

MPIRE , abreviatura de MultiProcessing Is Really Easy, es un paquete de Python para multiprocesamiento. MPIRE es más rápido en la mayoría de los escenarios, incluye más funciones y, en general, es más fácil de usar que el paquete de multiprocesamiento predeterminado. Combina las convenientes funciones tipo mapa del multiprocessing.Pool con los beneficios de usar objetos compartidos de copia en escritura del multiprocessing.Process , junto con estados de trabajo fáciles de usar, conocimientos de los trabajadores, funciones de inicio y salida de los trabajadores, tiempos de espera y Funcionalidad de la barra de progreso.
La documentación completa está disponible en https://sybrenjansen.github.io/mpire/.
map / map_unordered / imap / imap_unordered / apply / apply_asyncfork )rich y de cuaderno)daemonMPIRE se prueba en Linux, macOS y Windows. Para los usuarios de Windows y macOS, existen algunas advertencias menores conocidas, que se documentan en el capítulo Solución de problemas.
A través de pip (PyPi):
pip install mpireMPIRE también está disponible a través de conda-forge:
conda install -c conda-forge mpire Suponga que tiene una función que requiere mucho tiempo y recibe alguna entrada y devuelve sus resultados. Funciones simples como estas se conocen como problemas vergonzosamente paralelos, funciones que requieren poco o ningún esfuerzo para convertirse en una tarea paralela. Paralelizar una función simple como esta puede ser tan fácil como importar multiprocessing y usar la clase multiprocessing.Pool :
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) MPIRE se puede utilizar casi como un reemplazo directo del multiprocessing . Usamos la clase mpire.WorkerPool y llamamos a una de las funciones map disponibles:
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) Las diferencias en el código son pequeñas: no es necesario aprender una sintaxis de multiprocesamiento completamente nueva si está acostumbrado al multiprocessing básico. Sin embargo, la funcionalidad adicional disponible es lo que distingue a MPIRE.
Supongamos que queremos saber el estado de la tarea actual: ¿cuántas tareas se han completado y cuánto tiempo falta para que el trabajo esté listo? Es tan simple como configurar el parámetro progress_bar en True :
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )Y generará una barra de progreso tqdm muy bien formateada.
MPIRE también ofrece un panel, para el cual necesita instalar dependencias adicionales. Consulte Panel de control para obtener más información.
Nota: La copia en escritura de objetos compartidos solo está disponible para el método de inicio fork . Para threading los objetos se comparten tal cual. Para otros métodos de inicio, los objetos compartidos se copian una vez para cada trabajador, lo que aún puede ser mejor que una vez por tarea.
Si tiene uno o más objetos que desea compartir entre todos los trabajadores, puede utilizar la opción copiar en escritura shared_objects de MPIRE. MPIRE transmitirá estos objetos solo una vez por cada trabajador sin copiarlos ni serializarlos. Solo cuando modifique el objeto en la función de trabajador, comenzará a copiarlo para ese trabajador.
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )Consulte objetos_compartidos para obtener más detalles.
Los trabajadores se pueden inicializar utilizando la función worker_init . Junto con worker_state puedes cargar un modelo, o configurar una conexión a la base de datos, etc.:
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init ) De manera similar, puede usar la función worker_exit para permitir que MPIRE llame a una función cada vez que un trabajador termina. Incluso puede dejar que esta función de salida devuelva resultados, que se pueden obtener más adelante. Consulte la sección trabajador_init y trabajador_exit para obtener más información.
Cuando su configuración de multiprocesamiento no funciona como desea y no tiene idea de qué lo está causando, existe la funcionalidad de información del trabajador. Esto le dará una idea de su configuración, pero no perfilará la función que está ejecutando (hay otras bibliotecas para eso). En cambio, perfila el tiempo de inicio, el tiempo de espera y el tiempo de trabajo del trabajador. Cuando se proporcionen las funciones de inicio y salida del trabajador, también se cronometrarán.
Quizás esté enviando muchos datos a través de la cola de tareas, lo que aumenta el tiempo de espera. Cualquiera que sea el caso, puede habilitar y obtener información utilizando el indicador enable_insights y la función mpire.WorkerPool.get_insights , respectivamente:
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()Consulte las opiniones de los trabajadores para ver un ejemplo más detallado y el resultado esperado.
Los tiempos de espera se pueden establecer por separado para las funciones de destino, worker_init y worker_exit . Cuando se establece y alcanza un tiempo de espera, se generará un TimeoutError :
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 ) Al utilizar threading como método de inicio, MPIRE no podrá interrumpir ciertas funciones, como time.sleep .
Consulte los tiempos de espera para obtener más detalles.
MPIRE se ha evaluado en tres puntos de referencia diferentes: cálculo numérico, cálculo con estado e inicialización costosa. Se pueden encontrar más detalles sobre estos puntos de referencia en esta publicación de blog. Todo el código para estos puntos de referencia se puede encontrar en este proyecto.
En definitiva, las principales razones por las que MPIRE es más rápido son:
fork está disponible, podemos utilizar objetos compartidos de copia en escritura, lo que reduce la necesidad de copiar objetos que deben compartirse entre procesos secundarios.El siguiente gráfico muestra los resultados normalizados promedio de los tres puntos de referencia. Los resultados de los puntos de referencia individuales se pueden encontrar en la publicación del blog. Las pruebas se ejecutaron en una máquina Linux con 20 núcleos, con hyperthreading deshabilitado y 200 GB de RAM. Para cada tarea, se realizaron experimentos con diferentes números de procesos/trabajadores y los resultados se promediaron en 5 ejecuciones.
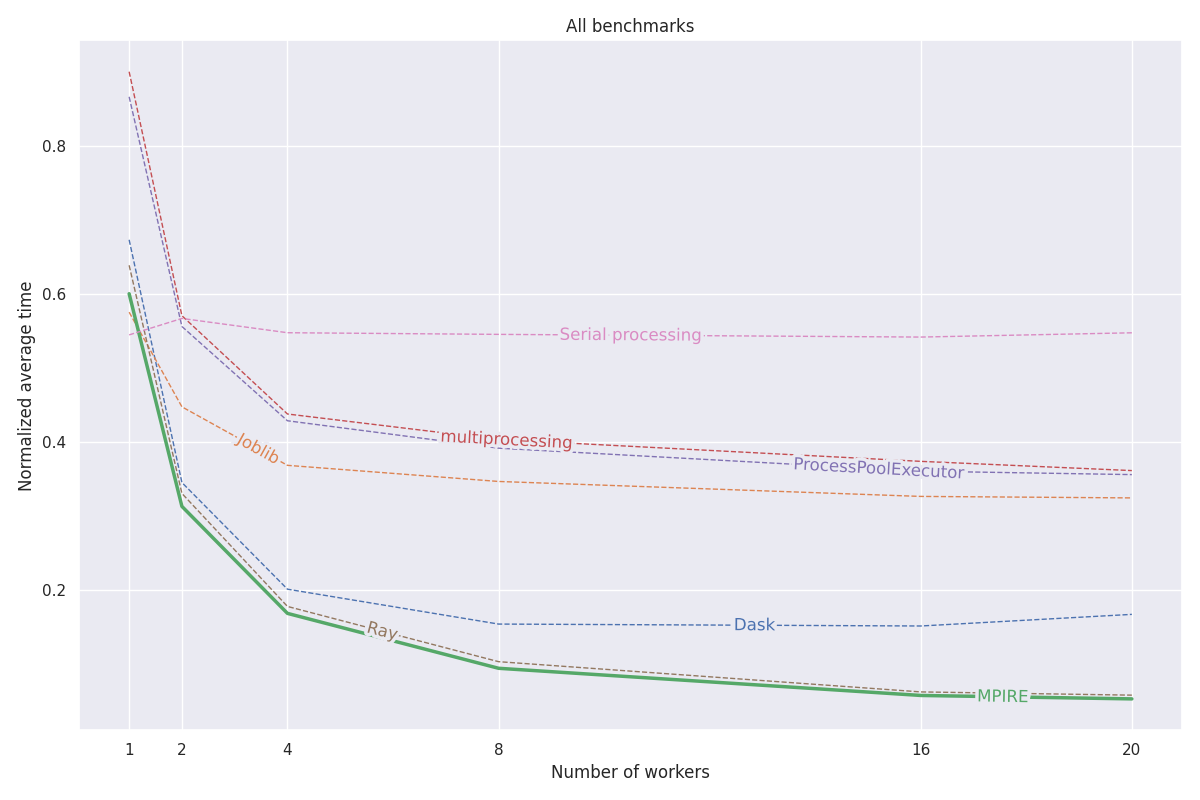
Consulte la documentación completa en https://sybrenjansen.github.io/mpire/ para obtener información sobre todas las demás funciones de MPIRE.
Si desea crear la documentación usted mismo, instale las dependencias de la documentación ejecutando:
pip install mpire[docs]o
pip install .[docs]Luego se puede crear la documentación utilizando Python <= 3.9 y ejecutando:
python setup.py build_docs La documentación también se puede crear directamente desde la carpeta docs . En ese caso, MPIRE debería estar instalado y disponible en su entorno de trabajo actual. Luego ejecuta:
make html en la carpeta de docs .


