LVBench
1.0.0
[Página del proyecto] [Papel arXiv] [Conjunto de datos][? Tabla de clasificación][? Tabla de clasificación de Huggingface]
LVBench es un punto de referencia diseñado para evaluar y mejorar las capacidades de los modelos multimodales para comprender y extraer información de videos largos de hasta dos horas de duración.
2024.08.2 ¡Configuramos la tabla de clasificación de LVBench en Huggingface Spaces! Consulta la tabla de clasificación.
2024.06.11 Lanzamos LVBench, ¡un nuevo punto de referencia para la comprensión de videos largos!
LVBench es un punto de referencia diseñado para evaluar las capacidades de los modelos para comprender videos largos. Recopilamos datos extensos y extensos de videos de fuentes públicas, anotados mediante una combinación de esfuerzo manual y asistencia del modelo. Nuestro punto de referencia proporciona una base sólida para probar modelos en contextos temporales extendidos, garantizando una evaluación de alta calidad a través de meticulosas anotaciones humanas y un control de calidad de varias etapas.
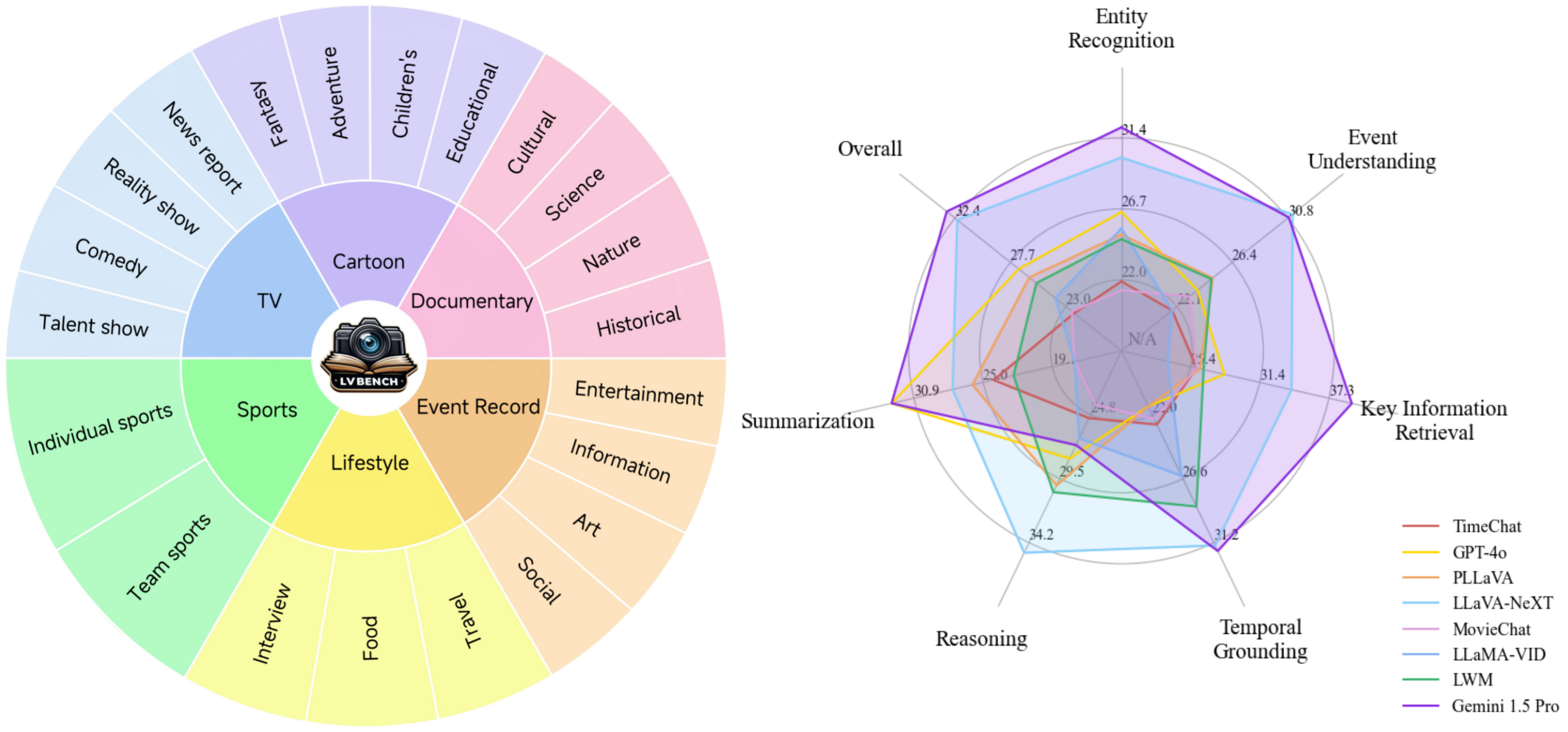
Capacidades principales : Seis capacidades principales para la comprensión de videos extensos, lo que permite la creación de preguntas complejas y desafiantes para una evaluación integral del modelo.
Datos diversos : una gama diversa de datos de vídeo largos, con un promedio cinco veces más largo que los conjuntos de datos más largos existentes, que cubren varias categorías.
Anotaciones de alta calidad : punto de referencia confiable con meticulosas anotaciones humanas y procesos de control de calidad de varias etapas.

Nuestro conjunto de datos está bajo la licencia CC-BY-NC-SA-4.0.
LVBench sólo se utiliza para investigaciones académicas. El uso comercial en cualquier forma está prohibido. No poseemos los derechos de autor de ningún archivo de video sin procesar.
Si hay alguna infracción en LVBench, comuníquese con [email protected] o plantee un problema directamente y lo eliminaremos de inmediato.
Instale video2dataset primero:
pip instalar video2dataset pip desinstalar motor-transformador
Luego deberías descargar video_info.meta.jsonl de Huggingface y colocarlo en el directorio data .
Cada entrada en el archivo video_info.meta.jsonl tiene un campo clave correspondiente al ID de un video de YouTube. Los usuarios pueden descargar el vídeo correspondiente utilizando esta ID. Alternativamente, los usuarios pueden usar el script de descarga que proporcionamos, download.sh, para descargar:
guiones de cd descargar bash.sh
Después de la ejecución, los archivos de video se almacenarán en el directorio script/videos .
instalación de pip -e.
(Nota: si desea probar la evaluación rápidamente, puede utilizar scripts/construct_random_answers.py para preparar un archivo de respuestas aleatorio).
guiones de cd Python test_acc.py
Después de la ejecución, obtendrá un archivo de resultados de evaluación result.json en el directorio scripts . Puede enviar los resultados a la tabla de clasificación.
Comparación de modelos:
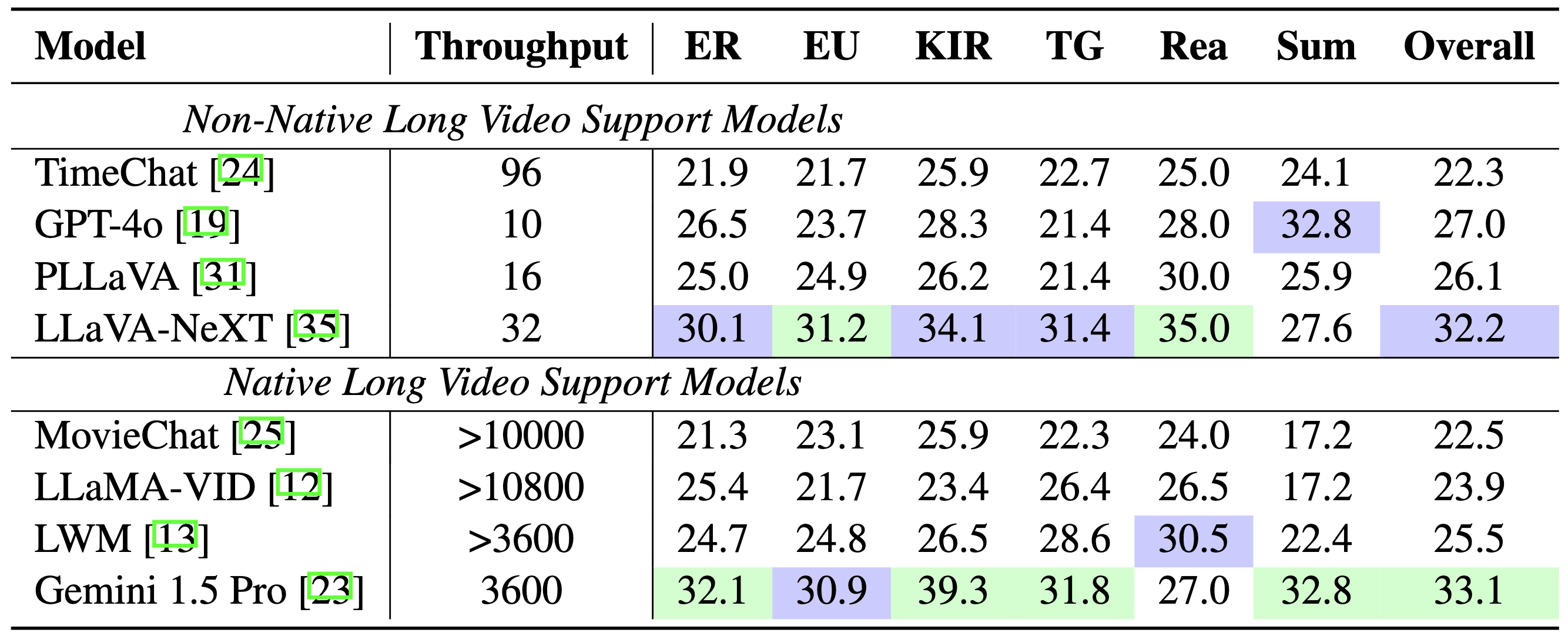
Comparación de referencia:
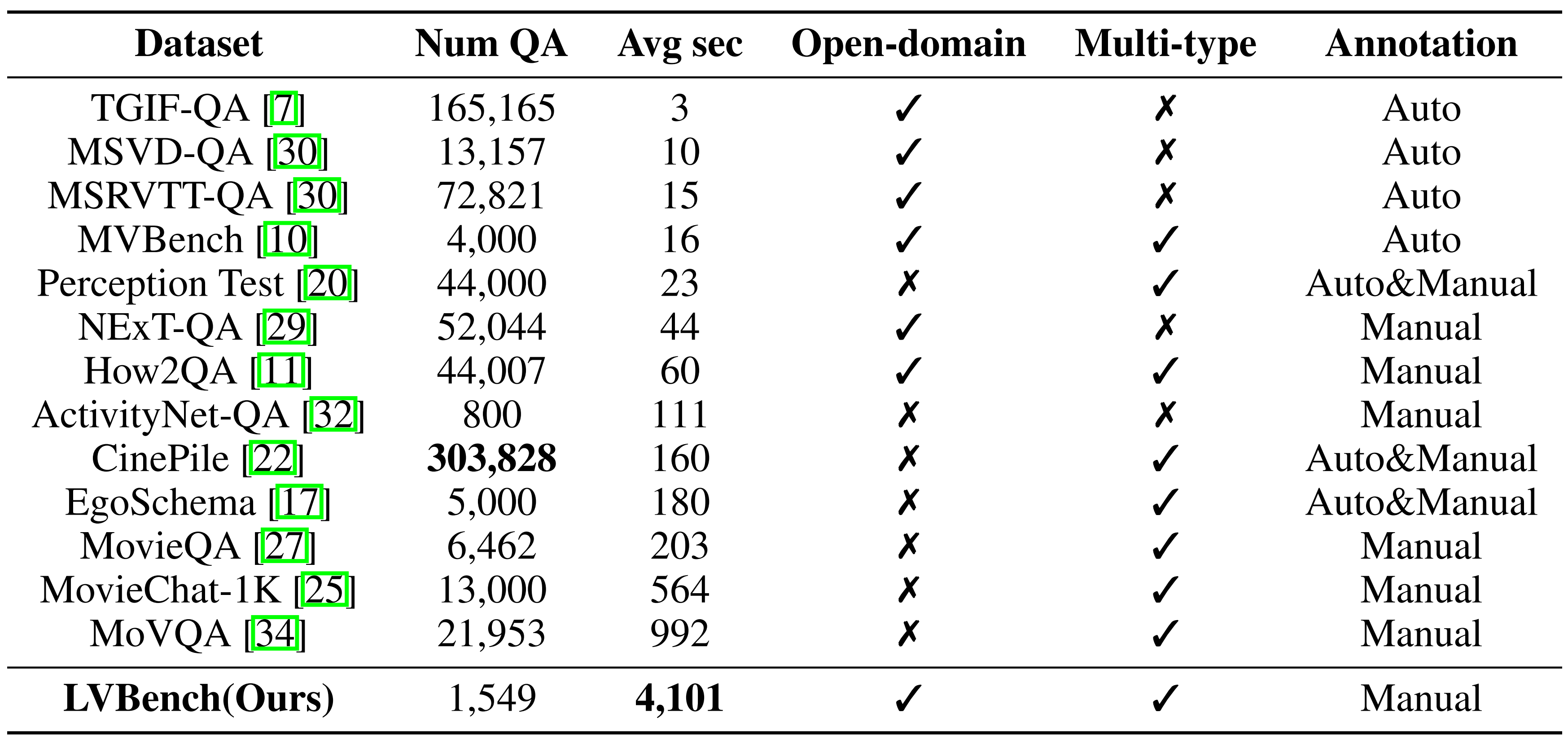
Modelo versus humano:

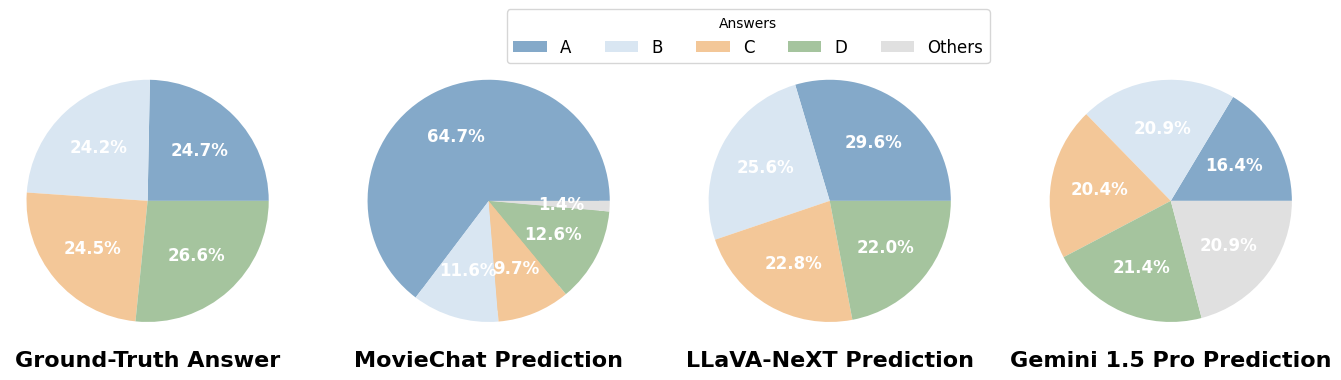
Distribución de respuestas:
Si encuentra nuestro trabajo útil para su investigación, considere citarlo.
@misc{wang2024lvbench, title={LVBench: un punto de referencia de comprensión de vídeos extremadamente largo},
autor={Weihan Wang y Zehai He y Wenyi Hong y Yean Cheng y Xiaohan Zhang y Ji Qi y Shiyu Huang y Bin Xu y Yuxiao Dong y Ming Ding y Jie Tang}, año={2024}, eprint={2406.08035}, archivePrefix ={arXiv}, clase primaria={cs.CV}} 

