Este código se creó a partir de un modelo de aprendizaje profundo de Imagen a BEV preexistente, basado en el artículo Translating Images Into Maps. Este código fue escrito usando Python 3.7. y fue entrenado en el conjunto de datos nuScenes. Consulte el archivo Léame del repositorio para conocer las dependencias y los conjuntos de datos que desea instalar.
El primer paso es crear una carpeta llamada "traducir-imagenes-a-mapas-principal" y descargar todos los archivos en ella. Luego, debido al gran tamaño del archivo, los últimos puntos de control de nuestra capacitación y el conjunto de datos mini nuScenes utilizado para la validación se pueden descargar desde este Google Drive. Estas carpetas deben agregarse directamente en el directorio "traducir-imágenes-a-mapas-principal".
A continuación se muestra la lista de bibliotecas requeridas para este repositorio:
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
Para utilizar las funciones de este repositorio, es posible que sea necesario cambiar los siguientes argumentos de la línea de comando:
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
En cuanto al entrenamiento del modelo, estos argumentos de la línea de comando se pueden modificar:
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
Los conjuntos de datos NuScenes Mini y Full se pueden encontrar en las siguientes ubicaciones:
NuScene Mini:
NuScenes completo EE. UU.:
Como los conjuntos de datos NuScene mini y completo no tienen el mismo formato de entrada de imagen (lmdb o png), es necesario aplicar algunas modificaciones al código para usar uno u otro:
mini argumento a falso para usar el mini conjunto de datos, así como las rutas de argumentos y las divisiones en los archivos train.py , validation.py e inference.py . data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py : # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')Los puntos de control previamente entrenados se pueden encontrar aquí:
Los puntos de control deben mantenerse dentro de /pretrained_models/27_04_23_11_08 desde el directorio raíz de este repositorio. Si desea cargarlos desde otro directorio, cambie los siguientes argumentos:
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"Para entrenar con scitas, debe ejecutar el siguiente script desde el directorio raíz:
sbatch job.script.sh
Para entrenar localmente en la CPU:
python3 train.py
Asegúrese de adaptar el script con los argumentos de su línea de comando.
Para validar el rendimiento de un modelo en scitas:
sbatch job.validate.sh
Para entrenar localmente en la CPU:
python3 validate.py
Asegúrese de adaptar el script con los argumentos de su línea de comando.
Para inferir en un video sobre scitas:
sbatch job.evaluate.sh
Para entrenar localmente en la CPU:
python3 inference.py
Asegúrese de adaptar el script con los argumentos de su línea de comando, especialmente:
--batch-size // 1 for the test videos
--video-name
--video-root
Este proyecto se realizó en el contexto del curso CIVIL-459 de Aprendizaje profundo para vehículos autónomos, impartido por el profesor Alexandre Alahi en la EPFL. Fuimos supervisados por el estudiante de doctorado Yuejiang Liu. El objetivo principal del proyecto del curso es desarrollar un modelo de aprendizaje profundo que pueda utilizarse a bordo de un sistema de piloto automático Tesla. En cuanto a nuestro grupo, hemos estado investigando la transformación de imágenes de cámaras monoculares a vistas a vista de pájaro. Esto se puede hacer mediante el uso de segmentación semántica para clasificar elementos como automóviles, aceras, peatones y el horizonte.
Durante nuestra investigación sobre imágenes monoculares para modelos de aprendizaje profundo BEV, notamos que la información sobre los peatones se perdía durante la segmentación, lo que resultaba en una clasificación deficiente. Como se ve en la imagen a continuación, cuando se evalúa, el modelo que seleccionamos alcanza una media del 25,7 % de IoU (intersección sobre unión) en 14 clases de objetos en el conjunto de datos de nuScenes. La precisión de la predicción para vehículos transitables es buena (74,5%), bastante pobre para bicicletas, barreras y remolques. Sin embargo, la precisión de la predicción para los peatones (9,5%) es demasiado baja. Una precisión tan baja podría provocar accidentes si alguien cruzara la calle sin estar en el cruce.

Puede encontrar más información sobre nuestra investigación en Drive.
Como la mala detección de peatones parecía ser el problema más inmediato con el modelo entrenado actual, nuestro objetivo era mejorar la precisión analizando funciones de pérdida más adecuadas y entrenando el nuevo modelo en el conjunto de datos nuScenes.
El modelo que construimos fue entrenado usando un
Otro problema con
El
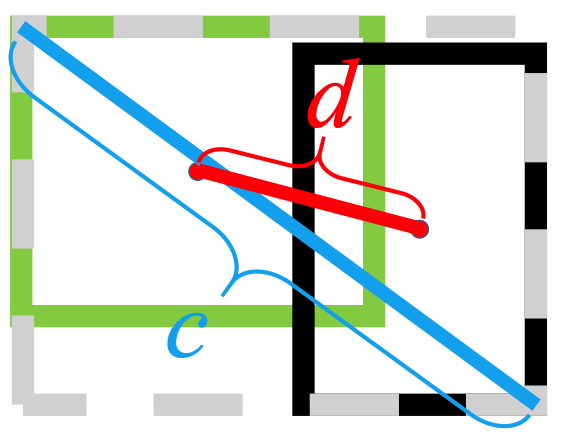
Utiliza la norma L2 para minimizar la distancia entre los cuadros previstos y los de destino, y converge mucho más rápido que

Estiramiento horizontal

Estiramiento vertical
Además, la pérdida de DIoU introduce un término de regularización que fomenta una convergencia fluida.
Como se puede observar en la siguiente imagen, el
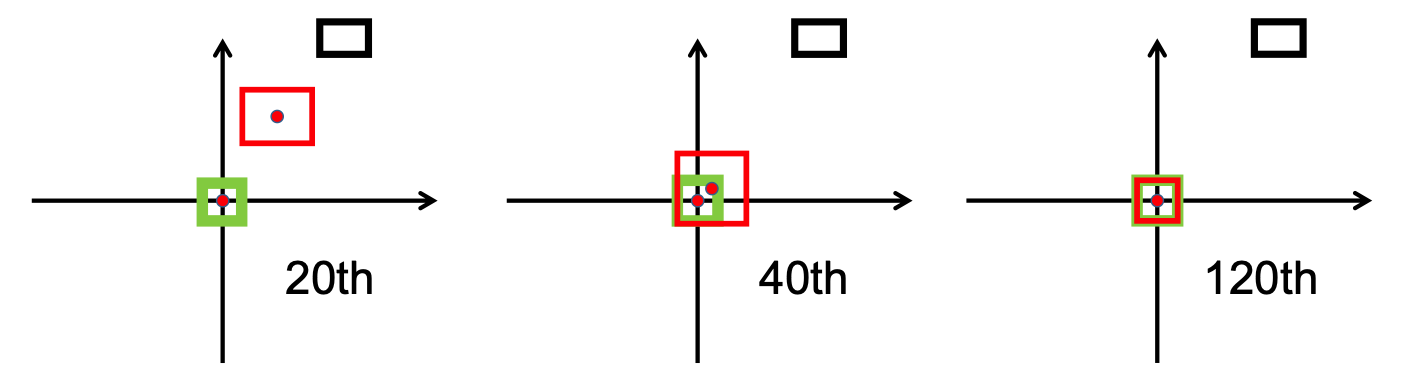
Después de la fase de investigación, implementamos el bbox_overlaps_diou en el archivo /src/utils.py , usando el
Esta función luego se utiliza para calcular multiescala. compute_multiscale_iou del mismo archivo. Para cada clase, el iou ) se calcula sobre el tamaño del lote. La salida de la función es un diccionario iou_dict que contiene la multiescala
Luego usamos estos valores en train.py , donde el val-interval . Estos valores también se usaron en validation.py donde se usaron para mostrar las pérdidas y
Entrenamos el modelo en el conjunto de datos de NuScenes comenzando con el punto de control proporcionado checkpoint-008.pth.gz , una vez con el
Otra contribución es el nuevo formato de visualización para distinguir mejor las clases con todas las etiquetas correspondientes y valores de IoU. Esto se implementó en el archivo visualization.py .
Por último, trabajamos para implementar un modo que tomaría videos .mp4 como entrada y los descompondría en cuadros de imágenes individuales. Luego, el modelo los evaluaría y podríamos visualizar el resultado de la segmentación en el archivo inference.py .
Para tener una idea preliminar de la estrategia de entrenamiento de este modelo, primero decidimos entrenarlo en los mini conjuntos de datos de NuScenes. A partir de checkpoint-008.pth.gz , pudimos entrenar dos modelos diferentes en la métrica de IoU utilizada (IoU para uno y DIoU para el otro). Los resultados obtenidos en un mini lote de NuScenes después de 10 épocas de entrenamiento se presentan en la siguiente tabla.

Después de observar estos resultados, observamos que la clase de peatones en la que basamos nuestra hipótesis no presentó resultados concluyentes en absoluto. Por lo tanto, llegamos a la conclusión de que el miniconjunto de datos no era suficiente para nuestras necesidades y decidimos trasladar nuestra capacitación al conjunto de datos completo en Scitas.
Después de entrenar nuestros nuevos modelos (con DIoU o IoU) desde checkpoint-008.pth.gz durante 8 nuevas épocas, observamos resultados prometedores. Con el objetivo de comparar el rendimiento de estos modelos recién entrenados, realizamos un paso de validación en el mini conjunto de datos. A continuación se proporciona una visualización del resultado de una imagen de este conjunto de datos.
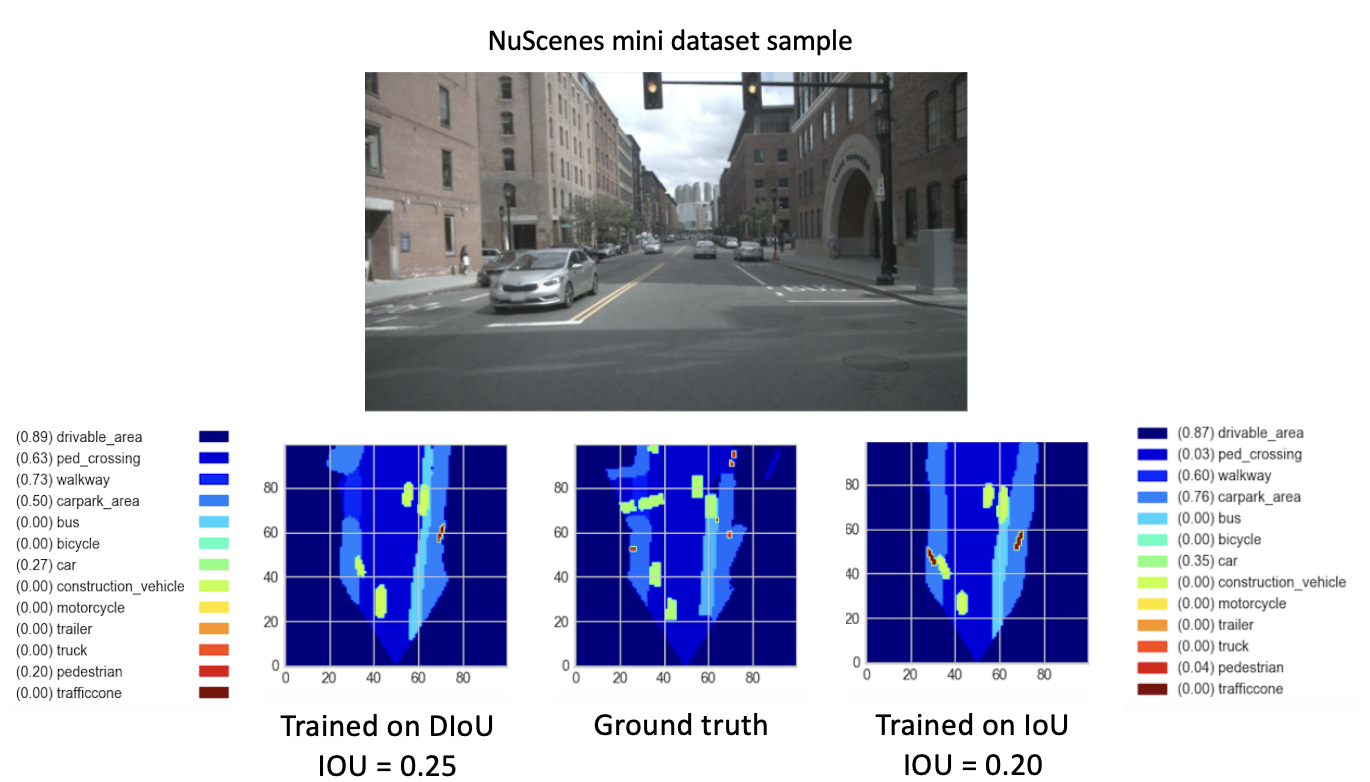
Aquí, el

Estos resultados finalmente muestran un mejor desempeño de la
Ahora que tenemos un modelo entrenado, podemos usarlo para predecir el BEV utilizando imágenes o videos de entrada. Si bien nuestra ambición era implementar nuestro método en la demostración final del curso, desafortunadamente los mapas a vista de pájaro inferidos no fueron lo suficientemente eficaces. La siguiente figura muestra el resultado de la inferencia en uno de los videos de prueba proporcionados (ver videos de prueba).

Creemos que esta falta de desempeño para la inferencia se debe a los siguientes parámetros:
Aunque el paso de
Una opción es implementar
El
Además, según la investigación realizada en este artículo [2], el error de regresión de CIoU se degrada más rápido que el resto y convergerá a
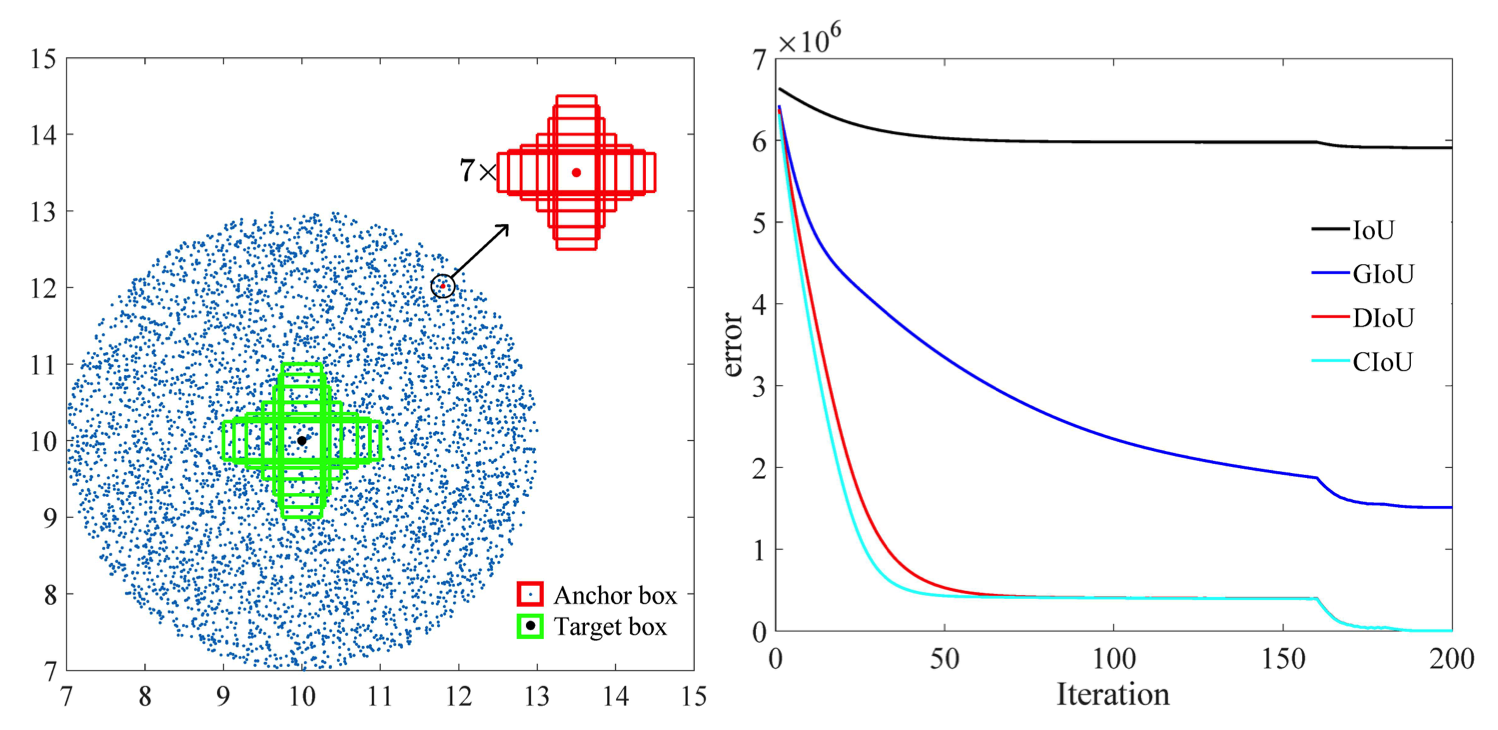
Otra opción es entrenar con conjuntos de datos ricos en entornos concurridos para tener una mejor representación de peatones y bicicletas.
Finalmente, para validar verdaderamente nuestra hipótesis, se podría realizar una ejecución de validación en el conjunto de datos completo de NuScenes y se podrían comparar los IoU peatonales de los dos modelos.
[1] Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, Dongwei Ren (2020). Pérdida de distancia-IoU: aprendizaje mejor y más rápido para la regresión del cuadro delimitador https://arxiv.org/pdf/1911.08287.pdf
[2] Zhaohui Zheng, Ping Wang, Dongwei Ren, Wei Liu, Rongguang Ye, Qinghua Hu, Wangmeng Zuo (2021). Mejora de los factores geométricos en el aprendizaje y la inferencia de modelos para la detección de objetos y la segmentación de instancias https://arxiv.org/pdf/2005.03572.pdf


