tiny cuda nn
Version 1.6
Este es un marco pequeño e independiente para entrenar y consultar redes neuronales. En particular, contiene un perceptrón multicapa "totalmente fusionado" ultrarrápido (documento técnico), una codificación hash multiresolución versátil (documento técnico), así como soporte para otras codificaciones de entrada, pérdidas y optimizadores.
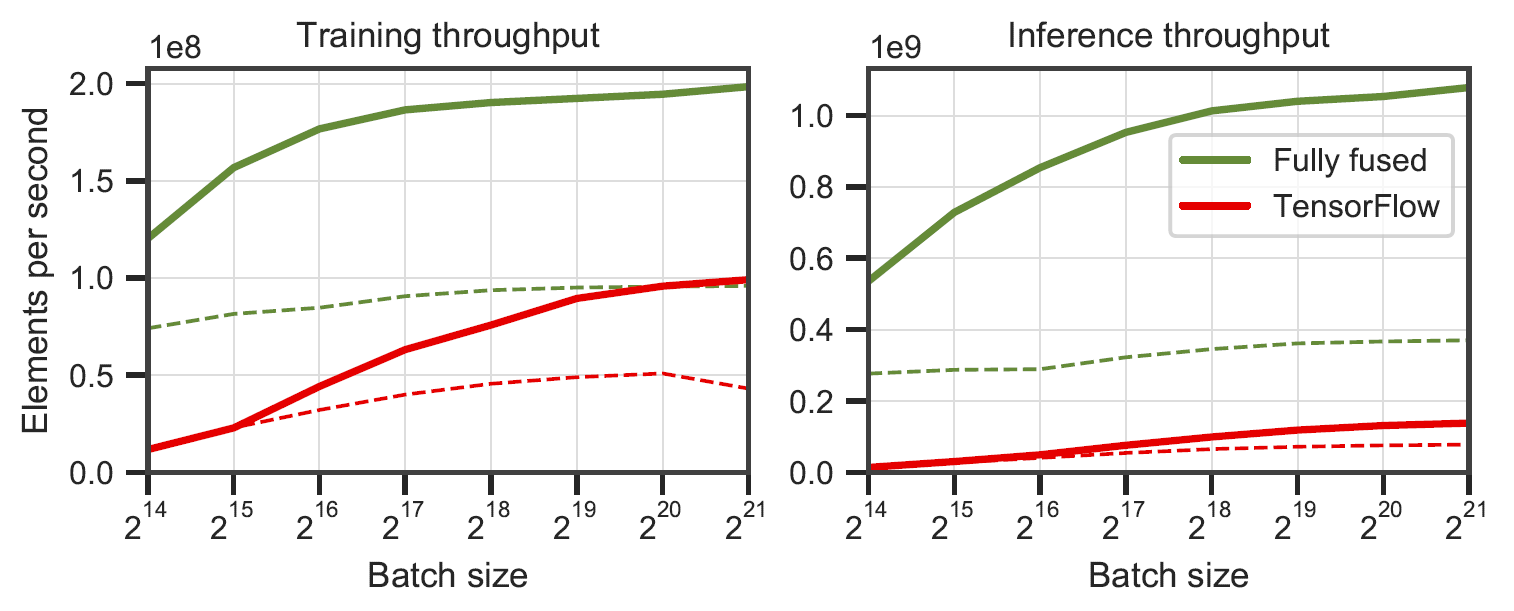 Redes completamente fusionadas frente a TensorFlow v2.5.0 con XLA. Medido en perceptrones multicapa de 64 (línea continua) y 128 (línea discontinua) de neuronas en un RTX 3090. Generado por
Redes completamente fusionadas frente a TensorFlow v2.5.0 con XLA. Medido en perceptrones multicapa de 64 (línea continua) y 128 (línea discontinua) de neuronas en un RTX 3090. Generado por benchmarks/bench_ours.cu y benchmarks/bench_tensorflow.py usando data/config_oneblob.json .
Las pequeñas redes neuronales CUDA tienen una API C++/CUDA simple:
# include < tiny-cuda-nn/common.h >
// Configure the model
nlohmann::json config = {
{ " loss " , {
{ " otype " , " L2 " }
}},
{ " optimizer " , {
{ " otype " , " Adam " },
{ " learning_rate " , 1e-3 },
}},
{ " encoding " , {
{ " otype " , " HashGrid " },
{ " n_levels " , 16 },
{ " n_features_per_level " , 2 },
{ " log2_hashmap_size " , 19 },
{ " base_resolution " , 16 },
{ " per_level_scale " , 2.0 },
}},
{ " network " , {
{ " otype " , " FullyFusedMLP " },
{ " activation " , " ReLU " },
{ " output_activation " , " None " },
{ " n_neurons " , 64 },
{ " n_hidden_layers " , 2 },
}},
};
using namespace tcnn ;
auto model = create_from_config(n_input_dims, n_output_dims, config);
// Train the model (batch_size must be a multiple of tcnn::BATCH_SIZE_GRANULARITY)
GPUMatrix< float > training_batch_inputs (n_input_dims, batch_size);
GPUMatrix< float > training_batch_targets (n_output_dims, batch_size);
for ( int i = 0 ; i < n_training_steps; ++i) {
generate_training_batch (&training_batch_inputs, &training_batch_targets); // <-- your code
float loss;
model. trainer -> training_step (training_batch_inputs, training_batch_targets, &loss);
std::cout << " iteration= " << i << " loss= " << loss << std::endl;
}
// Use the model
GPUMatrix< float > inference_inputs (n_input_dims, batch_size);
generate_inputs (&inference_inputs); // <-- your code
GPUMatrix< float > inference_outputs (n_output_dims, batch_size);
model.network-> inference (inference_inputs, inference_outputs);Proporcionamos una aplicación de muestra donde se aprende una función de imagen (x,y) -> (R,G,B) . Se puede ejecutar a través de
tiny-cuda-nn$ ./build/mlp_learning_an_image data/images/albert.jpg data/config_hash.jsonproduciendo una imagen cada dos pasos de entrenamiento. Cada 1000 pasos debería tomar un poco más de 1 segundo con la configuración predeterminada en un RTX 4090.
| 10 pasos | 100 pasos | 1000 pasos | Imagen de referencia |
|---|---|---|---|
 |  |  |  |
n_neurons o usar CutlassMLP (mejor compatibilidad pero más lento).Si está utilizando Linux, instale los siguientes paquetes
sudo apt-get install build-essential git También recomendamos instalar CUDA en /usr/local/ y agregar la instalación de CUDA a su RUTA. Por ejemplo, si tiene CUDA 11.4, agregue lo siguiente a su ~/.bashrc
export PATH= " /usr/local/cuda-11.4/bin: $PATH "
export LD_LIBRARY_PATH= " /usr/local/cuda-11.4/lib64: $LD_LIBRARY_PATH " Comience clonando este repositorio y todos sus submódulos usando el siguiente comando:
$ git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
$ cd tiny-cuda-nnLuego, use CMake para compilar el proyecto: (en Windows, esto debe estar en el símbolo del sistema del desarrollador)
tiny-cuda-nn$ cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
tiny-cuda-nn$ cmake --build build --config RelWithDebInfo -j Si la compilación falla inexplicablemente o tarda más de una hora, es posible que se esté quedando sin memoria. Intente ejecutar el comando anterior sin -j en ese caso.
tiny-cuda-nn viene con una extensión PyTorch que permite usar MLP rápidos y codificaciones de entrada desde un contexto de Python. Estos enlaces pueden ser significativamente más rápidos que las implementaciones completas de Python; en particular para la codificación hash multiresolución.
No obstante, los gastos generales de Python/PyTorch pueden ser elevados si el tamaño del lote es pequeño. Por ejemplo, con un tamaño de lote de 64k, el ejemplo
mlp_learning_an_imageincluido es ~2 veces más lento a través de PyTorch que CUDA nativo. Con un tamaño de lote de 256k y superior (predeterminado), el rendimiento es mucho más cercano.
Comience configurando un entorno Python 3.X con una versión reciente de PyTorch habilitada para CUDA. Entonces, invoca
pip install git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torchAlternativamente, si desea realizar la instalación desde un clon local de tiny-cuda-nn , invoque
tiny-cuda-nn$ cd bindings/torch
tiny-cuda-nn/bindings/torch$ python setup.py installSi tiene éxito, puede utilizar modelos tiny-cuda-nn como en el siguiente ejemplo:
import commentjson as json
import tinycudann as tcnn
import torch
with open ( "data/config_hash.json" ) as f :
config = json . load ( f )
# Option 1: efficient Encoding+Network combo.
model = tcnn . NetworkWithInputEncoding (
n_input_dims , n_output_dims ,
config [ "encoding" ], config [ "network" ]
)
# Option 2: separate modules. Slower but more flexible.
encoding = tcnn . Encoding ( n_input_dims , config [ "encoding" ])
network = tcnn . Network ( encoding . n_output_dims , n_output_dims , config [ "network" ])
model = torch . nn . Sequential ( encoding , network ) Consulte samples/mlp_learning_an_image_pytorch.py para ver un ejemplo.
A continuación se presenta un resumen de los componentes de este marco. La documentación JSON enumera las opciones de configuración.
| Redes | ||
|---|---|---|
| MLP completamente fusionado | src/fully_fused_mlp.cu | Implementación ultrarrápida de pequeños perceptrones multicapa (MLP). |
| MLP CORTE | src/cutlass_mlp.cu | MLP basado en las rutinas GEMM de CUTLASS. Más lento que el totalmente fusionado, pero maneja redes más grandes y aún así es razonablemente rápido. |
| Codificaciones de entrada | ||
|---|---|---|
| Compuesto | include/tiny-cuda-nn/encodings/composite.h | Permite componer múltiples codificaciones. Puede usarse, por ejemplo, para ensamblar la codificación Neural Radiance Caching [Müller et al. 2021]. |
| Frecuencia | include/tiny-cuda-nn/encodings/frequency.h | NeRF [Mildenhall et al. 2020] codificación posicional aplicada por igual a todas las dimensiones. |
| Red | include/tiny-cuda-nn/encodings/grid.h | Codificación basada en grillas multiresolución entrenables. Utilizado para primitivas de gráficos neuronales instantáneos [Müller et al. 2022]. Las cuadrículas pueden estar respaldadas por tablas hash, almacenamiento denso o almacenamiento en mosaico. |
| Identidad | include/tiny-cuda-nn/encodings/identity.h | Deja los valores intactos. |
| una gota | include/tiny-cuda-nn/encodings/oneblob.h | Del muestreo de importancia neuronal [Müller et al. 2019] y el control neuronal varía [Müller et al. 2020]. |
| Armónicos esféricos | include/tiny-cuda-nn/encodings/spherical_harmonics.h | Una codificación de espacio de frecuencia que es más adecuada para vectores de dirección que para vectores de componentes. |
| TriánguloOla | include/tiny-cuda-nn/encodings/triangle_wave.h | Alternativa de bajo coste a la codificación NeRF. Utilizado en el almacenamiento en caché de radiación neuronal [Müller et al. 2021]. |
| Pérdidas | ||
|---|---|---|
| L1 | include/tiny-cuda-nn/losses/l1.h | Pérdida estándar de L1. |
| Relativo L1 | include/tiny-cuda-nn/losses/l1.h | Pérdida relativa de L1 normalizada por la predicción de la red. |
| MAPA | include/tiny-cuda-nn/losses/mape.h | Error porcentual absoluto medio (MAPE). Lo mismo que Relativo L1, pero normalizado por el objetivo. |
| SMAPE | include/tiny-cuda-nn/losses/smape.h | Error porcentual absoluto medio simétrico (SMAPE). Lo mismo que Relative L1, pero normalizado por la media de la predicción y el objetivo. |
| L2 | include/tiny-cuda-nn/losses/l2.h | Pérdida estándar de L2. |
| L2 relativa | include/tiny-cuda-nn/losses/relative_l2.h | Pérdida relativa de L2 normalizada por la predicción de la red [Lehtinen et al. 2018]. |
| Luminancia relativa L2 | include/tiny-cuda-nn/losses/relative_l2_luminance.h | Igual que el anterior, pero normalizado por la luminancia de la predicción de la red. Solo aplicable cuando la predicción de la red es RGB. Utilizado en el almacenamiento en caché de radiación neuronal [Müller et al. 2021]. |
| Entropía cruzada | include/tiny-cuda-nn/losses/cross_entropy.h | Pérdida de entropía cruzada estándar. Solo aplicable cuando la predicción de la red es un PDF. |
| Diferencia | include/tiny-cuda-nn/losses/variance_is.h | Pérdida de varianza estándar. Solo aplicable cuando la predicción de la red es un PDF. |
| Optimizadores | ||
|---|---|---|
| Adán | include/tiny-cuda-nn/optimizers/adam.h | Implementación de Adam [Kingma y Ba 2014], generalizada a AdaBound [Luo et al. 2019]. |
| Novogrado | include/tiny-cuda-nn/optimizers/lookahead.h | Implementación de Novograd [Ginsburg et al. 2019]. |
| SGD | include/tiny-cuda-nn/optimizers/sgd.h | Descenso de gradiente estocástico estándar (SGD). |
| Champú | include/tiny-cuda-nn/optimizers/shampoo.h | Implementación del optimizador de champú de segundo orden [Gupta et al. 2018] con optimizaciones locales, así como las de Anil et al. [2020]. |
| Promedio | include/tiny-cuda-nn/optimizers/average.h | Envuelve otro optimizador y calcula un promedio lineal de los pesos de las últimas N iteraciones. El promedio se utiliza únicamente para inferencia (no retroalimenta el entrenamiento). |
| por lotes | include/tiny-cuda-nn/optimizers/batched.h | Envuelve otro optimizador, invocando el optimizador anidado una vez cada N pasos en el gradiente promediado. Tiene el mismo efecto que aumentar el tamaño del lote pero solo requiere una cantidad constante de memoria. |
| Compuesto | include/tiny-cuda-nn/optimizers/composite.h | Permite utilizar varios optimizadores en diferentes parámetros. |
| EMA | include/tiny-cuda-nn/optimizers/average.h | Envuelve otro optimizador y calcula una media móvil exponencial de los pesos. El promedio se utiliza únicamente para inferencia (no retroalimenta el entrenamiento). |
| Decaimiento exponencial | include/tiny-cuda-nn/optimizers/exponential_decay.h | Envuelve otro optimizador y realiza una caída de la tasa de aprendizaje exponencial constante por partes. |
| anticipación | include/tiny-cuda-nn/optimizers/lookahead.h | Envuelve otro optimizador, implementando el algoritmo de anticipación [Zhang et al. 2019]. |
Este marco tiene la licencia BSD de 3 cláusulas. Consulte LICENSE.txt para obtener más detalles.
Si lo utiliza en su investigación, le agradeceríamos una cita a través de
@software { tiny-cuda-nn ,
author = { M"uller, Thomas } ,
license = { BSD-3-Clause } ,
month = { 4 } ,
title = { {tiny-cuda-nn} } ,
url = { https://github.com/NVlabs/tiny-cuda-nn } ,
version = { 1.7 } ,
year = { 2021 }
}Para consultas comerciales, visite nuestro sitio web y envíe el formulario: Licencias de investigación de NVIDIA
Entre otros, este marco impulsa las siguientes publicaciones:
Primitivas de gráficos neuronales instantáneos con codificación hash multiresolución
Thomas Müller, Alex Evans, Christoph Schied, Alexander Keller
Transacciones ACM sobre gráficos ( SIGGRAPH ), julio de 2022
Sitio web / Papel / Código / Vídeo / BibTeX
Extracción de modelos, materiales e iluminación triangulares en 3D a partir de imágenes
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas Müller, Sanja Fidler
CVPR (oral) , junio de 2022
Sitio web / Papel / Vídeo / BibTeX
Almacenamiento en caché de radiación neuronal en tiempo real para seguimiento de rutas
Thomas Müller, Fabrice Rousselle, Jan Novák, Alexander Keller
Transacciones ACM sobre gráficos ( SIGGRAPH ), agosto de 2021
Artículo / Charla GTC / Vídeo / Visor interactivo de resultados / BibTeX
Así como el siguiente software:
NerfAcc: una caja de herramientas de aceleración general de NeRF
Ruilong Li, Matthew Tancik, Angjoo Kanazawa
https://github.com/KAIR-BAIR/nerfacc
Nerfstudio: un marco para el desarrollo del campo de radiación neuronal
Matthew Tancik*, Ethan Weber*, Evonne Ng*, Ruilong Li, Brent Yi, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, David McAllister, Angjoo Kanazawa
https://github.com/nerfstudio-project/nerfstudio
No dude en realizar una solicitud de extracción si su publicación o software no figura en la lista.
Un agradecimiento especial a los autores de NRC por sus útiles debates y a Nikolaus Binder por proporcionar parte de la infraestructura de este marco, así como por su ayuda con la utilización de TensorCores desde CUDA.


