Este repositorio contiene código PyTorch para Motif, que capacita a agentes de IA en NetHack con funciones de recompensa derivadas de las preferencias de un LLM.
Motivo: motivación intrínseca a partir de la retroalimentación de la inteligencia artificial
por Martin Klissarov* y Pierluca D'Oro*, Shagun Sodhani, Roberta Raileanu, Pierre-Luc Bacon, Pascal Vincent, Amy Zhang y Mikael Henaff
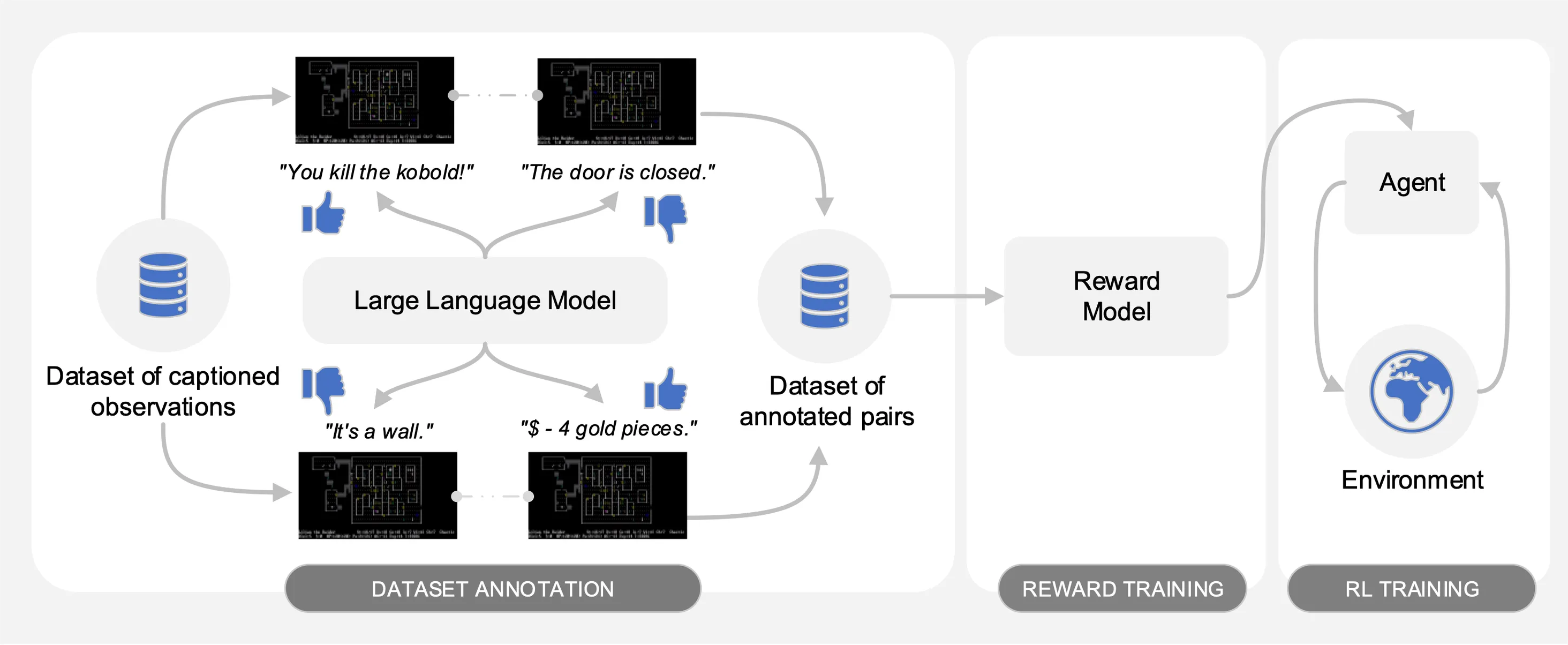
Motif provoca las preferencias de un modelo de lenguaje grande (LLM) sobre pares de observaciones subtituladas de un conjunto de datos de interacciones recopiladas en NetHack. Automáticamente, destila el sentido común del LLM en una función de recompensa que se utiliza para capacitar a los agentes con aprendizaje reforzado.
Para facilitar las comparaciones, proporcionamos curvas de entrenamiento en el archivo pickle motif_results.pkl , que contiene un diccionario con tareas como claves. Para cada tarea, proporcionamos una lista de pasos de tiempo y rendimientos promedio para Motif y líneas de base, para múltiples semillas.
Como se ilustra en la siguiente figura, Motif presenta tres fases:
Detallamos cada una de las fases proporcionando los conjuntos de datos, comandos y resultados brutos necesarios para reproducir los experimentos en el artículo.
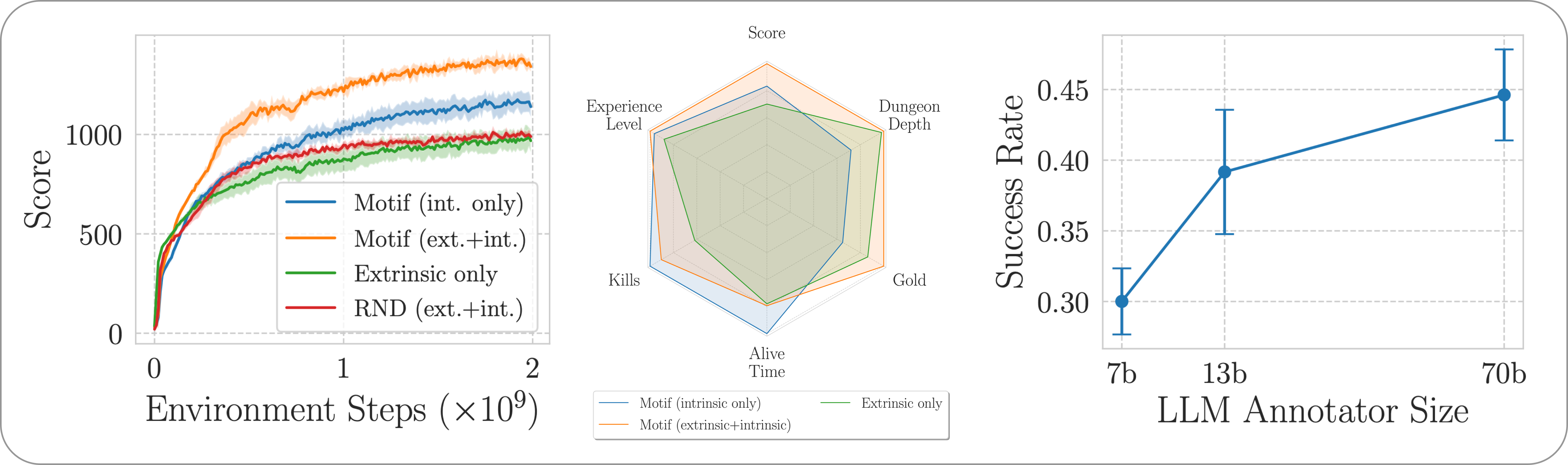
Evaluamos el desempeño de Motif en el desafiante juego NetHack, de final abierto y generado por procedimientos, a través del entorno de aprendizaje NetHack. Investigamos cómo Motif genera principalmente comportamientos intuitivos alineados con los humanos, que pueden controlarse fácilmente mediante modificaciones rápidas, así como sus propiedades de escala.

Para instalar las dependencias requeridas para toda la canalización, simplemente ejecute pip install -r requirements.txt .
Para la primera fase, utilizamos un conjunto de datos de pares de observaciones con leyendas (es decir, mensajes del juego) recopilados por agentes entrenados con aprendizaje por refuerzo para maximizar la puntuación del juego. Proporcionamos el conjunto de datos en este repositorio. Almacenamos las diferentes partes en el directorio motif_dataset_zipped , que se puede descomprimir usando el siguiente comando.
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
El conjunto de datos que proporcionamos presenta un conjunto de preferencias dadas por los modelos Llama 2, contenidas en el directorio preference/ , utilizando las diferentes indicaciones descritas en el artículo. Los nombres de los archivos .npy que contienen las anotaciones siguen la plantilla llama{size}b_msg_{instruction}_{version} , donde size es un tamaño LLM del conjunto {7,13,70} , instruction es una instrucción introducida en el mensaje dado al LLM del conjunto {defaultgoal, zeroknowledge, combat, gold, stairs} , version es la versión de la plantilla de mensaje que se utilizará del conjunto {default, reworded} . Aquí proporcionamos un resumen de las anotaciones disponibles:
| Anotación | Caso de uso del artículo |
|---|---|
llama70b_msg_defaultgoal_default | Experimentos principales |
llama70b_msg_combat_default | Dirigiéndose hacia el comportamiento de The Monster Slayer |
llama70b_msg_gold_default | Dirigiéndose hacia el comportamiento del Coleccionista de Oro |
llama70b_msg_stairs_default | Dirigiéndose hacia el comportamiento descendente |
llama7b_msg_defaultgoal_default | Experimento de escala |
llama13b_msg_defaultgoal_default | Experimento de escala |
llama70b_msg_zeroknowledge_default | Experimento rápido de conocimiento cero |
llama70b_msg_defaultgoal_reworded | Experimento de reformulación rápida |
Para crear las anotaciones utilizamos vLLM y la versión de chat de Llama 2. Si desea generar sus propias anotaciones con Llama 2 o reproducir nuestro proceso de anotación, asegúrese de poder descargar el modelo siguiendo las instrucciones oficiales (puede tardará unos días en tener acceso a los pesos del modelo).
El script de anotación supone que el conjunto de datos se anotará en diferentes fragmentos utilizando el argumento n-annotation-chunks . Esto permite un proceso que se puede paralelizar según la disponibilidad de recursos y es resistente a los reinicios/prevención. Para ejecutar con un solo fragmento (es decir, procesar todo el conjunto de datos) y realizar anotaciones con la plantilla de solicitud predeterminada y la especificación de tarea, ejecute el siguiente comando.
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
Tenga en cuenta que el comportamiento predeterminado reanuda el proceso de anotación agregando las anotaciones al archivo que especifica la configuración, a menos que se indique lo contrario con el indicador --ignore-existing . El nombre del archivo '.npy' que se crea para las anotaciones también se puede seleccionar manualmente utilizando el indicador --custom-annotator-string . Es posible realizar anotaciones utilizando --llm-size 7 y --llm-size 13 utilizando una única GPU con 32 GB de memoria. Puede realizar anotaciones utilizando --llm-size 70 con un nodo de 8 GPU. Aquí proporcionamos estimaciones aproximadas de los tiempos de anotación con GPU NVIDIA V100s 32G, para un conjunto de datos de 100.000 pares, que debería poder reproducir aproximadamente la mayoría de nuestros resultados (que se obtienen con 500.000 pares).
| Modelo | Recursos para anotar |
|---|---|
| Llama 2 7b | ~32 horas de GPU |
| Llama 2 13b | ~40 horas de GPU |
| Llama 2 70b | ~72 horas de GPU |
En la segunda fase, destilamos las preferencias del LLM en una función de recompensa mediante entropía cruzada. Para iniciar el entrenamiento de recompensa con hiperparámetros predeterminados, utilice el siguiente comando.
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
La función de recompensa se entrenará mediante las anotaciones del annotator que se encuentran en --dataset_dir . La función resultante se guardará en train_dir en la subcarpeta --experiment .
Finalmente, entrenamos a un agente con las funciones de recompensa resultantes mediante aprendizaje por refuerzo. Para capacitar a un agente en la tarea NetHackScore-v1 , con los hiperparámetros predeterminados empleados para experimentos que combinan recompensas intrínsecas y extrínsecas, puede utilizar el siguiente comando.
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
Para cambiar la tarea, simplemente modifique el argumento --root_env . La siguiente tabla establece explícitamente los valores necesarios para hacer coincidir los experimentos presentados en el artículo. La tarea NetHackScore-v1 se aprende con el valor extrinsic_reward de 0.1 , mientras que todas las demás tareas toman un valor de 10.0 , para incentivar al agente a alcanzar el objetivo.
| Ambiente | root_env |
|---|---|
| puntaje | NetHackScore-v1 |
| escalera | NetHackStaircase-v1 |
| escalera (nivel 3) | NetHackStaircaseLvl3-v1 |
| escalera (nivel 4) | NetHackStaircaseLvl4-v1 |
| oráculo | NetHackOracle-v1 |
| oráculo-sobrio | NetHackOracleSober-v1 |
Además, si desea capacitar a los agentes utilizando únicamente la recompensa intrínseca proveniente del LLM pero ninguna recompensa del entorno, simplemente configure --extrinsic_reward 0.0 . En los experimentos de recompensa intrínseca únicamente, terminamos el episodio sólo si el agente muere, en lugar de cuando el agente alcanza la meta. Estos entornos modificados se enumeran en la siguiente tabla.
| Ambiente | root_env |
|---|---|
| escalera (nivel 3) - solo intrínseca | NetHackStaircaseLvl3Continual-v1 |
| escalera (nivel 4) - solo intrínseca | NetHackStaircaseLvl4Continual-v1 |
Además, proporcionamos un script para visualizar a sus agentes RL capacitados. Esto puede proporcionar información importante sobre su comportamiento, pero también generará los mensajes principales para cada episodio, lo que puede ayudar a comprender para qué está tratando de optimizar. Simplemente necesita ejecutar el siguiente comando.
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
Si se basa en nuestro trabajo o lo encuentra útil, cítelo utilizando el siguiente bibtex.
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
La mayor parte de Motif tiene licencia CC-BY-NC, sin embargo, partes del proyecto están disponibles bajo términos de licencia separados: sample-factory tiene licencia bajo la licencia MIT.


