MyScaleDB
v1.8.0

Permita que todos los desarrolladores creen aplicaciones GenAI de nivel de producción con SQL potente y familiar.
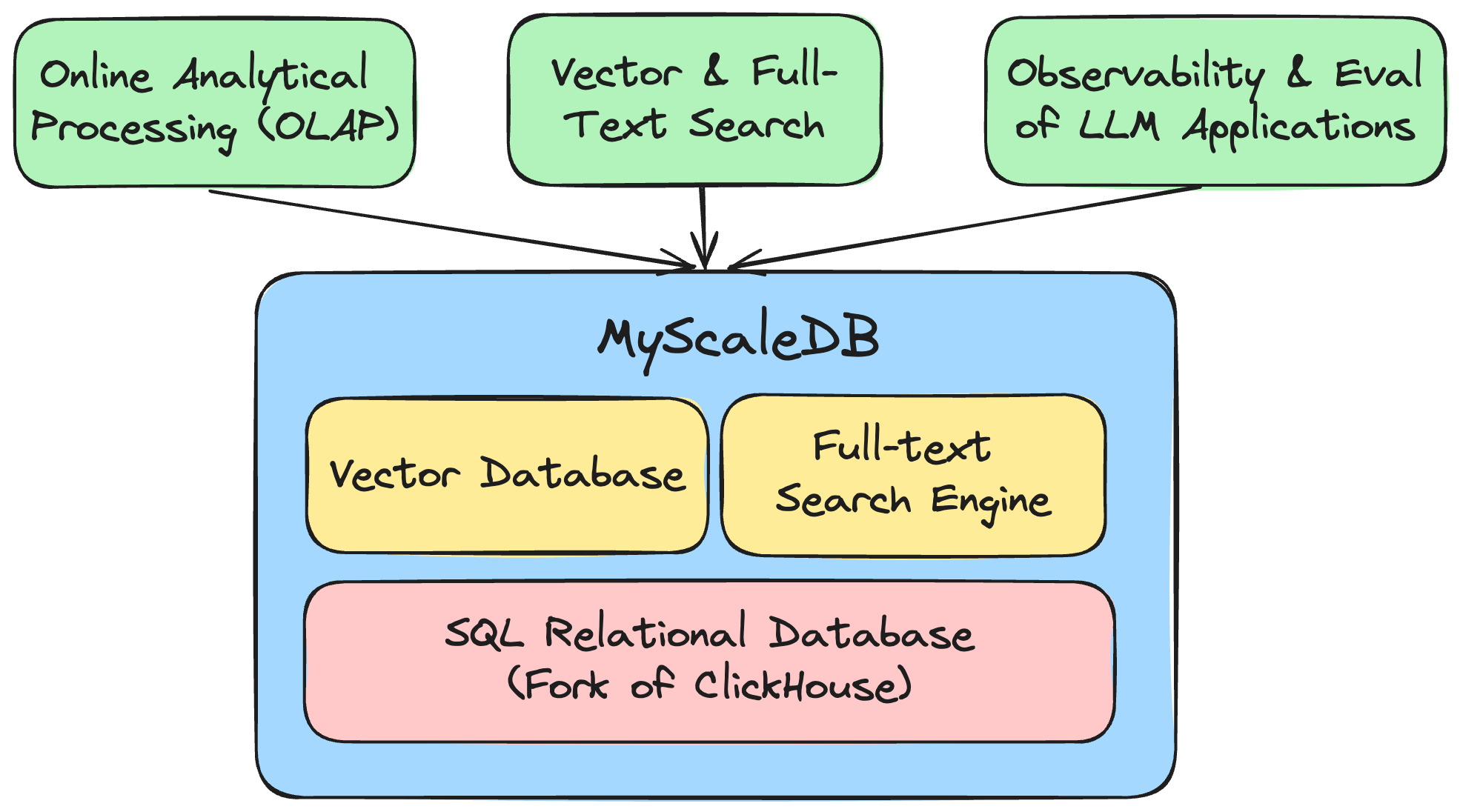
MyScaleDB es la base de datos vectorial SQL que permite a los desarrolladores crear aplicaciones de IA escalables y listas para producción utilizando SQL familiar. Está construido sobre ClickHouse y optimizado para aplicaciones y soluciones de inteligencia artificial, lo que permite a los desarrolladores administrar y procesar de manera efectiva grandes volúmenes de datos.
Los beneficios clave de usar MyScaleDB incluyen:
Totalmente compatible con SQL
Búsqueda vectorial, búsqueda filtrada y consultas de combinación de vectores SQL rápidas, potentes y eficientes.
Utilice SQL con funciones relacionadas con vectores para interactuar con MyScaleDB. No es necesario aprender nuevas herramientas o marcos complejos: quédese con lo que conoce y ama.
Listo para producción para aplicaciones de IA
Una plataforma unificada y probada en el tiempo para gestionar y procesar datos estructurados, texto, vectores, JSON, geoespaciales, datos de series temporales y más. Ver tipos de datos y funciones admitidos
Precisión de RAG mejorada al combinar vectores con metadatos enriquecidos, búsqueda de texto completo y realizar búsquedas filtradas de alta precisión y eficiencia en cualquier proporción 1 .
Rendimiento y escalabilidad inigualables
MyScaleDB aprovecha la arquitectura de base de datos OLAP de vanguardia y algoritmos vectoriales avanzados para operaciones vectoriales ultrarrápidas.
Escale sus aplicaciones sin esfuerzo y de forma rentable a medida que crecen sus datos.
MyScale Cloud proporciona MyScaleDB totalmente administrado con funciones premium en datos de mil millones de escala 2 . En comparación con las bases de datos vectoriales especializadas que utilizan API personalizadas, MyScale es más potente, eficaz y rentable, sin dejar de ser más sencillo de usar. Esto lo hace adecuado para una gran comunidad de programadores. Además, en comparación con bases de datos vectoriales integradas como PostgreSQL con pgvector o ElasticSearch con extensiones vectoriales, MyScale consume menos recursos y logra mayor precisión y velocidad para consultas estructuradas y conjuntas vectoriales, como búsquedas filtradas.
Totalmente compatible con SQL
Gestión unificada de datos estructurados y vectorizados.
Búsqueda de milisegundos en vectores a escala de mil millones
Altamente confiable y linealmente escalable
Potentes funciones de búsqueda de texto y búsqueda híbrida de texto/vector
Consultas vectoriales SQL complejas
Observabilidad de LLM con MyScale Telemetry
MyScale unifica tres sistemas: base de datos/almacén de datos SQL, base de datos vectorial y motor de búsqueda de texto completo en un solo sistema de una manera altamente eficiente. No solo ahorra costos de infraestructura y mantenimiento, sino que también permite consultas y análisis de datos conjuntos.
Consulte nuestra documentación y blogs para obtener más información sobre las características y ventajas únicas de MyScale. Nuestro punto de referencia de código abierto proporciona una comparación detallada con otros productos de bases de datos vectoriales.
ClickHouse es una popular base de datos analítica de código abierto que se destaca en el procesamiento y análisis de big data debido a su almacenamiento en columnas con compresión avanzada, indexación por omisión y procesamiento SIMD. A diferencia de las bases de datos transaccionales como PostgreSQL y MySQL, que utilizan almacenamiento de filas y optimizaciones principales para el procesamiento transaccional, ClickHouse tiene velocidades analíticas y de escaneo de datos significativamente más rápidas.
Una de las operaciones clave al combinar la búsqueda estructurada y vectorial es la búsqueda filtrada, que implica filtrar primero por otros atributos y luego realizar una búsqueda vectorial en los datos restantes. El almacenamiento en columnas y el filtrado previo son cruciales para garantizar una alta precisión y un alto rendimiento en la búsqueda filtrada, razón por la cual elegimos construir MyScaleDB sobre ClickHouse.
Si bien hemos modificado el motor de ejecución y almacenamiento de ClickHouse de muchas maneras para garantizar consultas vectoriales SQL rápidas y rentables, muchas de las características (#37893, #38048, #37859, #56728, #58223) relacionadas con el procesamiento general de SQL se han modificado. Contribuyó a la comunidad de código abierto de ClickHouse.
La forma más sencilla de utilizar MyScaleDB es crear una instancia en el servicio MyScale Cloud. Puede comenzar desde un pod gratuito que admita vectores 5M 768D. Regístrese aquí y consulte MyScaleDB QuickStart para obtener más instrucciones.
Para poner en funcionamiento rápidamente una instancia de MyScaleDB, simplemente extraiga y ejecute la última imagen de Docker:
ejecución de la ventana acoplable --name myscaledb --net=host myscale/myscaledb:1.8.0
Nota: La configuración predeterminada de Myscale solo permite el acceso a la IP del host local. Para el método de inicio de ejecución de Docker, debe especificar
--net=hostpara acceder a los servicios implementados en modo Docker en el nodo actual.
Esto iniciará una instancia de MyScaleDB con el usuario default y sin contraseña. Luego puede conectarse a la base de datos usando clickhouse-client :
ejecutivo de Docker -it myscaledb cliente-clickhouse
Utilice la siguiente estructura de directorios recomendada y la ubicación del archivo docker-compose.yaml :
> árbol myscaledb
myscaledb
├── docker-compose.yaml
└── volúmenes
└── configuración
└── usuarios.d
└── custom_users_config.xml
3 directorios, 2 archivos Defina la configuración para su implementación. Recomendamos comenzar con la siguiente configuración en su archivo docker-compose.yaml , que puede ajustar según sus requisitos específicos:
versión: '3.7'servicios: myscaledb:imagen: myscale/myscaledb:1.8.0tty: trueports:
- '8123:8123' - '9000:9000' - '8998:8998' - '9363:9363' - '9116:9116'redes: myscaledb_network:ipv4_address: 10.0.0.2volumenes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/data:/var/lib/clickhouse - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/log:/var/log/clickhouse-server - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/config/users.d/custom_users_config.xml:/etc/clickhouse-server/users.d/custom_users_config.xmldeploy: recursos:límites: cpus: "16.00" memoria: 32Gbnetworks: myscaledb_network: controlador: bridgeipam: controlador: configuración predeterminada:
- subred: 10.0.0.0/24 custom_users_config.xml :
<casa de clic>
<usuarios>
<predeterminado>
<contraseña></contraseña>
<redes>
<ip>::1</ip>
<ip>127.0.0.1</ip>
<ip>10.0.0.0/24</ip>
</redes>
<perfil>predeterminado</perfil>
<quota>predeterminado</quota>
<access_management>1</access_management>
</predeterminado>
</usuarios>
</casa de clic>Nota: La configuración custom_users_config le permite utilizar el usuario predeterminado para acceder a la base de datos en el nodo donde se implementa el servicio de base de datos mediante Docker Compose. Si desea acceder al servicio de base de datos en otros nodos, se recomienda crear un usuario al que se pueda acceder a través de otras IP. Para obtener configuraciones detalladas, consulte: MyScaleDB Crear usuario. También puede personalizar el archivo de configuración de MyScaleDB. Copie el directorio
/etc/clickhouse-serverde su contenedormyscaledba su unidad local, modifique la configuración y agregue una asignación de directorio al archivodocker-compose.yamlpara que la configuración surta efecto:- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/config:/etc/clickhouse-server
Utilice el siguiente comando para ejecutarlo:
cd myscaledb ventana acoplable componer -d
Acceda a la interfaz de línea de comando MyScaleDB usando el siguiente comando.
docker exec -it myscaledb-myscaledb-1 cliente-clickhouse
Ahora puede ejecutar sentencias SQL. Consulte Ejecución de consultas SQL.
El entorno de compilación compatible es Ubuntu 22.04 con LLVM 15.0.7.
Consulte la carpeta de scripts.
Uso de ejemplo:
LLVM_VERSION=15 sudo -E bash scripts/install_deps.sh sudo apt-get -y instalar rustc cargo yasm scripts bash/config_on_linux.sh scripts bash/build_on_linux.sh
Los ejecutables resultantes estarán en MyScaleDB/build/programs/* .
Consulte la documentación de búsqueda de vectores para saber cómo crear una tabla SQL con índice de vectores y realizar búsquedas de vectores. Se recomienda especificar TYPE SCANN al crear un índice vectorial en MyScaleDB de código abierto.
-- Crea una tabla con body_vector de longitud 384CREATE TABLE default.wiki_abstract (`id` UInt64,`body` String,`title` String,`url` String,`body_vector` Array(Float32),CONSTRAINT check_length CHECK length(body_vector) = 384) MOTOR = MergeTreeORDER BY id;
-- Insertar datos de archivos de parquet en S3INSERT INTO default.wiki_abstract SELECT * FROM s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/wiki_abstract_with_vector.parquet','Parquet'); -- Cree un índice vectorial SCANN con la métrica Coseno en body_vectorALTER TABLE default.wiki_abstract ADD VECTOR INDEX vec_idx body_vector TYPE SCANN('metric_type=Cosine');-- Consulta el progreso de creación del índice desde la tabla `vector_indices`-- Espere hasta que el progreso del índice se convierte en `Built`SELECT * FROM system.vector_indices;- Realizar una búsqueda vectorial y devolver los 5 primeros resultadosSELECCIONAR identificación, título, distancia(vector_cuerpo, [-0.052, -0.0146, -0.0677, -0.0256, -0.0395, -0.0381, -0.025, 0.0911, -0.0429, -0.0592, 0.0017, -0.0358, -0.0464, -0.0189, -0,0192, 0,0544, -0,0022, -0,0292, -0,0474, -0,0286, 0,0746, -0,013, -0,0217, -0,0246, -0,0169, 0,0495, -0,0947, 0,0139, 0,0445, -0,0262, -0,0049, 0,0506, 0,004, 0,0276, 0,0063, -0,0643, 0,0059, -0,0229, -0,0315, 0,0549, 0,1427, 0,0079, 0,011, -0,0036, -0,0617, 0,0155, -0,0607, 0,0258, -0,0205, 0,0008, -0,0547, 0,0329, -0,0522, -0,0347, 0,0921, 0,0139, -0,013, 0,0716, -0,0165, 0,0257, -0,0071, 0,0084, -0,0653, 0,0091, 0,0544, -0,0192, -0,0169, -0,0017, -0,0304, 0,0427, -0,0389, 0,0921, -0,0622, -0,0196, 0,0025, 0,0214, 0,0259, -0,0493, -0,0211, -0,119, -0,0736, -0,1545, -0,0578, -0,0145, 0,0138, 0,0478, -0,0451, -0,0332, 0,0799, 0,0001, -0,0737, 0,0427, 0,0517, 0,0102, 0,0386, 0,0233, 0,0425, -0,0279, -0,0529, 0,0744, -0,0305, -0,026, 0,1229, -0,002, 0,0038, -0,0491, 0,0352, 0,0027, -0,056, -0,1044, 0,123, -0,0184, 0,1148, -0,0189, 0,0412, -0,0347, -0,0569, -0,0119, 0,0098, -0,0016, 0,0451, 0,0273, 0,0436, 0,0082, 0,0166, -0,0989, 0,0747, -0,0, 0,0306, -0,0717, -0,007, 0,0665, 0,0452, 0,0123, -0,0238, 0,0512, -0,0116, 0,0517, 0,0288, -0,0013, 0,0176, 0,0762, 0,1284, -0,031, 0,0891, -0,0286, 0,0132, 0,003, 0,0433, 0,0102, -0,0209, -0,0459, -0,0312, -0,0387, 0,0201, -0,027, 0,0243, 0,0713, 0,0359, -0,0674, -0,0747, -0,0147, 0,0489, -0,0092, -0,018, 0,0236, 0,0372, -0,0071, -0,0513, -0,0396, -0,0316, -0,0297, -0,0385, -0,062, 0,0465, 0,0539, -0,033, 0,0643, 0,061, 0,0062, 0,0245, 0,0868, 0,0523, -0,0253, 0,0157, 0,0266, 0,0124, 0,1382, -0,0107, 0,0835, -0,1057, -0,0188, -0,0786, 0,057, 0,0707, -0,0185, 0,0708, 0,0189, -0,0374, -0,0484, 0,0089, 0,0247, 0,0255, -0,0118, 0,0739, 0,0114, -0,0448, -0,016, -0,0836, 0,0107, 0,0067, -0,0535, -0,0186, -0,0042, 0,0582, -0,0731, -0,0593, 0,0299, 0,0004, -0,0299, 0,0128, -0,0549, 0,0493, 0,0, -0,0419, 0,0549, -0,0315, 0,1012, 0,0459, -0,0628, 0,0417, -0,0153, 0,0471, -0,0301, -0,0615, 0,0137, -0,0219, 0,0735, 0,083, 0,0114, -0,0326, -0,0272, 0,0642, -0,0203, 0,0557, -0,0579, 0,0883, 0,0719, 0,0007, 0,0598, -0,0431, -0,0189, -0,0593, -0,0334, 0,02, -0,0371, -0,0441, 0,0407, -0,0805, 0,0058, 0,1039, 0,0534, 0,0495, -0,0325, 0,0782, -0,0403, 0,0108, -0,0068, -0,0525, 0,0801, 0,0256, -0,0183, -0,0619, -0,0063, -0,0605, 0,0377, -0,0281, -0,0097, -0,0029, -0,106, 0,0465, -0,0033, -0,0308, 0,0357, 0,0156, -0,0406, -0,0308, 0,0013, 0,0458, 0,0231, 0,0207, -0,0828, -0,0573, 0,0298, -0,0381, 0,0935, -0,0498, -0,0979, -0,1452, 0,0835, -0,0973, -0,0172, 0,0003, 0,09, -0,0931, -0,0252, 0,008, -0,0441, -0,0938, -0,0021, 0,0885, 0,0088, 0,0034, -0,0049, 0,0217, 0,0584, -0,012, 0,059, 0,0146, -0,0, -0,0045, 0,0663, 0,0017, 0,0015, 0,0569, -0,0089, -0,0232, 0,0065, 0,0204, -0,0253, 0,1119, -0,036, 0,0125, 0,0531, 0,0584, -0,0101, -0,0593, -0,0577, -0,0656, -0,0396, 0,0525, -0,006, -0,0149, 0,003, -0,1009, -0,0281, 0,0311, -0,0088, 0,0441, -0,0056, 0,0715, 0,051, 0,0219, -0,0028, 0,0294, -0,0969, -0,0852, 0,0304, 0,0374, 0,1078, -0,0559, 0,0805, -0,0464, 0,0369, 0,0874, -0,0251, 0,0075, -0,0502, -0,0181, -0,1059, 0,0111, 0,0894, 0,0021, 0,0838, 0,0497, -0,0183, 0,0246, -0.004, -0.0828, 0.06, -0.1161, -0.0367, 0.0475, 0.0317]) COMO distancia DESDE default.wiki_abstract ORDEN POR distancia ASCLIMIT 5;
Estamos comprometidos a mejorar y evolucionar continuamente MyScaleDB para satisfacer las necesidades siempre cambiantes de la industria de la IA. ¡Únase a nosotros en este emocionante viaje y sea parte de la revolución en la gestión de datos de IA!
Discordia
Apoyo
Obtenga las últimas noticias o actualizaciones de MyScaleDB
Siga a @MyScaleDB en Twitter
Siga a @MyScale en LinkedIn
Leer el blog de MyScale
Índice invertido y búsqueda híbrida de palabras clave/vectores de alto rendimiento (compatible desde 1.5)
Admite más motores de almacenamiento, por ejemplo, ReplacingMergeTree (compatible desde 1.6)
Observabilidad de LLM con MyScaleDB y MyScale Telemetry
LLM centrado en datos
Ciencia de datos automática con MyScaleDB
MyScaleDB tiene la licencia Apache, versión 2.0. Ver una copia del archivo de licencia.
Agradecemos especialmente estos proyectos de código abierto sobre los cuales hemos desarrollado MyScaleDB:
ClickHouse: un DBMS de análisis gratuito para big data.
Faiss: una biblioteca para la búsqueda eficiente de similitudes y la agrupación de vectores densos, de Meta's Fundamental AI Research.
hnswlib: biblioteca C++/python de solo encabezado para vecinos más cercanos aproximados y rápidos.
ScaNN: biblioteca escalable de vecinos más cercanos de Google Research.
Tantivy: una biblioteca de motor de búsqueda de texto completo inspirada en Apache Lucene y escrita en Rust.
Vea aquí por qué el filtrado de metadatos es crucial para mejorar la precisión de RAG. ↩
El algoritmo MSTG (gráfico de árbol de múltiples escalas) se proporciona a través de MyScale Cloud, lo que logra una alta densidad de datos con almacenamiento basado en disco y un mejor rendimiento de indexación y búsqueda en datos vectoriales de mil millones de escala. ↩


