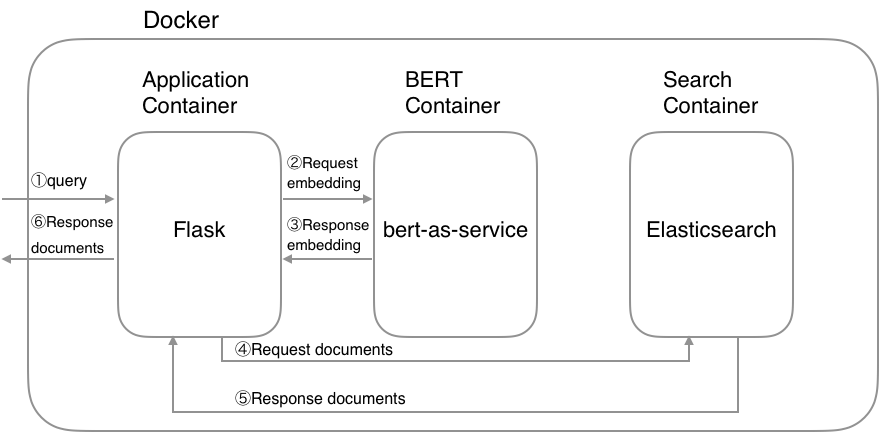
bertsearch
1.0.0
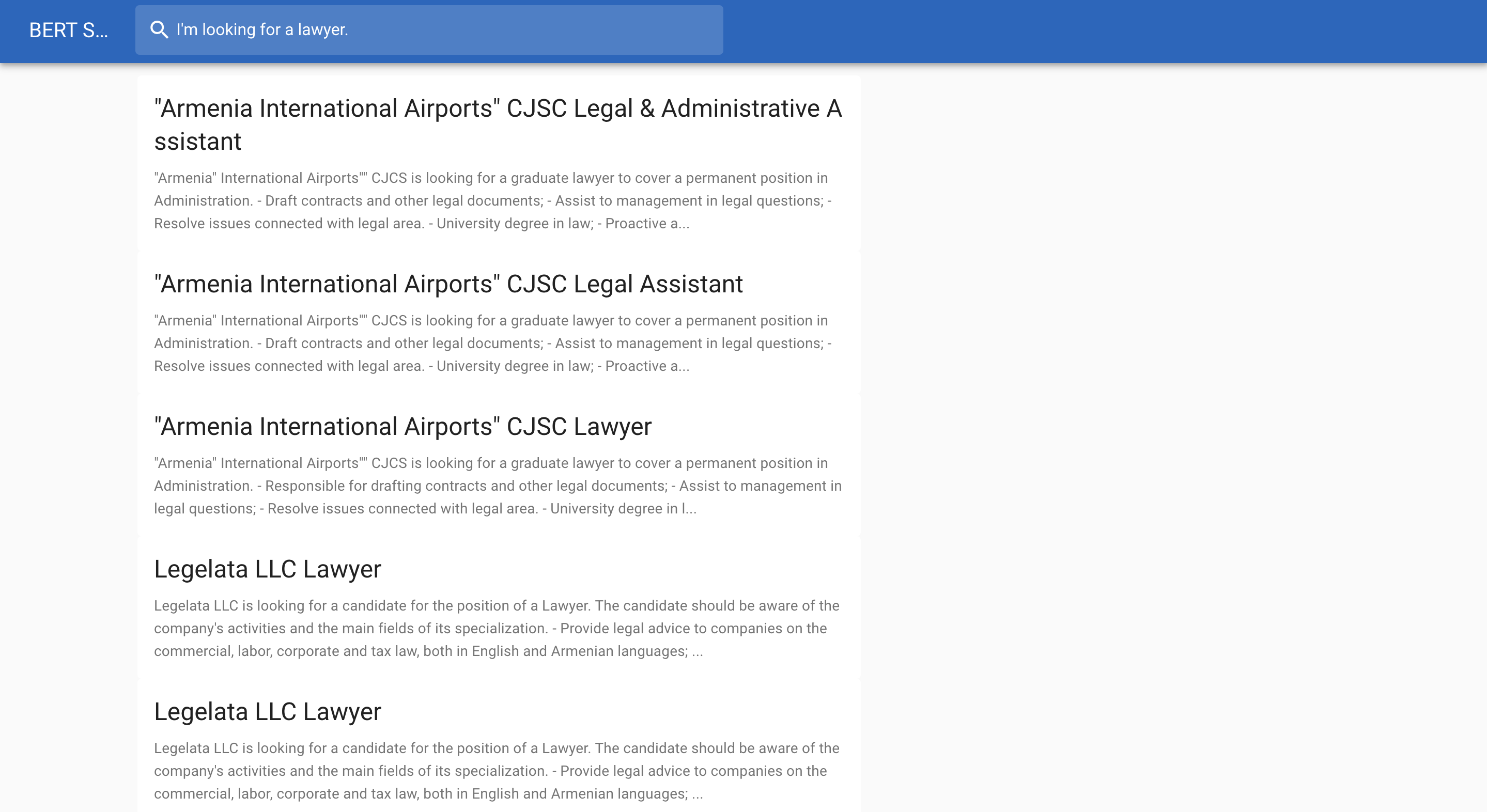
A continuación se muestra un ejemplo de búsqueda de empleo:
| BERT-Base, sin caja | 12 capas, 768 ocultos, 12 cabezales, 110M parámetros |
| BERT-Grande, sin caja | Parámetros de 24 capas, 1024 ocultos, 16 cabezales, 340 M |
| Base BERT, en caja | 12 capas, 768 ocultos, 12 cabezales, 110 M de parámetros |
| BERT-Grande, con caja | Parámetros de 24 capas, 1024 ocultos, 16 cabezales, 340 M |
| BERT-Base, en caja multilingüe (nuevo) | 104 idiomas, 12 capas, 768 ocultos, 12 cabezales, 110 millones de parámetros |
| BERT-Base, en caja multilingüe (antiguo) | 102 idiomas, 12 capas, 768 ocultos, 12 cabezales, 110 millones de parámetros |
| BERT-Base, chino | Chino simplificado y tradicional, 12 capas, 768 ocultos, 12 cabezales, 110 millones de parámetros |
$ wget https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
$ unzip cased_L-12_H-768_A-12.zipDebe configurar un modelo BERT previamente entrenado y el nombre del índice de Elasticsearch como variables de entorno:
$ export PATH_MODEL=./cased_L-12_H-768_A-12
$ export INDEX_NAME=jobsearch$ docker-compose up PRECAUCIÓN : Si es posible, asigne mucha memoria (más de 8GB ) a la configuración de memoria de Docker porque el contenedor BERT necesita mucha memoria.
Puede utilizar la API de creación de índice para agregar un nuevo índice a un clúster de Elasticsearch. Al crear un índice, puede especificar lo siguiente:
Por ejemplo, si desea crear un índice jobsearch con los campos title , text y text_vector , puede crear el índice con el siguiente comando:
$ python example/create_index.py --index_file=example/index.json --index_name=jobsearch
# index.json
{
" settings " : {
" number_of_shards " : 2,
" number_of_replicas " : 1
},
" mappings " : {
" dynamic " : " true " ,
" _source " : {
" enabled " : " true "
},
" properties " : {
" title " : {
" type " : " text "
},
" text " : {
" type " : " text "
},
" text_vector " : {
" type " : " dense_vector " ,
" dims " : 768
}
}
}
} PRECAUCIÓN : El valor de dims de text_vector debe coincidir con el de un modelo BERT previamente entrenado.
Una vez que haya creado un índice, estará listo para indexar algún documento. El punto aquí es convertir su documento en un vector usando BERT. El vector resultante se almacena en el campo text_vector . Convirtamos sus datos en un documento JSON:
$ python example/create_documents.py --data=example/example.csv --index_name=jobsearch
# example/example.csv
" Title " , " Description "
" Saleswoman " , " lorem ipsum "
" Software Developer " , " lorem ipsum "
" Chief Financial Officer " , " lorem ipsum "
" General Manager " , " lorem ipsum "
" Network Administrator " , " lorem ipsum "Después de finalizar el script, puede obtener un documento JSON como el siguiente:
# documents.jsonl
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Saleswoman" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Software Developer" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Chief Financial Officer" , "text_vector" : [...]}
...Después de convertir sus datos a JSON, puede agregar un documento JSON al índice especificado y hacerlo apto para búsquedas.
$ python example/index_documents.pyVaya a http://127.0.0.1:5000.


