

Nuevo robot en la ciudad: SO-100

¡Acabamos de agregar un nuevo tutorial sobre cómo construir un robot más asequible, al precio de $110 por brazo!
Enséñele nuevas habilidades mostrándole algunos movimientos con solo una computadora portátil.
Entonces, ¿observarás cómo tu robot casero actúa de forma autónoma?
Siga el enlace al tutorial completo de SO-100.
LeRobot: IA de última generación para la robótica del mundo real
? LeRobot tiene como objetivo proporcionar modelos, conjuntos de datos y herramientas para la robótica del mundo real en PyTorch. El objetivo es reducir la barrera de entrada a la robótica para que todos puedan contribuir y beneficiarse al compartir conjuntos de datos y modelos previamente entrenados.
? LeRobot contiene enfoques de última generación que se ha demostrado que se transfieren al mundo real con un enfoque en el aprendizaje por imitación y el aprendizaje por refuerzo.
? LeRobot ya proporciona un conjunto de modelos previamente entrenados, conjuntos de datos con demostraciones recopiladas por humanos y entornos de simulación para comenzar sin ensamblar un robot. En las próximas semanas, el plan es agregar cada vez más soporte para la robótica del mundo real en los robots más asequibles y capaces que existen.
? LeRobot aloja modelos y conjuntos de datos previamente entrenados en esta página de la comunidad Hugging Face: huggingface.co/lerobot
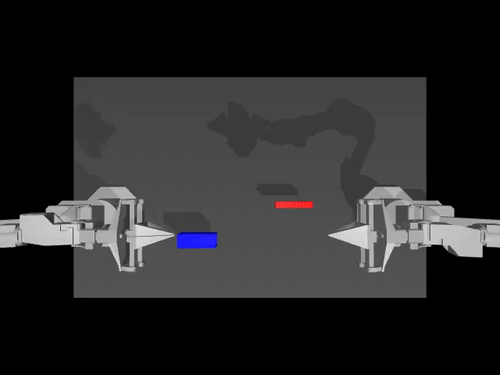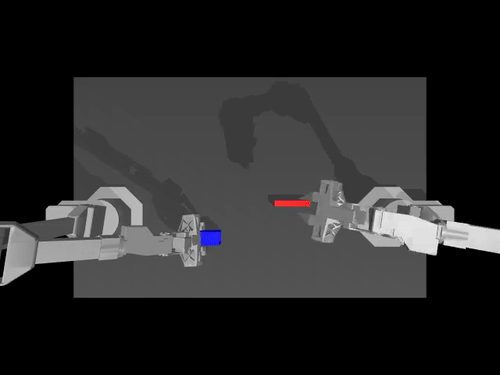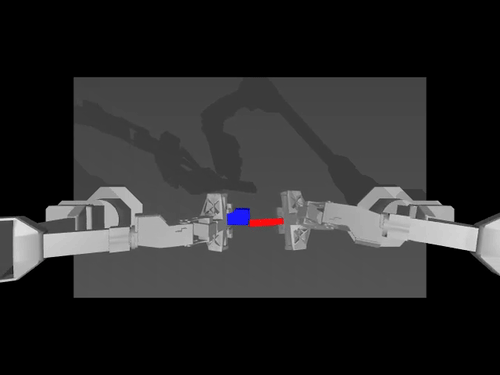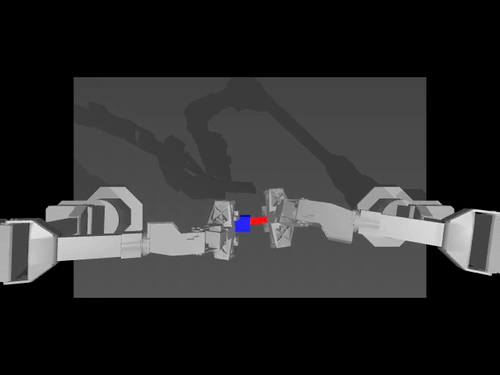 |  |  |
| Política de ACT sobre el medio ambiente ALOHA | Política TDMPC en el entorno SimXArm | Política de difusión sobre el entorno PushT |
Descarga nuestro código fuente:
git clone https://github.com/huggingface/lerobot.git
cd lerobot Cree un entorno virtual con Python 3.10 y actívelo, por ejemplo con miniconda :
conda create -y -n lerobot python=3.10
conda activate lerobotInstalar ? LeRobot:
pip install -e .NOTA: Dependiendo de su plataforma, si encuentra algún error de compilación durante este paso, es posible que deba instalar
cmakeybuild-essentialpara crear algunas de nuestras dependencias. En Linux:sudo apt-get install cmake build-essential
Para simulaciones, ? LeRobot viene con entornos de gimnasio que se pueden instalar como extras:
Por ejemplo, para instalar ? LeRobot con aloha y pusht, usa:
pip install -e " .[aloha, pusht] "Para utilizar pesos y sesgos para el seguimiento de experimentos, inicie sesión con
wandb login(Nota: también deberá habilitar WandB en la configuración. Consulte a continuación).
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, xarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration
Consulte el ejemplo 1 que ilustra cómo utilizar nuestra clase de conjunto de datos que descarga datos automáticamente desde el centro Hugging Face.
También puede visualizar localmente episodios de un conjunto de datos en el centro ejecutando nuestro script desde la línea de comando:
python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 o desde un conjunto de datos en una carpeta local con la variable de entorno raíz DATA_DIR (en el siguiente caso, el conjunto de datos se buscará en ./my_local_data_dir/lerobot/pusht )
DATA_DIR= ' ./my_local_data_dir ' python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 Abrirá rerun.io y mostrará las transmisiones de la cámara, los estados del robot y las acciones, como esta:
Nuestro script también puede visualizar conjuntos de datos almacenados en un servidor distante. Consulte python lerobot/scripts/visualize_dataset.py --help para obtener más instrucciones.
LeRobotDataset Un conjunto de datos en formato LeRobotDataset es muy sencillo de utilizar. Se puede cargar desde un repositorio en el centro de Hugging Face o una carpeta local simplemente con, por ejemplo, dataset = LeRobotDataset("lerobot/aloha_static_coffee") y se puede indexar como cualquier conjunto de datos de Hugging Face y PyTorch. Por ejemplo, dataset[0] recuperará un único marco temporal del conjunto de datos que contiene observaciones y una acción como tensores de PyTorch listos para alimentar un modelo.
Una especificidad de LeRobotDataset es que, en lugar de recuperar un solo fotograma por su índice, podemos recuperar varios fotogramas en función de su relación temporal con el fotograma indexado, configurando delta_timestamps en una lista de tiempos relativos con respecto al fotograma indexado. Por ejemplo, con delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]} se pueden recuperar, para un índice determinado, 4 fotogramas: 3 fotogramas "anteriores" de 1 segundo, 0,5 segundos y 0,2 segundos antes del cuadro indexado y el cuadro indexado en sí (correspondiente a la entrada 0). Consulte el ejemplo 1_load_lerobot_dataset.py para obtener más detalles sobre delta_timestamps .
En esencia, el formato LeRobotDataset utiliza varias formas de serializar datos que pueden resultar útiles si planea trabajar más estrechamente con este formato. Intentamos crear un formato de conjunto de datos flexible pero simple que cubriera la mayoría de los tipos de características y especificidades presentes en el aprendizaje por refuerzo y la robótica, en la simulación y en el mundo real, con un enfoque en cámaras y estados de robots, pero fácilmente extensible a otros tipos de sensores. entradas siempre que puedan representarse mediante un tensor.
Estos son los detalles importantes y la organización de la estructura interna de un LeRobotDataset típico instanciado con dataset = LeRobotDataset("lerobot/aloha_static_coffee") . Las características exactas cambiarán de un conjunto de datos a otro, pero no los aspectos principales:
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
Un LeRobotDataset se serializa utilizando varios formatos de archivo muy extendidos para cada una de sus partes, a saber:
safetensorsafetensor El conjunto de datos se puede cargar/descargar desde el centro de HuggingFace sin problemas. Para trabajar en un conjunto de datos local, puede configurar la variable de entorno DATA_DIR en su carpeta raíz del conjunto de datos como se ilustra en la sección anterior sobre visualización del conjunto de datos.
Consulte el ejemplo 2 que ilustra cómo descargar una política previamente entrenada desde el centro Hugging Face y ejecutar una evaluación en su entorno correspondiente.
También proporcionamos un script más capaz para paralelizar la evaluación en múltiples entornos durante la misma implementación. A continuación se muestra un ejemplo con un modelo previamente entrenado alojado en lerobot/diffusion_pusht:
python lerobot/scripts/eval.py
-p lerobot/diffusion_pusht
eval.n_episodes=10
eval.batch_size=10Nota: Después de entrenar su propia política, puede volver a evaluar los puntos de control con:
python lerobot/scripts/eval.py -p {OUTPUT_DIR}/checkpoints/last/pretrained_model Consulte python lerobot/scripts/eval.py --help para obtener más instrucciones.
Consulte el ejemplo 3 que ilustra cómo entrenar un modelo usando nuestra biblioteca principal en Python y el ejemplo 4 que muestra cómo usar nuestro script de entrenamiento desde la línea de comandos.
En general, puede utilizar nuestro script de capacitación para capacitar fácilmente cualquier política. A continuación se muestra un ejemplo de cómo entrenar la política ACT en trayectorias recopiladas por humanos en el entorno de simulación Aloha para la tarea de inserción:
python lerobot/scripts/train.py
policy=act
env=aloha
env.task=AlohaInsertion-v0
dataset_repo_id=lerobot/aloha_sim_insertion_human El directorio del experimento se genera automáticamente y aparecerá en amarillo en su terminal. Parece outputs/train/2024-05-05/20-21-12_aloha_act_default . Puede especificar manualmente un directorio de experimento agregando este argumento al comando de Python train.py :
hydra.run.dir=your/new/experiment/dir En el directorio del experimento habrá una carpeta llamada checkpoints que tendrá la siguiente estructura:
checkpoints
├── 000250 # checkpoint_dir for training step 250
│ ├── pretrained_model # Hugging Face pretrained model dir
│ │ ├── config.json # Hugging Face pretrained model config
│ │ ├── config.yaml # consolidated Hydra config
│ │ ├── model.safetensors # model weights
│ │ └── README.md # Hugging Face model card
│ └── training_state.pth # optimizer/scheduler/rng state and training step Para reanudar el entrenamiento desde un punto de control, puede agregar estos al comando de Python train.py :
hydra.run.dir=your/original/experiment/dir resume=trueCargará los estados del modelo, optimizador y programador previamente entrenados para el entrenamiento. Para obtener más información, consulte nuestro tutorial sobre la reanudación del entrenamiento aquí.
Para usar wandb para registrar curvas de capacitación y evaluación, asegúrese de haber ejecutado wandb login como un paso de configuración único. Luego, cuando ejecute el comando de entrenamiento anterior, habilite WandB en la configuración agregando:
wandb.enable=trueTambién aparecerá en amarillo en su terminal un enlace a los registros de wandb para la ejecución. A continuación se muestra un ejemplo de cómo se ven en su navegador. Consulte también aquí para obtener la explicación de algunas métricas utilizadas comúnmente en los registros.

Nota: Para mayor eficiencia, durante el entrenamiento, cada punto de control se evalúa en una cantidad baja de episodios. Puede utilizar eval.n_episodes=500 para evaluar más episodios que los predeterminados. O, después del entrenamiento, es posible que desees volver a evaluar tus mejores puntos de control en más episodios o cambiar la configuración de evaluación. Consulte python lerobot/scripts/eval.py --help para obtener más instrucciones.
Hemos organizado nuestros archivos de configuración (que se encuentran en lerobot/configs ) de manera que reproduzcan los resultados SOTA de una variante de modelo determinada en sus respectivos trabajos originales. Simplemente ejecutando:
python lerobot/scripts/train.py policy=diffusion env=pushtreproduce los resultados SOTA para la política de difusión en la tarea PushT.
Las políticas previamente entrenadas, junto con los detalles de reproducción, se pueden encontrar en la sección "Modelos" de https://huggingface.co/lerobot.
Si te gustaría contribuir a ? LeRobot, consulte nuestra guía de contribuciones.
Para agregar un conjunto de datos al centro, debe iniciar sesión utilizando un token de acceso de escritura, que se puede generar desde la configuración de Hugging Face:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential Luego, apunte a la carpeta de su conjunto de datos sin procesar (por ejemplo, data/aloha_static_pingpong_test_raw ) y envíe su conjunto de datos al centro con:
python lerobot/scripts/push_dataset_to_hub.py
--raw-dir data/aloha_static_pingpong_test_raw
--out-dir data
--repo-id lerobot/aloha_static_pingpong_test
--raw-format aloha_hdf5 Consulte python lerobot/scripts/push_dataset_to_hub.py --help para obtener más instrucciones.
Si su formato de conjunto de datos no es compatible, implemente el suyo propio en lerobot/common/datasets/push_dataset_to_hub/${raw_format}_format.py copiando ejemplos como pusht_zarr, umi_zarr, aloha_hdf5 o xarm_pkl.
Una vez que haya entrenado una política, puede cargarla en el centro Hugging Face usando una identificación del centro que se parece a ${hf_user}/${repo_name} (por ejemplo, lerobot/diffusion_pusht).
Primero debe encontrar la carpeta del punto de control ubicada dentro del directorio de su experimento (por ejemplo, outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500 ). Dentro de eso hay un directorio pretrained_model que debe contener:
config.json : una versión serializada de la configuración de la política (siguiendo la configuración de clase de datos de la política).model.safetensors : un conjunto de parámetros torch.nn.Module , guardados en formato Hugging Face Safetensors.config.yaml : una configuración de entrenamiento de Hydra consolidada que contiene las configuraciones de política, entorno y conjunto de datos. La configuración de la política debe coincidir exactamente con config.json . La configuración del entorno es útil para cualquiera que quiera evaluar su política. La configuración del conjunto de datos simplemente sirve como un registro impreso para la reproducibilidad.Para cargarlos en el centro, ejecute lo siguiente:
huggingface-cli upload ${hf_user} / ${repo_name} path/to/pretrained_modelConsulte eval.py para ver un ejemplo de cómo otras personas pueden usar su política.
Un ejemplo de un fragmento de código para perfilar la evaluación de una política:
from torch . profiler import profile , record_function , ProfilerActivity
def trace_handler ( prof ):
prof . export_chrome_trace ( f"tmp/trace_schedule_ { prof . step_num } .json" )
with profile (
activities = [ ProfilerActivity . CPU , ProfilerActivity . CUDA ],
schedule = torch . profiler . schedule (
wait = 2 ,
warmup = 2 ,
active = 3 ,
),
on_trace_ready = trace_handler
) as prof :
with record_function ( "eval_policy" ):
for i in range ( num_episodes ):
prof . step ()
# insert code to profile, potentially whole body of eval_policy function Si quieres puedes citar este trabajo con:
@misc { cadene2024lerobot ,
author = { Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas } ,
title = { LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch } ,
howpublished = " url{https://github.com/huggingface/lerobot} " ,
year = { 2024 }
}Además, si está utilizando alguna arquitectura de políticas, modelos previamente entrenados o conjuntos de datos en particular, se recomienda citar a los autores originales del trabajo tal como aparecen a continuación:
@article { chi2024diffusionpolicy ,
author = { Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song } ,
title = { Diffusion Policy: Visuomotor Policy Learning via Action Diffusion } ,
journal = { The International Journal of Robotics Research } ,
year = { 2024 } ,
} @article { zhao2023learning ,
title = { Learning fine-grained bimanual manipulation with low-cost hardware } ,
author = { Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea } ,
journal = { arXiv preprint arXiv:2304.13705 } ,
year = { 2023 }
} @inproceedings { Hansen2022tdmpc ,
title = { Temporal Difference Learning for Model Predictive Control } ,
author = { Nicklas Hansen and Xiaolong Wang and Hao Su } ,
booktitle = { ICML } ,
year = { 2022 }
} @article { lee2024behavior ,
title = { Behavior generation with latent actions } ,
author = { Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel } ,
journal = { arXiv preprint arXiv:2403.03181 } ,
year = { 2024 }
}

