Curso de modelo de lenguaje grande
? Sígueme en X • ? Cara de abrazo • Blog • ? GNN práctico
El curso LLM se divide en tres partes:
- ? LLM Fundamentals cubre conocimientos esenciales sobre matemáticas, Python y redes neuronales.
- ?? El LLM Scientist se enfoca en crear los mejores LLM posibles utilizando las últimas técnicas.
- ? El ingeniero LLM se enfoca en crear aplicaciones basadas en LLM e implementarlas.
Para una versión interactiva de este curso, creé dos asistentes de LLM que responderán preguntas y pondrán a prueba tus conocimientos de forma personalizada:
- ? Asistente HuggingChat : versión gratuita que utiliza Mixtral-8x7B.
- ? Asistente ChatGPT : Requiere una cuenta premium.
Cuadernos
Una lista de cuadernos y artículos relacionados con modelos de lenguaje grandes.
Herramientas
| Computadora portátil | Descripción | Computadora portátil |
|---|
| ? LLM AutoEval | Evalúe automáticamente sus LLM usando RunPod | |
| ? LazyMergekit | Fusione modelos fácilmente usando MergeKit con un solo clic. | |
| ? LazyAxolotl | Ajuste modelos en la nube usando Axolotl con un solo clic. | |
| ⚡ Cuantificación automática | Cuantice LLM en formatos GGUF, GPTQ, EXL2, AWQ y HQQ con un solo clic. | |
| ? Modelo de árbol genealógico | Visualice el árbol genealógico de los modelos fusionados. | |
| Espacio Cero | Cree automáticamente una interfaz de chat de Gradio utilizando una ZeroGPU gratuita. | |
Sintonia FINA
| Computadora portátil | Descripción | Artículo | Computadora portátil |
|---|
| Afina Llama 2 con QLoRA | Guía paso a paso para realizar un ajuste supervisado de Llama 2 en Google Colab. | Artículo | |
| Ajusta CodeLlama usando Axolotl | Guía completa de la herramienta de última generación para realizar ajustes. | Artículo | |
| Afinar Mistral-7b con QLoRA | Supervisé el ajuste de Mistral-7b en un Google Colab de nivel gratuito con TRL. | | |
| Afinar Mistral-7b con DPO | Aumente el rendimiento de los modelos supervisados y ajustados con DPO. | Artículo | |
| Afina Llama 3 con ORPO | Ajustes más baratos y rápidos en una sola etapa con ORPO. | Artículo | |
| Afina Llama 3.1 con Unsloth | Ajuste supervisado ultraeficiente en Google Colab. | Artículo | |
Cuantización
| Computadora portátil | Descripción | Artículo | Computadora portátil |
|---|
| Introducción a la cuantización | Optimización de modelos de lenguaje grande mediante cuantificación de 8 bits. | Artículo | |
| Cuantización de 4 bits usando GPTQ | Cuantifique sus propios LLM de código abierto para ejecutarlos en hardware de consumo. | Artículo | |
| Cuantización con GGUF y llama.cpp | Cuantice los modelos Llama 2 con llama.cpp y cargue las versiones GGUF al HF Hub. | Artículo | |
| ExLlamaV2: la biblioteca más rápida para ejecutar LLM | Cuantice y ejecute modelos EXL2 y cárguelos en el HF Hub. | Artículo | |
Otro
| Computadora portátil | Descripción | Artículo | Computadora portátil |
|---|
| Estrategias de decodificación en modelos de lenguaje grandes | Una guía para la generación de texto desde la búsqueda de haces hasta el muestreo de núcleos. | Artículo | |
| Mejore ChatGPT con gráficos de conocimiento | Aumente las respuestas de ChatGPT con gráficos de conocimiento. | Artículo | |
| Fusionar LLM con MergeKit | Crea tus propios modelos fácilmente, ¡no se requiere GPU! | Artículo | |
| Crea MoE con MergeKit | Combine varios expertos en un solo frankenMoE | Artículo | |
| Sin censura cualquier LLM con abliteración | Ajuste fino sin reentrenamiento | Artículo | |
? Fundamentos del LLM
Esta sección presenta conocimientos esenciales sobre matemáticas, Python y redes neuronales. Es posible que no desee comenzar aquí, pero consúltelo según sea necesario.
Alternar sección
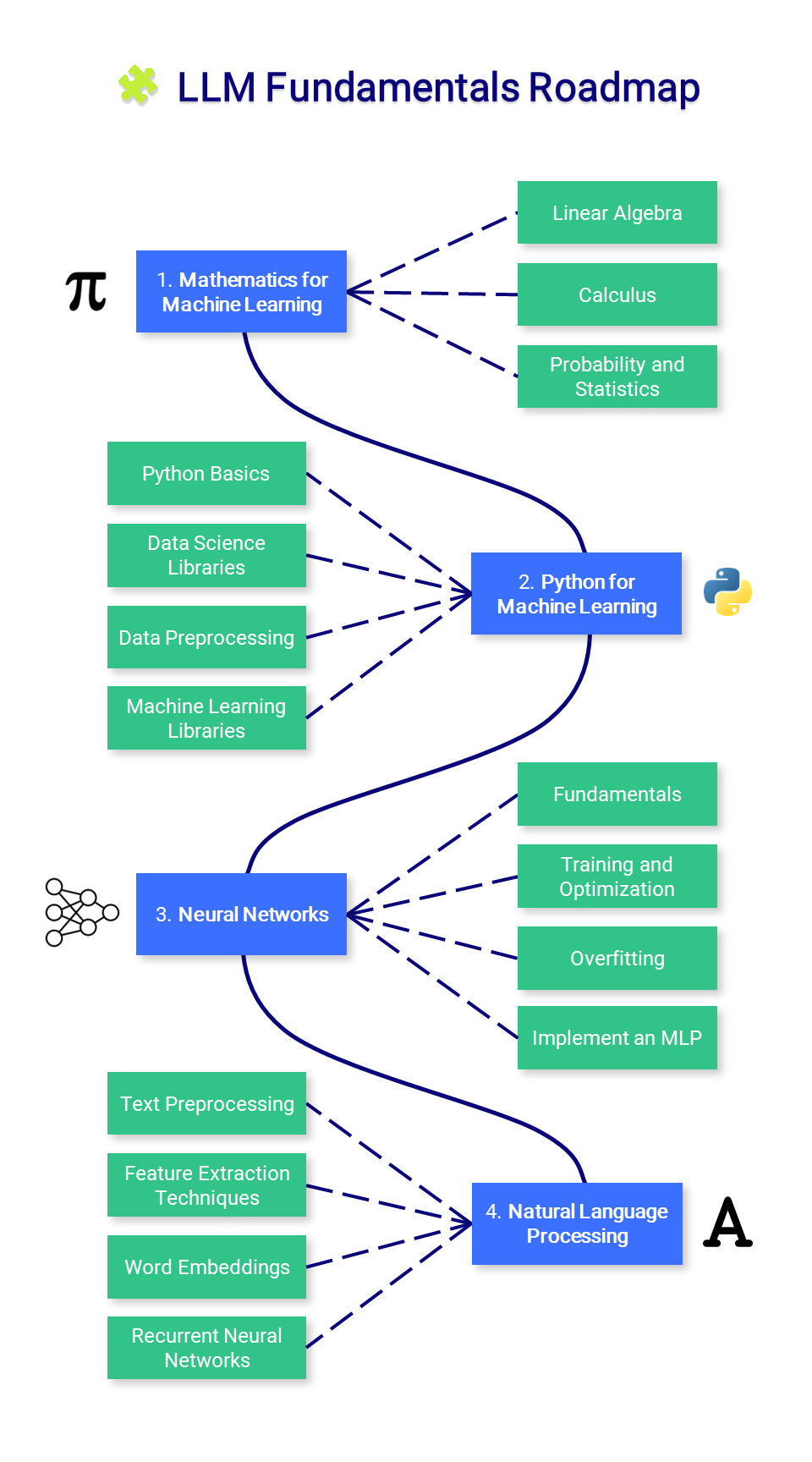
1. Matemáticas para el aprendizaje automático
Antes de dominar el aprendizaje automático, es importante comprender los conceptos matemáticos fundamentales que impulsan estos algoritmos.
- Álgebra lineal : esto es crucial para comprender muchos algoritmos, especialmente los utilizados en el aprendizaje profundo. Los conceptos clave incluyen vectores, matrices, determinantes, valores propios y vectores propios, espacios vectoriales y transformaciones lineales.
- Cálculo : muchos algoritmos de aprendizaje automático implican la optimización de funciones continuas, lo que requiere una comprensión de derivadas, integrales, límites y series. También son importantes el cálculo multivariable y el concepto de gradientes.
- Probabilidad y estadística : son cruciales para comprender cómo los modelos aprenden de los datos y hacen predicciones. Los conceptos clave incluyen teoría de la probabilidad, variables aleatorias, distribuciones de probabilidad, expectativas, varianza, covarianza, correlación, prueba de hipótesis, intervalos de confianza, estimación de máxima verosimilitud e inferencia bayesiana.
Recursos:
- 3Blue1Brown - La Esencia del Álgebra Lineal: Serie de videos que dan una intuición geométrica a estos conceptos.
- StatQuest con Josh Starmer - Fundamentos de estadística: ofrece explicaciones sencillas y claras para muchos conceptos estadísticos.
- AP Statistics Intuition por la Sra. Aerin: Lista de artículos de Medium que brindan la intuición detrás de cada distribución de probabilidad.
- Álgebra lineal inmersiva: otra interpretación visual del álgebra lineal.
- Khan Academy - Álgebra lineal: Ideal para principiantes ya que explica los conceptos de una manera muy intuitiva.
- Khan Academy - Cálculo: un curso interactivo que cubre todos los conceptos básicos del cálculo.
- Khan Academy - Probabilidad y estadística: entrega el material en un formato fácil de entender.
2. Python para el aprendizaje automático
Python es un lenguaje de programación potente y flexible que es particularmente bueno para el aprendizaje automático, gracias a su legibilidad, coherencia y ecosistema sólido de bibliotecas de ciencia de datos.
- Conceptos básicos de Python : la programación en Python requiere una buena comprensión de la sintaxis básica, los tipos de datos, el manejo de errores y la programación orientada a objetos.
- Bibliotecas de ciencia de datos : incluye familiaridad con NumPy para operaciones numéricas, Pandas para manipulación y análisis de datos, Matplotlib y Seaborn para visualización de datos.
- Preprocesamiento de datos : esto implica escalado y normalización de funciones, manejo de datos faltantes, detección de valores atípicos, codificación de datos categóricos y división de datos en conjuntos de entrenamiento, validación y prueba.
- Bibliotecas de aprendizaje automático : es vital dominar Scikit-learn, una biblioteca que proporciona una amplia selección de algoritmos de aprendizaje supervisados y no supervisados. Es importante comprender cómo implementar algoritmos como la regresión lineal, la regresión logística, los árboles de decisión, los bosques aleatorios, los k vecinos más cercanos (K-NN) y la agrupación de K-medias. Las técnicas de reducción de dimensionalidad como PCA y t-SNE también son útiles para visualizar datos de alta dimensión.
Recursos:
- Real Python: un recurso completo con artículos y tutoriales para conceptos de Python tanto principiantes como avanzados.
- freeCodeCamp - Aprenda Python: vídeo largo que proporciona una introducción completa a todos los conceptos básicos de Python.
- Manual de ciencia de datos de Python: libro digital gratuito que es un gran recurso para aprender sobre pandas, NumPy, Matplotlib y Seaborn.
- freeCodeCamp - Aprendizaje automático para todos: Introducción práctica a diferentes algoritmos de aprendizaje automático para principiantes.
- Udacity: Introducción al aprendizaje automático: curso gratuito que cubre PCA y varios otros conceptos de aprendizaje automático.
3. Redes neuronales
Las redes neuronales son una parte fundamental de muchos modelos de aprendizaje automático, particularmente en el ámbito del aprendizaje profundo. Para utilizarlos de manera efectiva, es esencial una comprensión integral de su diseño y mecánica.
- Fundamentos : esto incluye comprender la estructura de una red neuronal, como capas, pesos, sesgos y funciones de activación (sigmoide, tanh, ReLU, etc.)
- Entrenamiento y optimización : familiarícese con la retropropagación y los diferentes tipos de funciones de pérdida, como el error cuadrático medio (MSE) y la entropía cruzada. Comprenda varios algoritmos de optimización como Gradient Descent, Stochastic Gradient Descent, RMSprop y Adam.
- Sobreajuste : comprenda el concepto de sobreajuste (donde un modelo funciona bien con datos de entrenamiento pero mal con datos invisibles) y aprenda varias técnicas de regularización (abandono, regularización L1/L2, detención temprana, aumento de datos) para evitarlo.
- Implementar un perceptrón multicapa (MLP) : cree un MLP, también conocido como red totalmente conectada, utilizando PyTorch.
Recursos:
- 3Blue1Brown - ¿Pero qué es una red neuronal?: Este vídeo ofrece una explicación intuitiva de las redes neuronales y su funcionamiento interno.
- freeCodeCamp: curso intensivo de aprendizaje profundo: este video presenta de manera eficiente todos los conceptos más importantes del aprendizaje profundo.
- Fast.ai - Aprendizaje profundo práctico: curso gratuito diseñado para personas con experiencia en codificación que desean aprender sobre el aprendizaje profundo.
- Patrick Loeber - Tutoriales de PyTorch: Serie de videos para principiantes para aprender sobre PyTorch.
4. Procesamiento del lenguaje natural (PNL)
La PNL es una rama fascinante de la inteligencia artificial que cierra la brecha entre el lenguaje humano y la comprensión de las máquinas. Desde el simple procesamiento de texto hasta la comprensión de matices lingüísticos, la PNL desempeña un papel crucial en muchas aplicaciones como traducción, análisis de sentimientos, chatbots y mucho más.
- Preprocesamiento de texto : aprenda varios pasos de preprocesamiento de texto, como tokenización (dividir el texto en palabras u oraciones), derivación (reducir las palabras a su forma raíz), lematización (similar a la derivación pero considera el contexto), eliminación de palabras, etc.
- Técnicas de extracción de funciones : familiarícese con las técnicas para convertir datos de texto a un formato que pueda entenderse mediante algoritmos de aprendizaje automático. Los métodos clave incluyen bolsa de palabras (BoW), frecuencia de términos-frecuencia de documentos inversa (TF-IDF) y n-gramas.
- Incrustaciones de palabras : las incrustaciones de palabras son un tipo de representación de palabras que permite que palabras con significados similares tengan representaciones similares. Los métodos clave incluyen Word2Vec, GloVe y FastText.
- Redes neuronales recurrentes (RNN) : comprenda el funcionamiento de las RNN, un tipo de red neuronal diseñada para trabajar con datos de secuencia. Explore LSTM y GRU, dos variantes de RNN que son capaces de aprender dependencias a largo plazo.
Recursos:
- RealPython - PNL con spaCy en Python: Guía exhaustiva sobre la biblioteca spaCy para tareas de PNL en Python.
- Kaggle - Guía de PNL: algunos cuadernos y recursos para una explicación práctica de PNL en Python.
- Jay Alammar - La Ilustración Word2Vec: Una buena referencia para entender la famosa arquitectura Word2Vec.
- Jake Tae - PyTorch RNN desde cero: implementación práctica y sencilla de modelos RNN, LSTM y GRU en PyTorch.
- Blog de colah: Comprensión de las redes LSTM: un artículo más teórico sobre la red LSTM.
?? El científico del LLM
Esta sección del curso se centra en aprender cómo crear los mejores LLM posibles utilizando las últimas técnicas.
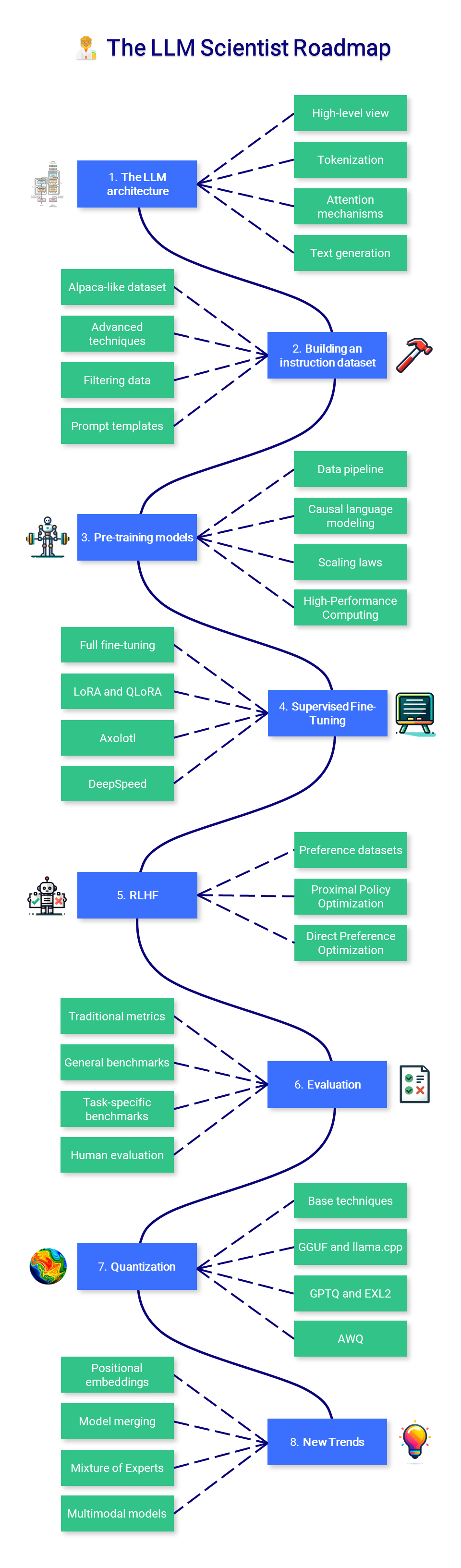
1. La arquitectura del LLM
Si bien no se requiere un conocimiento profundo sobre la arquitectura Transformer, es importante tener una buena comprensión de sus entradas (tokens) y salidas (logits). El mecanismo básico de atención es otro componente crucial que hay que dominar, ya que más adelante se introducirán versiones mejoradas del mismo.
- Vista de alto nivel : revise la arquitectura Transformer codificador-decodificador y, más específicamente, la arquitectura GPT solo decodificador, que se utiliza en todos los LLM modernos.
- Tokenización : comprenda cómo convertir datos de texto sin formato a un formato que el modelo pueda comprender, lo que implica dividir el texto en tokens (generalmente palabras o subpalabras).
- Mecanismos de atención : comprenda la teoría detrás de los mecanismos de atención, incluida la autoatención y la atención del producto escalado, que permite que el modelo se centre en diferentes partes de la entrada al producir una salida.
- Generación de texto : conozca las diferentes formas en que el modelo puede generar secuencias de salida. Las estrategias comunes incluyen decodificación codiciosa, búsqueda de haces, muestreo top-k y muestreo de núcleos.
Referencias :
- The Illustrated Transformer de Jay Alammar: una explicación visual e intuitiva del modelo Transformer.
- El GPT-2 ilustrado por Jay Alammar: Aún más importante que el artículo anterior, se centra en la arquitectura GPT, que es muy similar a la de Llama.
- Introducción visual a Transformers por 3Blue1Brown: Introducción visual simple y fácil de entender a Transformers
- LLM Visualization de Brendan Bycroft: Increíble visualización en 3D de lo que sucede dentro de un LLM.
- nanoGPT de Andrej Karpathy: un vídeo de YouTube de 2 horas de duración para reimplementar GPT desde cero (para programadores).
- ¿Atención? ¡Atención! por Lilian Weng: Introducir la necesidad de atención de una manera más formal.
- Estrategias de decodificación en LLM: proporcione código y una introducción visual a las diferentes estrategias de decodificación para generar texto.
2. Construyendo un conjunto de datos de instrucciones
Si bien es fácil encontrar datos sin procesar en Wikipedia y otros sitios web, es difícil recopilar pares de instrucciones y respuestas en la naturaleza. Al igual que en el aprendizaje automático tradicional, la calidad del conjunto de datos influirá directamente en la calidad del modelo, por lo que podría ser el componente más importante en el proceso de ajuste.
- Conjunto de datos tipo alpaca : genere datos sintéticos desde cero con la API OpenAI (GPT). Puede especificar semillas y mensajes del sistema para crear un conjunto de datos diverso.
- Técnicas avanzadas : aprenda cómo mejorar los conjuntos de datos existentes con Evol-Instruct, cómo generar datos sintéticos de alta calidad como en los artículos de Orca y phi-1.
- Filtrado de datos : técnicas tradicionales que involucran expresiones regulares, eliminando casi duplicados, centrándose en respuestas con una gran cantidad de tokens, etc.
- Plantillas de mensajes : no existe una verdadera forma estándar de formatear instrucciones y respuestas, por lo que es importante conocer las diferentes plantillas de chat, como ChatML, Alpaca, etc.
Referencias :
- Preparación de un conjunto de datos para el ajuste de instrucciones por Thomas Capelle: exploración de los conjuntos de datos Alpaca y Alpaca-GPT4 y cómo formatearlos.
- Generación de un conjunto de datos de instrucciones clínicas por Solano Todeschini: tutorial sobre cómo crear un conjunto de datos de instrucciones sintéticas utilizando GPT-4.
- GPT 3.5 para clasificación de noticias por Kshitiz Sahay: use GPT 3.5 para crear un conjunto de datos de instrucciones para ajustar Llama 2 para clasificación de noticias.
- Creación de conjuntos de datos para perfeccionar LLM: cuaderno que contiene algunas técnicas para filtrar un conjunto de datos y cargar el resultado.
- Plantilla de chat de Matthew Carrigan: página de Hugging Face sobre plantillas de mensajes
3. Modelos de preentrenamiento
La formación previa es un proceso muy largo y costoso, por lo que este no es el tema central de este curso. Es bueno tener cierto nivel de comprensión de lo que sucede durante la capacitación previa, pero no se requiere experiencia práctica.
- Canalización de datos : el entrenamiento previo requiere enormes conjuntos de datos (por ejemplo, Llama 2 se entrenó con 2 billones de tokens) que deben filtrarse, tokenizarse y cotejarse con un vocabulario predefinido.
- Modelado de lenguaje causal : conozca la diferencia entre modelado de lenguaje causal y enmascarado, así como la función de pérdida utilizada en este caso. Para una capacitación previa eficiente, obtenga más información sobre Megatron-LM o gpt-neox.
- Leyes de escala : las leyes de escala describen el rendimiento esperado del modelo en función del tamaño del modelo, el tamaño del conjunto de datos y la cantidad de computación utilizada para el entrenamiento.
- Computación de alto rendimiento : fuera de alcance aquí, pero es fundamental tener más conocimientos sobre HPC si planea crear su propio LLM desde cero (hardware, carga de trabajo distribuida, etc.).
Referencias :
- LLMDataHub de Junhao Zhao: lista seleccionada de conjuntos de datos para preentrenamiento, ajuste y RLHF.
- Entrenamiento de un modelo de lenguaje causal desde cero mediante Hugging Face: entrene previamente un modelo GPT-2 desde cero utilizando la biblioteca de transformadores.
- TinyLlama de Zhang et al.: Consulte este proyecto para comprender bien cómo se entrena un modelo Llama desde cero.
- Modelado de lenguaje causal mediante Hugging Face: explique la diferencia entre el modelado de lenguaje causal y enmascarado y cómo ajustar rápidamente un modelo DistilGPT-2.
- Las locas implicaciones de Chinchilla por nostalgebraist: analice las leyes de escala y explique lo que significan para los LLM en general.
- BLOOM by BigScience: Página de Notion que describe cómo se construyó el modelo BLOOM, con mucha información útil sobre la parte de ingeniería y los problemas que se encontraron.
- OPT-175 Logbook by Meta: Registros de investigación que muestran qué salió mal y qué salió bien. Útil si planea entrenar previamente un modelo de lenguaje muy grande (en este caso, 175B parámetros).
- LLM 360: un marco para LLM de código abierto con código, datos, métricas y modelos de capacitación y preparación de datos.
4. Ajuste supervisado
Los modelos previamente entrenados solo se entrenan en una tarea de predicción del siguiente token, por lo que no son asistentes útiles. SFT le permite modificarlos para que respondan a las instrucciones. Además, le permite ajustar su modelo con cualquier dato (privado, no visto por GPT-4, etc.) y usarlo sin tener que pagar por una API como la de OpenAI.
- Ajuste completo : el ajuste completo se refiere al entrenamiento de todos los parámetros del modelo. No es una técnica eficiente, pero produce resultados ligeramente mejores.
- LoRA : una técnica de parámetros eficientes (PEFT) basada en adaptadores de bajo rango. En lugar de entrenar todos los parámetros, solo entrenamos estos adaptadores.
- QLoRA : Otro PEFT basado en LoRA, que también cuantifica los pesos del modelo en 4 bits e introduce optimizadores paginados para gestionar los picos de memoria. Combínelo con Unsloth para ejecutarlo de manera eficiente en una computadora portátil Colab gratuita.
- Axolotl : una herramienta de ajuste potente y fácil de usar que se utiliza en muchos modelos de código abierto de última generación.
- DeepSpeed : entrenamiento previo y ajuste eficiente de LLM para configuraciones de múltiples GPU y múltiples nodos (implementado en Axolotl).
Referencias :
- Guía de formación de LLM para principiantes de Alpin: descripción general de los principales conceptos y parámetros a considerar al perfeccionar los LLM.
- Conocimientos de LoRA por Sebastian Raschka: conocimientos prácticos sobre LoRA y cómo seleccionar los mejores parámetros.
- Ajuste su propio modelo de Llama 2: tutorial práctico sobre cómo ajustar un modelo de Llama 2 utilizando las bibliotecas de Hugging Face.
- Relleno de modelos de lenguaje grandes por Benjamin Marie: mejores prácticas para rellenar ejemplos de capacitación para LLM causales
- Una guía para principiantes sobre el ajuste fino de LLM: tutorial sobre cómo ajustar un modelo CodeLlama usando Axolotl.
5. Alineación de preferencias
Después de un ajuste supervisado, RLHF es un paso que se utiliza para alinear las respuestas del LLM con las expectativas humanas. La idea es aprender las preferencias a partir de la retroalimentación humana (o artificial), que puede usarse para reducir sesgos, censurar modelos o hacerlos actuar de una manera más útil. Es más complejo que SFT y a menudo se considera opcional.
- Conjuntos de datos de preferencia : estos conjuntos de datos suelen contener varias respuestas con algún tipo de clasificación, lo que los hace más difíciles de producir que los conjuntos de datos de instrucciones.
- Optimización de políticas próximas : este algoritmo aprovecha un modelo de recompensa que predice si un texto determinado tiene una alta clasificación entre los humanos. Luego, esta predicción se utiliza para optimizar el modelo SFT con una penalización basada en la divergencia KL.
- Optimización de preferencias directas : DPO simplifica el proceso reformulándolo como un problema de clasificación. Utiliza un modelo de referencia en lugar de un modelo de recompensa (no se necesita capacitación) y solo requiere un hiperparámetro, lo que lo hace más estable y eficiente.
Referencias :
- Distilabel de Argilla: Excelente herramienta para crear tus propios conjuntos de datos. Fue especialmente diseñado para conjuntos de datos de preferencias, pero también puede realizar SFT.
- Introducción a la formación de LLM utilizando RLHF por Ayush Thakur: Explique por qué RLHF es deseable para reducir el sesgo y aumentar el rendimiento en los LLM.
- Ilustración RLHF de Hugging Face: Introducción a RLHF con entrenamiento de modelo de recompensa y ajuste con aprendizaje por refuerzo.
- LLM de ajuste de preferencias mediante Hugging Face: comparación de los algoritmos DPO, IPO y KTO para realizar la alineación de preferencias.
- Formación LLM: RLHF y sus alternativas por Sebastian Rashcka: descripción general del proceso RLHF y alternativas como RLAIF.
- Afinar Mistral-7b con DPO: Tutorial para afinar un modelo Mistral-7b con DPO y reproducir NeuralHermes-2.5.
6. Evaluación
La evaluación de los LLM es una parte infravalorada del proceso, que requiere mucho tiempo y es moderadamente confiable. Su tarea posterior debe dictar lo que desea evaluar, pero recuerde siempre la ley de Goodhart: "Cuando una medida se convierte en un objetivo, deja de ser una buena medida".
- Métricas tradicionales : métricas como la perplejidad y la puntuación BLEU no son tan populares como lo eran porque tienen fallas en la mayoría de los contextos. Todavía es importante comprenderlos y cuándo se pueden aplicar.
- Puntos de referencia generales : basado en el arnés de evaluación del modelo de lenguaje, Open LLM Leaderboard es el punto de referencia principal para los LLM de propósito general (como ChatGPT). Existen otros puntos de referencia populares como BigBench, MT-Bench, etc.
- Puntos de referencia específicos de tareas : tareas como resúmenes, traducción y respuesta a preguntas tienen puntos de referencia, métricas e incluso subdominios dedicados (médicos, financieros, etc.), como PubMedQA para responder preguntas biomédicas.
- Evaluación humana : la evaluación más confiable es la tasa de aceptación por parte de los usuarios o las comparaciones realizadas por humanos. Registrar los comentarios de los usuarios además de los seguimientos del chat (por ejemplo, usando LangSmith) ayuda a identificar áreas potenciales de mejora.
Referencias :
- Perplejidad de los modelos de longitud fija de Hugging Face: descripción general de la perplejidad con el código para implementarlo con la biblioteca de transformadores.
- BLEU bajo su propia responsabilidad por Rachael Tatman: descripción general de la puntuación BLEU y sus numerosos problemas con ejemplos.
- Una encuesta sobre evaluación de LLM de Chang et al .: artículo completo sobre qué evaluar, dónde evaluar y cómo evaluar.
- Tabla de clasificación de Chatbot Arena de lmsys: calificación Elo de LLM de propósito general, basada en comparaciones realizadas por humanos.
7. Cuantización
La cuantización es el proceso de convertir los pesos (y activaciones) de un modelo utilizando una precisión menor. Por ejemplo, los pesos almacenados con 16 bits se pueden convertir en una representación de 4 bits. Esta técnica se ha vuelto cada vez más importante para reducir los costos computacionales y de memoria asociados con los LLM.
- Técnicas básicas : Aprenda los diferentes niveles de precisión (FP32, FP16, INT8, etc.) y cómo realizar una cuantificación ingenua con técnicas absmax y punto cero.
- GGUF y llama.cpp : originalmente diseñados para ejecutarse en CPU, llama.cpp y el formato GGUF se han convertido en las herramientas más populares para ejecutar LLM en hardware de consumo.
- GPTQ y EXL2 : GPTQ y, más concretamente, el formato EXL2 ofrecen una velocidad increíble pero sólo pueden ejecutarse en GPU. Los modelos también tardan mucho en cuantificarse.
- AWQ : este nuevo formato es más preciso que GPTQ (menor perplejidad) pero utiliza mucha más VRAM y no es necesariamente más rápido.
Referencias :
- Introducción a la cuantificación: descripción general de la cuantificación, absmax y cuantificación de punto cero, y LLM.int8() con código.
- Cuantizar modelos Llama con llama.cpp: Tutorial sobre cómo cuantificar un modelo Llama 2 usando llama.cpp y el formato GGUF.
- Cuantización LLM de 4 bits con GPTQ: Tutorial sobre cómo cuantificar un LLM usando el algoritmo GPTQ con AutoGPTQ.
- ExLlamaV2: la biblioteca más rápida para ejecutar LLM: guía sobre cómo cuantificar un modelo Mistral usando el formato EXL2 y ejecutarlo con la biblioteca ExLlamaV2.
- Comprensión de la cuantificación de peso consciente de la activación mediante FriendliAI: descripción general de la técnica AWQ y sus beneficios.
8. Nuevas tendencias
- Incrustaciones posicionales : aprenda cómo los LLM codifican posiciones, especialmente esquemas de codificación posicional relativa como RoPE. Implemente YaRN (multiplica la matriz de atención por un factor de temperatura) o ALiBi (penalización de atención basada en la distancia del token) para ampliar la longitud del contexto.
- Fusión de modelos : la fusión de modelos entrenados se ha convertido en una forma popular de crear modelos de alto rendimiento sin ningún ajuste fino. La popular biblioteca mergekit implementa los métodos de fusión más populares, como SLERP, DARE y TIES.
- Mezcla de expertos : Mixtral volvió a popularizar la arquitectura MoE gracias a su excelente rendimiento. Paralelamente, surgió un tipo de frankenMoE en la comunidad OSS al fusionar modelos como Phixtral, que es una opción más económica y eficaz.
- Modelos multimodales : estos modelos (como CLIP, Stable Diffusion o LLaVA) procesan múltiples tipos de entradas (texto, imágenes, audio, etc.) con un espacio de incrustación unificado, que desbloquea aplicaciones potentes como texto a imagen.
Referencias :
- Extendiendo el RoPE por EleutherAI: Artículo que resume las diferentes técnicas de codificación de posición.
- Comprensión de YaRN por Rajat Chawla: Introducción a YaRN.
- Fusionar LLM con mergekit: tutorial sobre la fusión de modelos usando mergekit.
- Mezcla de expertos explicada por Hugging Face: guía exhaustiva sobre los MoE y cómo funcionan.
- Grandes modelos multimodales de Chip Huyen: descripción general de los sistemas multimodales y la historia reciente de este campo.
? El ingeniero LLM
Esta sección del curso se centra en aprender cómo crear aplicaciones basadas en LLM que puedan usarse en producción, con un enfoque en aumentar modelos e implementarlos.
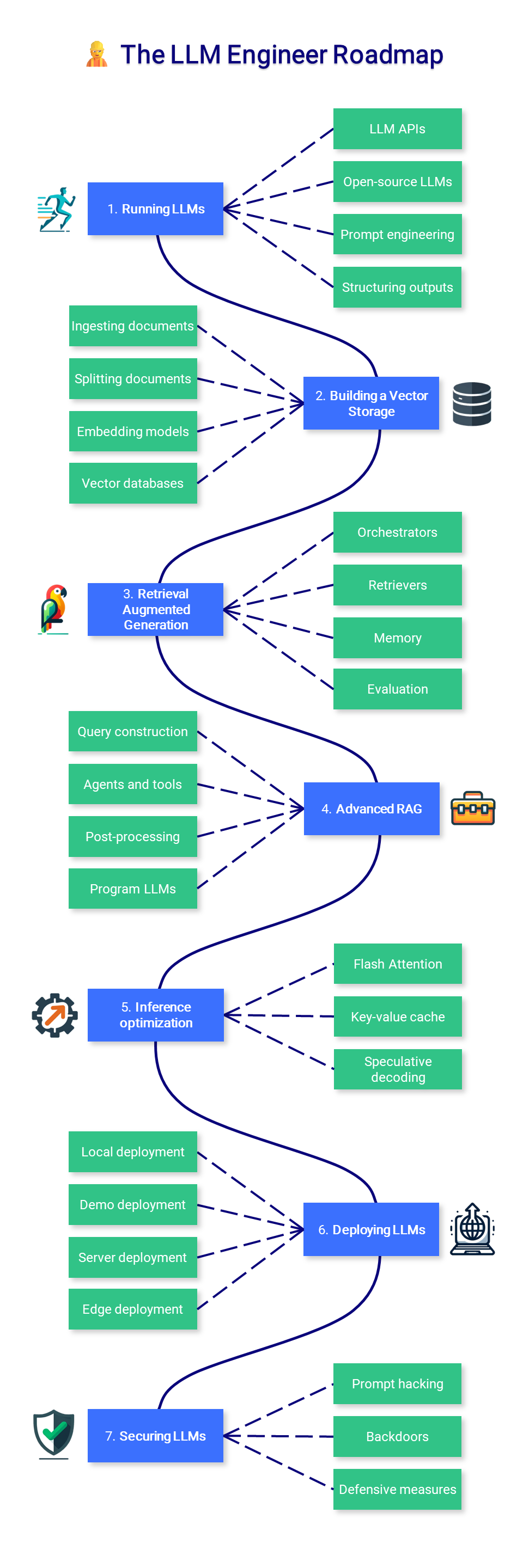
1. Ejecutar LLM
La ejecución de LLM puede resultar difícil debido a los altos requisitos de hardware. Dependiendo de su caso de uso, es posible que desee simplemente consumir un modelo a través de una API (como GPT-4) o ejecutarlo localmente. En cualquier caso, las técnicas adicionales de indicaciones y orientación pueden mejorar y limitar el resultado de sus aplicaciones.
- API de LLM : las API son una forma conveniente de implementar LLM. Este espacio se divide entre LLM privados (OpenAI, Google, Anthropic, Cohere, etc.) y LLM de código abierto (OpenRouter, Hugging Face, Together AI, etc.).
- LLM de código abierto : Hugging Face Hub es un excelente lugar para encontrar LLM. Puede ejecutar algunos de ellos directamente en Hugging Face Spaces, o descargarlos y ejecutarlos localmente en aplicaciones como LM Studio o mediante la CLI con llama.cpp u Ollama.
- Ingeniería de indicaciones : las técnicas comunes incluyen indicaciones de disparo cero, indicaciones de pocos disparos, cadena de pensamiento y ReAct. Funcionan mejor con modelos más grandes, pero se pueden adaptar a los más pequeños.
- Estructurar resultados : muchas tareas requieren un resultado estructurado, como una plantilla estricta o un formato JSON. Se pueden utilizar bibliotecas como LMQL, Outlines, Guidance, etc. para guiar la generación y respetar una estructura determinada.
Referencias :
- Ejecute un LLM localmente con LM Studio de Nisha Arya: guía breve sobre cómo usar LM Studio.
- Guía de ingeniería rápida de DAIR.AI: lista exhaustiva de técnicas rápidas con ejemplos
- Outlines - Inicio rápido: Lista de técnicas de generación guiada habilitadas por Outlines.
- LMQL - Descripción general: Introducción al lenguaje LMQL.
2. Construyendo un almacenamiento de vectores
La creación de un almacenamiento vectorial es el primer paso para construir una canalización de generación aumentada de recuperación (RAG). Los documentos se cargan, dividen y los fragmentos relevantes se utilizan para producir representaciones vectoriales (incrustaciones) que se almacenan para uso futuro durante la inferencia.
- Ingesta de documentos : los cargadores de documentos son contenedores convenientes que pueden manejar muchos formatos: PDF, JSON, HTML, Markdown, etc. También pueden recuperar datos directamente de algunas bases de datos y API (GitHub, Reddit, Google Drive, etc.).
- División de documentos : los divisores de texto dividen los documentos en partes más pequeñas y semánticamente significativas. En lugar de dividir el texto después de n caracteres, suele ser mejor dividirlo por encabezado o de forma recursiva, con algunos metadatos adicionales.
- Modelos de incrustación : los modelos de incrustación convierten el texto en representaciones vectoriales. Permite una comprensión más profunda y matizada del lenguaje, lo cual es esencial para realizar una búsqueda semántica.
- Bases de datos de vectores : las bases de datos de vectores (como Chroma, Pinecone, Milvus, FAISS, Annoy, etc.) están diseñadas para almacenar vectores integrados. Permiten la recuperación eficiente de datos que son "más similares" a una consulta basada en la similitud de vectores.
Referencias :
- LangChain - Divisores de texto: Lista de diferentes divisores de texto implementados en LangChain.
- Biblioteca Sentence Transformers: biblioteca popular para incrustar modelos.
- Tabla de clasificación MTEB: tabla de clasificación para incrustar modelos.
- Las 5 principales bases de datos vectoriales de Moez Ali: una comparación de las mejores y más populares bases de datos vectoriales.
3. Generación aumentada de recuperación
Con RAG, los LLM recuperan documentos contextuales de una base de datos para mejorar la precisión de sus respuestas. RAG es una forma popular de aumentar el conocimiento del modelo sin ningún ajuste.
- Orquestadores : los orquestadores (como LangChain, LlamaIndex, FastRAG, etc.) son marcos populares para conectar sus LLM con herramientas, bases de datos, memorias, etc. y aumentar sus habilidades.
- Recuperadores : las instrucciones del usuario no están optimizadas para su recuperación. Se pueden aplicar diferentes técnicas (por ejemplo, recuperador de consultas múltiples, HyDE, etc.) para reformularlas/ampliarlas y mejorar el rendimiento.
- Memoria : para recordar instrucciones y respuestas anteriores, los LLM y los chatbots como ChatGPT agregan este historial a su ventana contextual. Este búfer se puede mejorar con resumen (por ejemplo, usando un LLM más pequeño), un almacén de vectores + RAG, etc.
- Evaluación : Necesitamos evaluar tanto la recuperación del documento (precisión del contexto y recuperación) como las etapas de generación (fidelidad y relevancia de las respuestas). Se puede simplificar con las herramientas Ragas y DeepEval.
Referencias :
- Llamaindex - Conceptos de alto nivel: Principales conceptos a conocer a la hora de construir oleoductos RAG.
- Pinecone - Aumento de recuperación: descripción general del proceso de aumento de recuperación.
- LangChain - Preguntas y respuestas con RAG: tutorial paso a paso para crear una canalización RAG típica.
- LangChain - Tipos de memoria: Lista de diferentes tipos de memorias con uso relevante.
- Tubería RAG - Métricas: descripción general de las principales métricas utilizadas para evaluar las tuberías RAG.
4. RAG avanzado
Las aplicaciones de la vida real pueden requerir canalizaciones complejas, incluidas bases de datos SQL o gráficas, además de seleccionar automáticamente herramientas y API relevantes. Estas técnicas avanzadas pueden mejorar una solución básica y proporcionar funciones adicionales.
- Construcción de consultas : los datos estructurados almacenados en bases de datos tradicionales requieren un lenguaje de consulta específico como SQL, Cypher, metadatos, etc. Podemos traducir directamente las instrucciones del usuario en una consulta para acceder a los datos con la construcción de consultas.
- Agentes y herramientas : los agentes aumentan los LLM seleccionando automáticamente las herramientas más relevantes para brindar una respuesta. Estas herramientas pueden ser tan simples como usar Google o Wikipedia, o más complejas como un intérprete de Python o Jira.
- Postprocesamiento : Paso final que procesa las entradas que se alimentan al LLM. Mejora la relevancia y diversidad de los documentos recuperados con reclasificación, fusión RAG y clasificación.
- Programa LLM : marcos como DSPy le permiten optimizar indicaciones y ponderaciones basadas en evaluaciones automatizadas de forma programática.
Referencias :
- LangChain - Construcción de consultas: publicación de blog sobre diferentes tipos de construcción de consultas.
- LangChain - SQL: Tutorial sobre cómo interactuar con bases de datos SQL con LLM, involucrando Text-to-SQL y un agente SQL opcional.
- Pinecone - Agentes LLM: Introducción a agentes y herramientas con diferentes tipos.
- Agentes autónomos impulsados por LLM por Lilian Weng: artículo más teórico sobre agentes LLM.
- LangChain - RAG de OpenAI: descripción general de las estrategias RAG empleadas por OpenAI, incluido el posprocesamiento.
- DSPy en 8 pasos: guía general para DSPy que presenta módulos, firmas y optimizadores.
5. Optimización de la inferencia
La generación de texto es un proceso costoso que requiere hardware costoso. Además de la cuantificación, se han propuesto varias técnicas para maximizar el rendimiento y reducir los costos de inferencia.
- Atención Flash : Optimización del mecanismo de atención para transformar su complejidad de cuadrática a lineal, acelerando tanto el entrenamiento como la inferencia.
- Caché de valores clave : comprenda el caché de valores clave y las mejoras introducidas en Atención de consultas múltiples (MQA) y Atención de consultas agrupadas (GQA).
- Decodificación especulativa : utilice un modelo pequeño para producir borradores que luego son revisados por un modelo más grande para acelerar la generación de texto.
Referencias :
- Inferencia de GPU abrazando la cara: explique cómo optimizar la inferencia en GPU.
- Inferencia LLM de Databricks: mejores prácticas sobre cómo optimizar la inferencia LLM en producción.
- Optimización de LLM para velocidad y memoria abrazando la cara: explique tres técnicas principales para optimizar la velocidad y la memoria, a saber, cuantificación, atención flash e innovaciones arquitectónicas.
- Generación asistida por Hugging Face: la versión de decodificación especulativa de HF, es una publicación de blog interesante sobre cómo funciona con el código para implementarlo.
6. Implementación de LLM
La implementación de LLM a escala es una hazaña de ingeniería que puede requerir múltiples grupos de GPU. En otros escenarios, se pueden lograr demostraciones y aplicaciones locales con una complejidad mucho menor.
- Implementación local : la privacidad es una ventaja importante que tienen los LLM de código abierto sobre los privados. Los servidores LLM locales (LM Studio, Ollama, oobabooga, kobold.cpp, etc.) aprovechan esta ventaja para impulsar aplicaciones locales.
- Implementación de demostración : los marcos como Gradio y Streamlit son útiles para prototipos de aplicaciones y compartir demostraciones. También puede alojarlos fácilmente en línea, por ejemplo, usando espacios faciales para abrazar.
- Implementación del servidor : la implementación de LLM a escala requiere la nube (ver también Skypilot) o infraestructura en el premio y a menudo aprovechan marcos de generación de texto optimizados como TGI, VLLM, etc.
- Despliegue de borde : en entornos restringidos, los marcos de alto rendimiento como MLC LLM y MNN-LLM pueden implementar LLM en navegadores web, Android e iOS.
Referencias :
- Streamlit - Cree una aplicación básica de LLM: Tutorial para hacer una aplicación básica similar a ChatGPT usando Streamlit.
- HF LLM Inference Container: Implement LLMS en Amazon Sagemaker usando el contenedor de inferencia de Hugging Face.
- Blog de Philschmid de Philipp Schmid: Colección de artículos de alta calidad sobre la implementación de LLM utilizando Amazon Sagemaker.
- Optimización de la latencia por Hamel Husain: comparación de TGI, VLLM, Ctranslate2 y MLC en términos de rendimiento y latencia.
7. Asegurar LLMS
Además de los problemas de seguridad tradicionales asociados con el software, los LLM tienen debilidades únicas debido a la forma en que son capacitados y solicitados.
- Hackeo de inmediato : diferentes técnicas relacionadas con la ingeniería rápida, incluida la inyección rápida (instrucción adicional para secuestrar la respuesta del modelo), la fuga de datos/indicadores (recuperar sus datos/indicadores originales) y jailbreaking (las indicaciones de manualidades para evitar las características de seguridad).
- Backdoors : los vectores de ataque pueden dirigirse a los datos de entrenamiento en sí, envenenando los datos de entrenamiento (por ejemplo, con información falsa) o creando puertas traseras (desencadenantes secretos para cambiar el comportamiento del modelo durante la inferencia).
- Medidas defensivas : la mejor manera de proteger sus aplicaciones LLM es probarlas contra estas vulnerabilidades (por ejemplo, usar equipo rojo y controles como Garak) y observarlas en producción (con un marco como Langfuse).
Referencias :
- OWASP LLM Top 10 de Hego Wiki: Lista de las 10 vulnerabilidades más críticas que se ven en las aplicaciones LLM.
- Impulsor de inyección de Joseph Thacker: Guía corta dedicada a la inyección rápida para los ingenieros.
- LLM Security by @llm_sec: una amplia lista de recursos relacionados con la seguridad LLM.
- Red Teaming LLM de Microsoft: Guía sobre cómo realizar un equipo rojo con LLMS.
Expresiones de gratitud
Esta hoja de ruta se inspiró en la excelente hoja de ruta DevOps de Milán Milanović y Romano Roth.
Un agradecimiento especial a:
- Thomas Thelen por motivarme a crear una hoja de ruta
- André Frade por su aporte y revisión del primer borrador
- Dino Dunn por proporcionar recursos sobre la seguridad de LLM
- Magdalena Kuhn para mejorar la parte de la "evaluación humana"
- Odoverdose para sugerir el video de 3Blue1Brown sobre Transformers
Descargo de responsabilidad: no estoy afiliado a ninguna fuente enumerada aquí.


