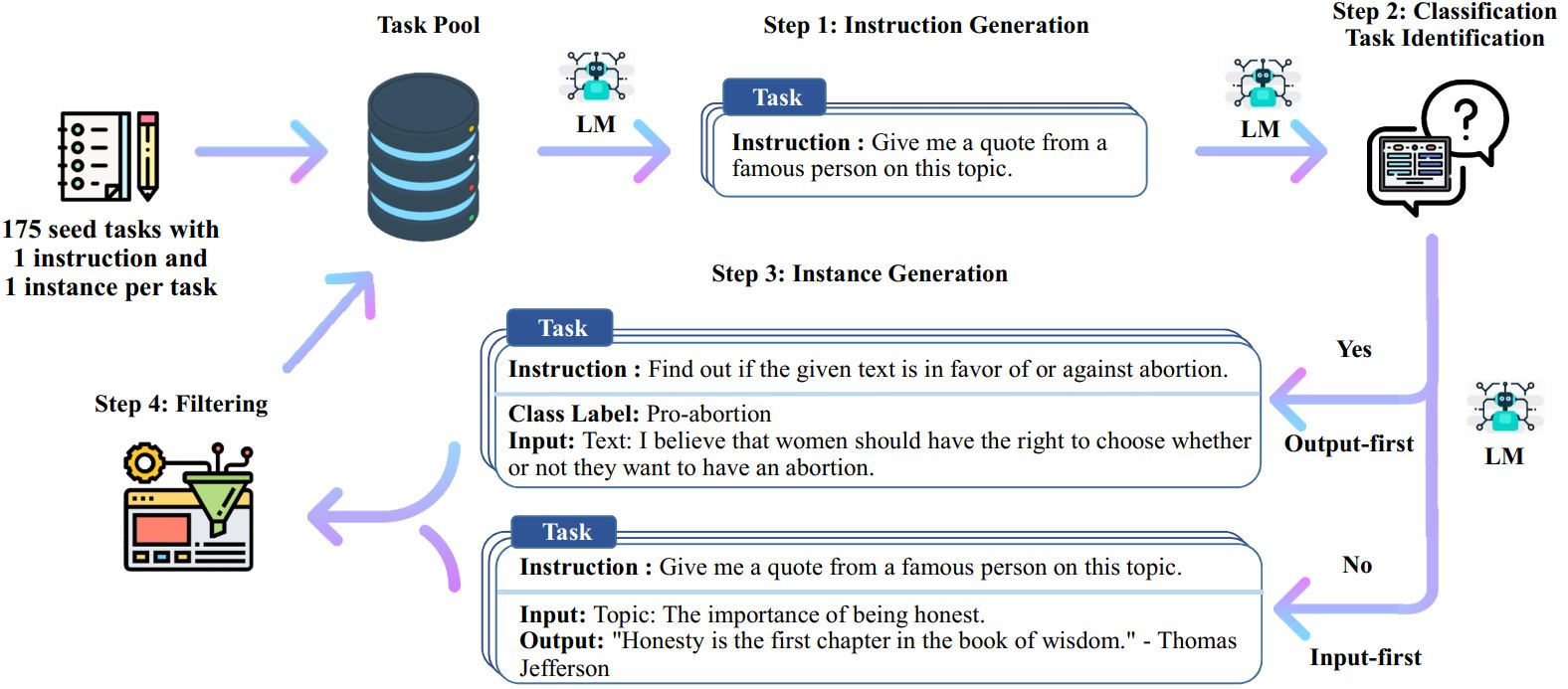
* Este trabajo aún está en progreso. Podemos actualizar el código y los datos a medida que avanzamos. Tenga cuidado con el control de versiones.
Lanzamos un conjunto de datos que contiene 52 000 instrucciones, combinadas con 82 000 entradas y salidas de instancias. Estos datos de instrucción se pueden utilizar para realizar ajustes de instrucción para modelos de lenguaje y hacer que el modelo de lenguaje siga mejor la instrucción. Se puede acceder a todos los datos generados por el modelo en data/gpt3-generations/batch_221203/all_instances_82K.jsonl . Estos datos (+ las 175 tareas iniciales) reformateados en un formato limpio de ajuste fino GPT3 (mensaje + finalización) se colocan en data/finetuning/self_instruct_221203 . Puede utilizar el script en ./scripts/finetune_gpt3.sh para ajustar GPT3 en estos datos.
Nota : Estos datos se generan mediante un modelo de lenguaje (GPT3) e inevitablemente contienen algunos errores o sesgos. Analizamos la calidad de los datos en 200 instrucciones aleatorias en nuestro artículo y descubrimos que el 46% de los puntos de datos pueden tener problemas. Animamos a los usuarios a utilizar estos datos con precaución y proponemos nuevos métodos para filtrar o mejorar las imperfecciones.
También lanzamos un nuevo conjunto de 252 tareas escritas por expertos y sus instrucciones motivadas por aplicaciones orientadas al usuario (en lugar de tareas de PNL bien estudiadas). Estos datos se utilizan en la sección de evaluación humana del documento de autoinstrucciones. Consulte el archivo README de evaluación humana para obtener más detalles.
Para generar datos de autoinstrucción utilizando sus propias tareas iniciales u otros modelos, abrimos nuestros scripts para todo el proceso aquí. Nuestro código actual solo se prueba en el modelo GPT3 al que se puede acceder a través de la API OpenAI.
Aquí están los scripts para generar los datos:
# 1. Generar instrucciones a partir de las tareas semilla./scripts/generate_instructions.sh# 2. Identificar si la instrucción representa una tarea de clasificación o no./scripts/is_clf_or_not.sh# 3. Generar instancias para cada instrucción./scripts/generate_instances. sh# 4. Filtrado, procesamiento y reformateo./scripts/prepare_for_finetuning.sh
Si utiliza el marco o los datos de Autoinstrucciones, no dude en citarnos.
@misc{selfinstruct, title={Autoinstrucción: Alinear el modelo del lenguaje con instrucciones autogeneradas}, autor={Wang, Yizhong y Kordi, Yeganeh y Mishra, Swaroop y Liu, Alisa y Smith, Noah A. y Khashabi, Daniel y Hajishirzi, Hannaneh}, diario={arXiv preprint arXiv:2212.10560}, año={2022}} 

