EasyOCR
v1.7.2
OCR listo para usar con más de 80 idiomas compatibles y todos los scripts de escritura populares, incluidos: latín, chino, árabe, devanagari, cirílico, etc.
Pruebe la demostración en nuestro sitio web
¿Integrado en los espacios Huggingface? utilizando Gradio. Pruebe la demostración web:
24 de septiembre de 2024 - Versión 1.7.2
Leer todas las notas de la versión



Instalar usando pip
Para la última versión estable:
pip install easyocrPara la última versión de desarrollo:
pip install git+https://github.com/JaidedAI/EasyOCR.git Nota 1: Para Windows, primero instale torch y torchvision siguiendo las instrucciones oficiales aquí https://pytorch.org. En el sitio web de pytorch, asegúrese de seleccionar la versión CUDA correcta que tiene. Si desea ejecutar solo en modo CPU, seleccione CUDA = None .
Nota 2: aquí también proporcionamos un Dockerfile.
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )La salida estará en formato de lista, cada elemento representa un cuadro delimitador, el texto detectado y el nivel de confianza, respectivamente.
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)] Nota 1: ['ch_sim','en'] es la lista de idiomas que desea leer. Puede aprobar varios idiomas a la vez, pero no todos los idiomas se pueden utilizar juntos. El inglés es compatible con todos los idiomas y los idiomas que comparten caracteres comunes suelen ser compatibles entre sí.
Nota 2: en lugar de la ruta del archivo chinese.jpg , también puede pasar un objeto de imagen OpenCV (matriz numpy) o un archivo de imagen como bytes. También se acepta una URL a una imagen sin formato.
Nota 3: La línea reader = easyocr.Reader(['ch_sim','en']) es para cargar un modelo en la memoria. Lleva algo de tiempo pero solo es necesario ejecutarlo una vez.
También puede establecer detail=0 para una salida más simple.
reader . readtext ( 'chinese.jpg' , detail = 0 )Resultado:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]Los pesos de los modelos para el idioma elegido se descargarán automáticamente o puede descargarlos manualmente desde el centro de modelos y colocarlos en la carpeta '~/.EasyOCR/model'.
En caso de que no tenga una GPU o que su GPU tenga poca memoria, puede ejecutar el modelo en modo solo CPU agregando gpu=False .
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )Para obtener más información, lea el tutorial y la documentación de API.
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=TruePara conocer el modelo de reconocimiento, lea aquí.
Para el modelo de detección (CRAFT), lea aquí.
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )La idea es poder conectar cualquier modelo de última generación a EasyOCR. Hay muchos genios que intentan crear mejores modelos de detección/reconocimiento, pero nosotros no intentamos ser genios aquí. Sólo queremos que sus obras sean rápidamente accesibles al público... de forma gratuita. (bueno, creemos que la mayoría de los genios quieren que su trabajo cree un impacto positivo lo más rápido/grande posible). El proceso debería ser similar al siguiente diagrama. Las ranuras grises sirven como marcadores de posición para módulos cambiables de color azul claro.
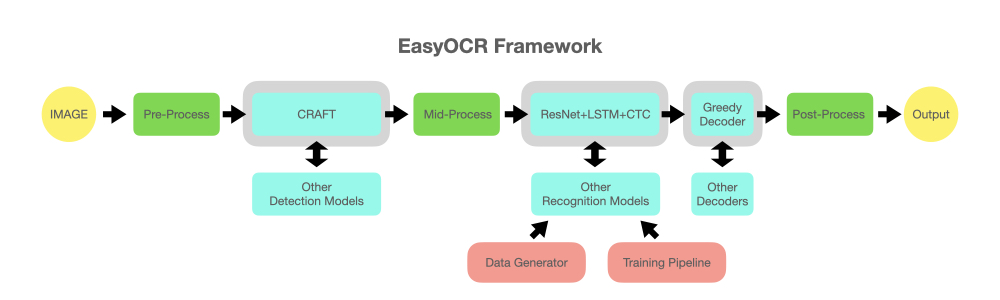
Este proyecto se basa en investigaciones y códigos de varios artículos y repositorios de código abierto.
Toda la ejecución del aprendizaje profundo se basa en Pytorch. ❤️
La ejecución de la detección utiliza el algoritmo CRAFT de este repositorio oficial y su artículo (Gracias @YoungminBaek de @clovaai). También utilizamos su modelo previamente entrenado. El guión de capacitación lo proporciona @gmuffiness.
El modelo de reconocimiento es un CRNN (papel). Se compone de 3 componentes principales: extracción de características (actualmente estamos usando Resnet) y VGG, etiquetado de secuencia (LSTM) y decodificación (CTC). El proceso de capacitación para la ejecución del reconocimiento es una versión modificada del marco de referencia de reconocimiento de texto profundo. (Gracias @ku21fan de @clovaai) Este repositorio es una joya que merece más reconocimiento.
El código de búsqueda de Beam se basa en este repositorio y su blog. (Gracias @githubharald)
La síntesis de datos se basa en TextRecognitionDataGenerator. (Gracias @Belval)
Y una buena lectura sobre CTC en distill.pub aquí.
¡Hagamos avanzar juntos a la humanidad haciendo que la IA esté disponible para todos!
3 formas de contribuir:
Codificador: envíe un PR para pequeños errores o mejoras. Para los más importantes, hable con nosotros abriendo un problema primero. Hay una lista de posibles errores/problemas de mejora etiquetados con 'PR BIENVENIDO'.
Usuario: Cuéntenos cómo EasyOCR le beneficia a usted o a su organización para fomentar un mayor desarrollo. Publique también casos de fallas en la Sección de problemas para ayudar a mejorar los modelos futuros.
Líder tecnológico/Gurú: Si esta biblioteca le resultó útil, ¡corra la voz! (Ver el post de Yann Lecun sobre EasyOCR)
Para solicitar un nuevo idioma, necesitamos que envíe un PR con los 2 archivos siguientes:
Si su idioma tiene elementos únicos (como 1. Árabe: los caracteres cambian de forma cuando se unen entre sí + escriben de derecha a izquierda 2. Tailandés: algunos caracteres deben estar encima de la línea y otros debajo), infórmenos de la mejor manera. de su capacidad y/o proporcionar enlaces útiles. Es importante cuidar el detalle para conseguir un sistema que realmente funcione.
Por último, comprenda que nuestra prioridad tendrá que ir a idiomas populares o conjuntos de idiomas que comparten gran parte de sus caracteres entre sí (díganos también si este es el caso de su idioma). Nos lleva al menos una semana desarrollar un nuevo modelo, por lo que es posible que tengas que esperar un poco hasta que se lance el nuevo modelo.
Ver Lista de idiomas en desarrollo
Debido a recursos limitados, un problema de más de 6 meses se cerrará automáticamente. Abra un problema nuevamente si es crítico.
Para soporte empresarial, Jaided AI ofrece un servicio completo para sistemas OCR/AI personalizados desde la implementación, capacitación/ajuste y despliegue. Haga clic aquí para contactarnos.


