Una herramienta para la extensión del tesauro que utiliza métodos de propagación de etiquetas. A partir de un corpus de texto y un tesauro existente, genera sugerencias para ampliar los conjuntos de sinónimos existentes. Esta herramienta fue desarrollada durante la tesis de maestría " Propagación de etiquetas para la extensión del tesauro de derecho tributario " en la Cátedra "Ingeniería de software para sistemas de información empresarial (sebis)", Universidad Técnica de Munich (TUM).
Resumen de tesis. Con el auge de la digitalización, la recuperación de información tiene que hacer frente a cantidades cada vez mayores de contenido digitalizado. Los proveedores de contenidos legales invierten mucho dinero en la creación de ontologías de dominios específicos, como tesauros, para recuperar un número significativamente mayor de documentos relevantes. Desde 2002, se han desarrollado muchos métodos de propagación de etiquetas, por ejemplo, para identificar grupos de nodos similares en gráficos. La propagación de etiquetas es una familia de algoritmos de aprendizaje automático semisupervisados basados en gráficos. En esta tesis, probaremos la idoneidad de los métodos de propagación de etiquetas para ampliar un tesauro del dominio del derecho tributario. El gráfico en el que opera la propagación de etiquetas es un gráfico de similitud construido a partir de incrustaciones de palabras. Cubrimos el proceso de principio a fin y realizamos varios estudios de parámetros para comprender el impacto de ciertos hiperparámetros en el rendimiento general. Luego, los resultados se evalúan en estudios manuales y se comparan con un enfoque de referencia.
La herramienta se implementó utilizando la siguiente arquitectura de tuberías y filtros:
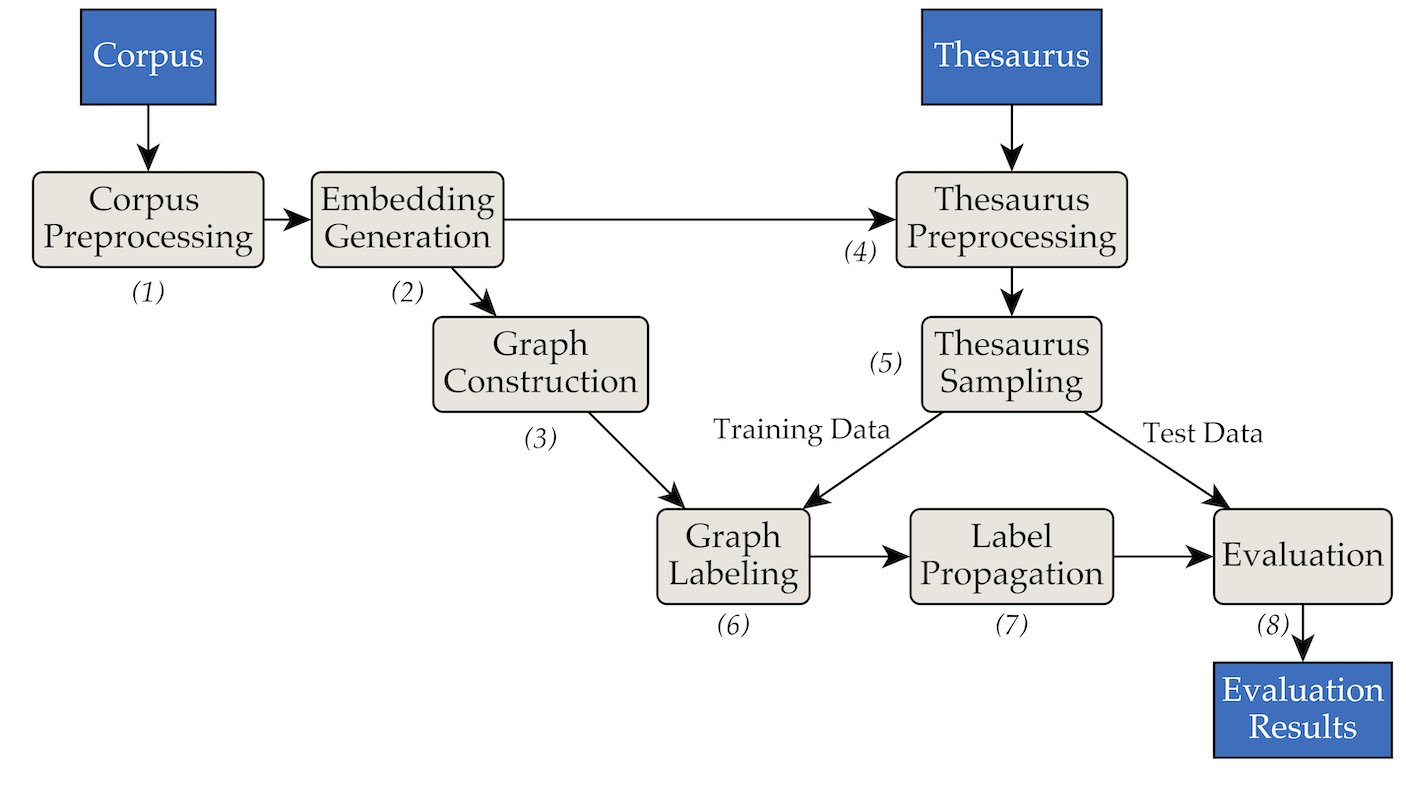
pipenv (Guía de instalación).pipenv install . data/RW40jsons y el diccionario de sinónimos en data/german_relat_pretty-20180605.json . Consulte fase1.py y fase4.py para obtener información sobre los formatos de archivo esperados.output/<PHASE_FOLDER>/<DATE> . Los más importantes son 08_propagation_evaluation y XX_runs . En 08_propagation_evaluation , las estadísticas de evaluación se almacenan como stats.json junto con una tabla que contiene predicciones, entrenamiento y conjunto de pruebas ( main.txt , en otros scripts a menudo denominado df_evaluation ). En XX_runs , se almacena el registro de una ejecución. Si se activaron varias ejecuciones a través de multi_runs.py (cada una con un conjunto de entrenamiento/prueba diferente), las estadísticas combinadas de todas las ejecuciones individuales también se almacenan como all_stats.json . A través de purew2v_parameter_studies.py, se puede ejecutar la línea base del vector synset que introdujimos en nuestra tesis. Requiere un conjunto de incrustaciones de palabras y una o varias divisiones de entrenamiento/prueba de tesauro. Consulte sample_commands.md para ver un ejemplo.
En ipynbs , proporcionamos algunos cuadernos de Jupyter ejemplares que se utilizaron para generar (a) estadísticas, (b) diagramas y (c) archivos de Excel para las evaluaciones manuales. Puede explorarlos ejecutando pipenv shell y luego iniciando Jupyter con jupyter notebook .
main.py o multi_run.py .

