
Unifique los datos en todo su ciclo de vida de aprendizaje automático con Space , una solución de almacenamiento integral que maneja sin problemas los datos desde la ingesta hasta el entrenamiento.
Características clave:
space.core.schema.types.files ).space.TfFeatures es un tipo de campo integrado que proporciona serializadores para dictados anidados de matrices numerosas, basado en TFDS FeaturesDict.Instalar:
pip install space-datasetsO instalar desde el código:
cd python
pip install .[dev]Consulte el documento de configuración y rendimiento.
Cree un conjunto de datos de espacio con dos campos de índice ( id , image_name ) (almacenar en Parquet) y un campo de registro ( feature ) (almacenar en ArrayRecord).
Este ejemplo utiliza el tipo binary simple para el campo de registro. Space admite un tipo space.TfFeatures que se integra con el serializador de funciones TFDS. Vea más detalles en un ejemplo de TFDS.
import pyarrow as pa
from space import Dataset
schema = pa . schema ([
( "id" , pa . int64 ()),
( "image_name" , pa . string ()),
( "feature" , pa . binary ())])
ds = Dataset . create (
"/path/to/<mybucket>/example_ds" ,
schema ,
primary_keys = [ "id" ],
record_fields = [ "feature" ]) # Store this field in ArrayRecord files
# Load the dataset from files later:
ds = Dataset . load ( "/path/to/<mybucket>/example_ds" ) Opcionalmente, puede utilizar catalogs para administrar conjuntos de datos por nombres en lugar de ubicaciones:
from space import DirCatalog
# DirCatalog manages datasets in a directory.
catalog = DirCatalog ( "/path/to/<mybucket>" )
# Same as the creation above.
ds = catalog . create_dataset ( "example_ds" , schema ,
primary_keys = [ "id" ], record_fields = [ "feature" ])
# Same as the load above.
ds = catalog . dataset ( "example_ds" )
# List all datasets and materialized views.
print ( catalog . datasets ())Agregar, eliminar algunos datos. Cada mutación genera una nueva versión de los datos, representada por un ID entero creciente. Los usuarios pueden agregar etiquetas a los ID de versión como alias.
import pyarrow . compute as pc
from space import RayOptions
# Create a local runner:
runner = ds . local ()
# Or create a Ray runner:
runner = ds . ray ( ray_options = RayOptions ( max_parallelism = 8 ))
# To avoid https://github.com/ray-project/ray/issues/41333, wrap the runner
# with @ray.remote when running in a remote Ray cluster.
#
# @ray.remote
# def run():
# return runner.read_all()
#
# Appending data generates a new dataset version `snapshot_id=1`
# Write methods:
# - append(...): no primary key check.
# - insert(...): fail if primary key exists.
# - upsert(...): overwrite if primary key exists.
ids = range ( 100 )
runner . append ({
"id" : ids ,
"image_name" : [ f" { i } .jpg" for i in ids ],
"feature" : [ f"somedata { i } " . encode ( "utf-8" ) for i in ids ]
})
ds . add_tag ( "after_append" ) # Version management: add tag to snapshot
# Deletion generates a new version `snapshot_id=2`
runner . delete ( pc . field ( "id" ) == 1 )
ds . add_tag ( "after_delete" )
# Show all versions
ds . versions (). to_pandas ()
# >>>
# snapshot_id create_time tag_or_branch
# 0 2 2024-01-12 20:23:57+00:00 after_delete
# 1 1 2024-01-12 20:23:38+00:00 after_append
# 2 0 2024-01-12 20:22:51+00:00 None
# Read options:
# - filter_: optional, apply a filter (push down to reader).
# - fields: optional, field selection.
# - version: optional, snapshot_id or tag, time travel back to an old version.
# - batch_size: optional, output size.
runner . read_all (
filter_ = pc . field ( "image_name" ) == "2.jpg" ,
fields = [ "feature" ],
version = "after_add" # or snapshot ID `1`
)
# Read the changes between version 0 and 2.
for change in runner . diff ( 0 , "after_delete" ):
print ( change . change_type )
print ( change . data )
print ( "===============" )Cree una nueva rama y realice cambios en la nueva rama:
# The default branch is "main"
ds . add_branch ( "dev" )
ds . set_current_branch ( "dev" )
# Make changes in the new branch, the main branch is not updated.
# Switch back to the main branch.
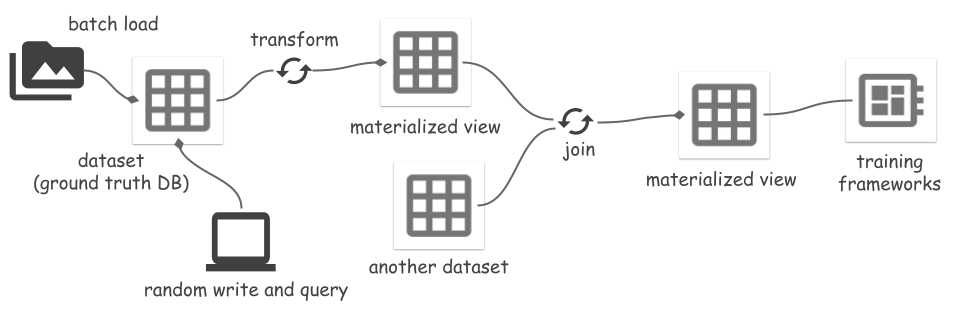
ds . set_current_branch ( "main" )Space admite la transformación de un conjunto de datos en una vista y la materialización de la vista en archivos. Las transformaciones incluyen:
Cuando se modifica el conjunto de datos de origen, la actualización de la vista materializada sincroniza incrementalmente los cambios, lo que ahorra costos de computación y de E/S. Vea más detalles en un ejemplo de Segmentar cualquier cosa. Las vistas de lectura o actualización deben ser el corredor Ray , porque se implementan en función de la transformación de Ray.
Una vista materializada mv se puede utilizar como vista mv.view o conjunto de datos mv.dataset . El primero siempre lee datos de los archivos del conjunto de datos de origen y procesa todos los datos sobre la marcha. Este último lee directamente los datos procesados de los archivos del MV y omite el procesamiento de datos.
# A sample transform UDF.
# Input is {"field_name": [values, ...], ...}
def modify_feature_udf ( batch ):
batch [ "feature" ] = [ d + b"123" for d in batch [ "feature" ]]
return batch
# Create a view and materialize it.
view = ds . map_batches (
fn = modify_feature_udf ,
output_schema = ds . schema ,
output_record_fields = [ "feature" ]
)
view_runner = view . ray ()
# Reading a view will read the source dataset and apply transforms on it.
# It processes all data using `modify_feature_udf` on the fly.
for d in view_runner . read ():
print ( d )
mv = view . materialize ( "/path/to/<mybucket>/example_mv" )
# Or use a catalog:
# mv = catalog.materialize("example_mv", view)
mv_runner = mv . ray ()
# Refresh the MV up to version tag `after_add` of the source.
mv_runner . refresh ( "after_add" , batch_size = 64 ) # Reading batch size
# Or, mv_runner.refresh() refresh to the latest version
# Use the MV runner instead of view runner to directly read from materialized
# view files, no data processing any more.
mv_runner . read_all ()Vea un ejemplo completo en el ejemplo Segmentar cualquier cosa. Aún no se admite la creación de una vista materializada del resultado de la unión.
# If input is a materialized view, using `mv.dataset` instead of `mv.view`
# Only support 1 join key, it must be primary key of both left and right.
joined_view = mv_left . dataset . join ( mv_right . dataset , keys = [ "id" ])Hay varias formas de integrar el almacenamiento espacial con los marcos de aprendizaje automático. Space proporciona una fuente de datos de acceso aleatorio para leer datos en archivos ArrayRecord:
from space import RandomAccessDataSource
datasource = RandomAccessDataSource (
# <field-name>: <storage-location>, for reading data from ArrayRecord files.
{
"feature" : "/path/to/<mybucket>/example_mv" ,
},
# Don't auto deserialize data, because we store them as plain bytes.
deserialize = False )
len ( datasource )
datasource [ 2 ]Un conjunto de datos o una vista también se puede leer como un conjunto de datos de Ray:
ray_ds = ds . ray_dataset ()
ray_ds . take ( 2 )Los datos de los archivos Parquet se pueden leer como un conjunto de datos de HuggingFace:
from datasets import load_dataset
huggingface_ds = load_dataset ( "parquet" , data_files = { "train" : ds . index_files ()})Enumere la ruta del archivo de todos los archivos de índice (Parquet):
ds . index_files ()
# Or show more statistics information of Parquet files.
ds . storage . index_manifest () # Accept filter and snapshot_idMostrar información estadística de todos los archivos ArrayRecord:
ds . storage . record_manifest () # Accept filter and snapshot_id Space es un nuevo proyecto en desarrollo activo.
? Tareas en curso:
Este no es un producto de Google con soporte oficial.


