Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang, Onkar Dabeer.
Este repositorio contiene los recursos para nuestro documento ECCV-2022 "Capacitación previa autosupervisada de SPot-the-Difference para la detección y segmentación de anomalías". Actualmente publicamos el conjunto de datos Visual Anomaly (VisA).
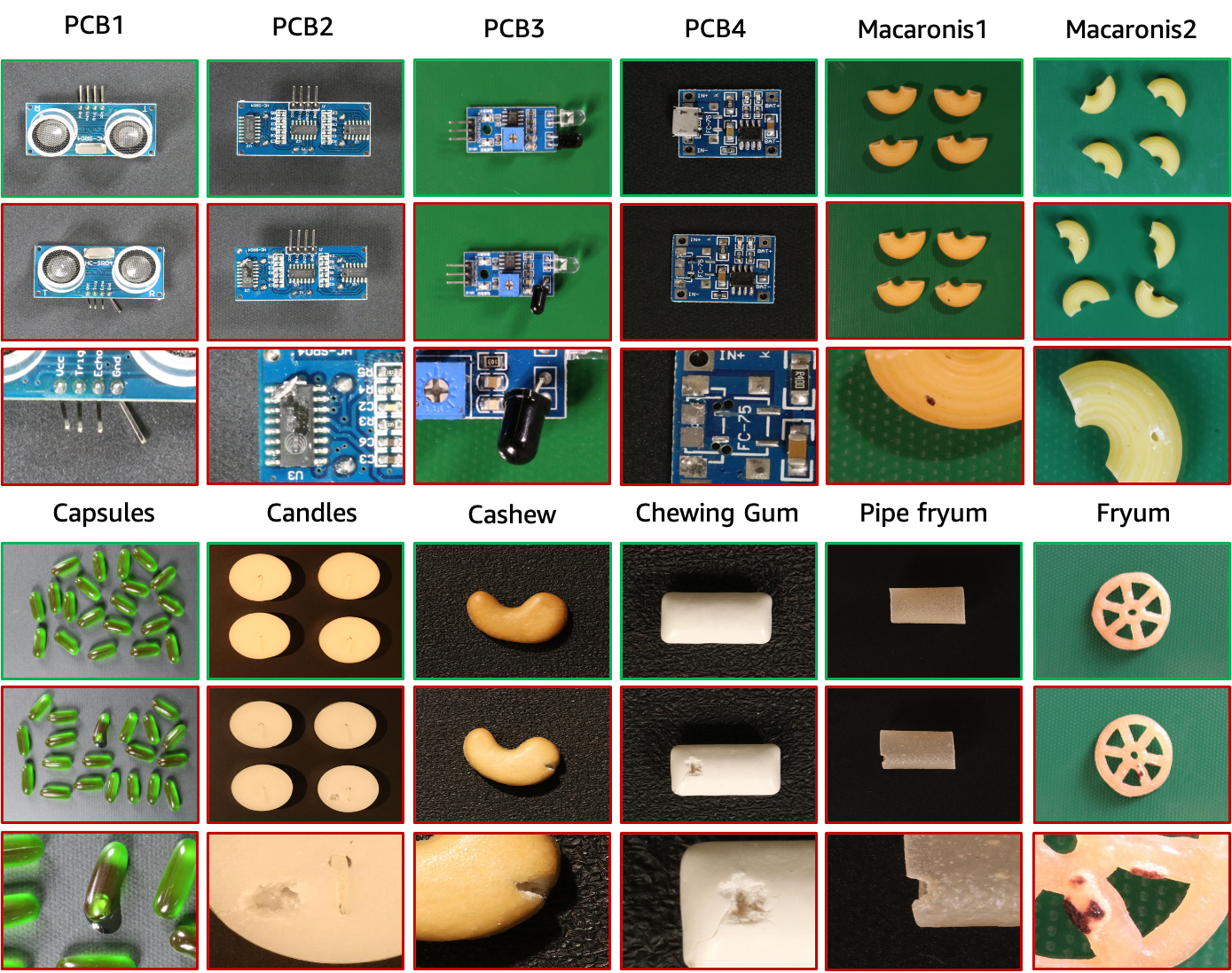
El conjunto de datos VisA contiene 12 subconjuntos correspondientes a 12 objetos diferentes, como se muestra en la figura anterior. Hay 10.821 imágenes con 9.621 muestras normales y 1.200 anómalas. Cuatro subconjuntos son diferentes tipos de placas de circuito impreso (PCB) con estructuras relativamente complejas que contienen transistores, condensadores, chips, etc. Para el caso de múltiples instancias en una vista, recopilamos cuatro subconjuntos: Cápsulas, Velas, Macarrones1 y Macarrones2. Las instancias en Capsules y Macaroni2 difieren en gran medida en ubicaciones y poses. Además, recopilamos cuatro subconjuntos que incluyen Anacardo, Chicle, Fryum y Pipe fryum, donde los objetos están alineados aproximadamente. Las imágenes anómalas contienen varios defectos, incluidos defectos superficiales como rayones, abolladuras, manchas de color o grietas, y defectos estructurales como falta de colocación o piezas faltantes.
| Objeto | # muestras normales | # muestras de anomalías | # clases de anomalías | tipo de objeto |
|---|---|---|---|---|
| PCB1 | 1.004 | 100 | 4 | Estructura compleja |
| PCB2 | 1.001 | 100 | 4 | Estructura compleja |
| PCB3 | 1.006 | 100 | 4 | Estructura compleja |
| PCB4 | 1.005 | 100 | 7 | Estructura compleja |
| Cápsulas | 602 | 100 | 5 | Varias instancias |
| Velas | 1.000 | 100 | 8 | Varias instancias |
| macarrones1 | 1.000 | 100 | 7 | Varias instancias |
| macarrones2 | 1.000 | 100 | 7 | Varias instancias |
| Anacardo | 500 | 100 | 9 | instancia única |
| Goma de mascar | 503 | 100 | 6 | Instancia única |
| freír | 500 | 100 | 8 | Instancia única |
| fritura de pipa | 500 | 100 | 9 | instancia única |
Alojamos el conjunto de datos de VisA en AWS S3 y puede descargarlo mediante esta URL.
El árbol de datos de los datos descargados es el siguiente.
VisA
| -- candle
| ----- | --- Data
| ----- | ----- | ----- Images
| ----- | ----- | -------- | ------ Anomaly
| ----- | ----- | -------- | ------ Normal
| ----- | ----- | ----- Masks
| ----- | ----- | -------- | ------ Anomaly
| ----- | --- image_anno.csv
| -- capsules
| ----- | ----- ...image_annot.csv proporciona una etiqueta a nivel de imagen y una máscara de anotación a nivel de píxel para cada imagen. Las funciones de mapa id2class para máscaras multiclase se pueden encontrar en ./utils/id2class.py Aquí las máscaras para imágenes normales no se almacenan para ahorrar espacio.
Para preparar las configuraciones de 1 clase, 2 clases de alto nivel y 2 clases de pocos puntos descritas en el artículo original, usamos ./utils/prepare_data.py para reorganizar los datos siguiendo los archivos de división de datos en "./split_csv/" . A continuación proporcionamos una línea de comando de ejemplo para la preparación de la configuración de 1 clase.
python ./utils/prepare_data.py --split-type 1cls --data-folder ./VisA --save-folder ./VisA_pytorch --split-file ./split_csv/1cls.csv
El árbol de datos de la configuración reorganizada de 1 clase es el siguiente.
VisA_pytorch
| -- 1cls
| ----- | --- candle
| ----- | ----- | ----- ground_truth
| ----- | ----- | ----- test
| ----- | ----- | ------- | ------- good
| ----- | ----- | ------- | ------- bad
| ----- | ----- | ----- train
| ----- | ----- | ------- | ------- good
| ----- | --- capsules
| ----- | --- ...Específicamente, los datos reorganizados para la configuración de 1 clase siguen el árbol de datos de MVTec-AD. Para cada objeto, los datos tienen tres carpetas:
Tenga en cuenta que las máscaras de segmentación de verdad fundamental de múltiples clases en el conjunto de datos original se reindexan a máscaras binarias donde 0 indica normalidad y 255 indica anomalía.
Además, las configuraciones de 2 clases se pueden preparar de manera similar cambiando los argumentos de prepare_data.py.
Para calcular métricas de clasificación y segmentación, consulte ./utils/metrics.py. Tenga en cuenta que tomamos en cuenta las muestras normales al calcular las métricas de localización. Esto es diferente de algunos de los otros trabajos que ignoran las muestras normales en la localización.
Cite el siguiente artículo si este conjunto de datos ayuda a su proyecto:
@article { zou2022spot ,
title = { SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation } ,
author = { Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar } ,
journal = { arXiv preprint arXiv:2207.14315 } ,
year = { 2022 }
}Los datos se publican bajo la licencia CC BY 4.0.


